
新智元报道
编辑:LRST
来自浙江大学和伊利诺伊大学厄巴纳-香槟分校的研究者发表了他们关于「表格语言模型」(Tabular Language Model)的研究成果,提出「相对量纲分词」和「特征内注意力机制」两种适配技术,使现有语言模型架构能更有效得感知连续数值和组织表格特征,在大量下游分类回归的表格预测数据集上超过以往非语言模型方法。论文「Making Pre-trained Language Models Great on Tabular Prediction」发表在 ICLR 2024 并被选为 Spotlight。
深度神经网络(DNN)的迁移学习能力已经在非结构化数据中取得了广泛应用,然而这种迁移红利在结构化的表格数据中仍未得到充分探索。
相比图像、文本和语音,表格数据的基本特征是异质的,不同列的值位于完全不同的特征空间,这为构建可迁移的表格模型带来了根本性的挑战。
在如今的 AIGC 浪潮下,大语言模型(LLM)可以通过强大的上下文学习(in-context learning)能力执行复杂高层次的推理和规划,因此研究者认为这种文本迁移能力也可以用于规避表格异质特征带来的迁移障碍。
例如在上游预训练中,LM 学习到「gender」和「male/female」特征键值对的模式,可以自然迁移到下游的「sex」和「man/woman」上。这些特征名和离散值可以天然通过文本表示来类比。然而,连续数值同样是表格特征值的一大数据形式
由于设计初衷是为了建模文本生成(language modeling),现代 LM 在处理连续数值计算的任务时仍然力不从心。例如在算术题任务中,即便是参数量惊人的 LLM,在面对稍微复杂的多操作数数学运算时也难以获得足以落地的表现 [1]。
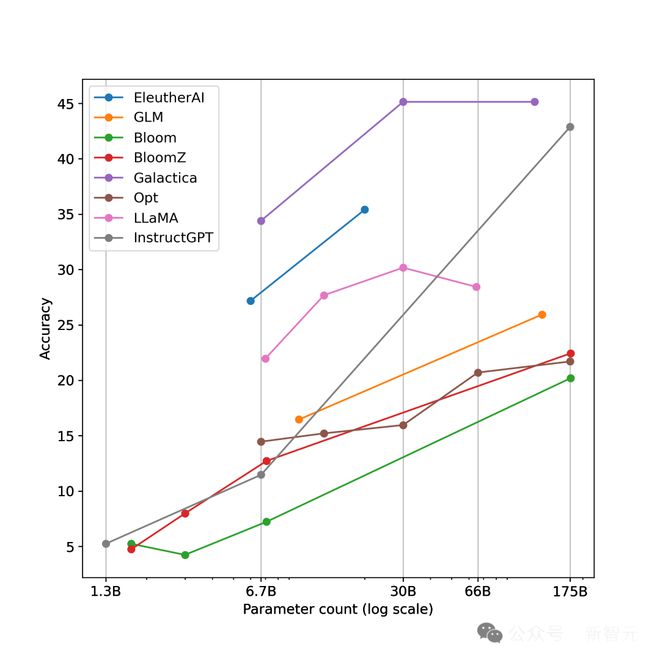
一些不同规模的 LLM 在算术数据集 MATH 401 上的准确率均未超过 50% [1]
这种缺陷同样适用于表格的分类回归预测中,这类机器学习任务需要模型建立数值特征与目标之间的统计关联,因而要求模型能感知连续数值,并理解不同相对大小数值的含义。
以诊断高血压为例,将血压数值以纯文本形式传递给 LLM,LLM 可以粗粒度感知血压是否偏高,但在实际临床实践中,高血压作为一种心血管疾病的关键指征,通常需进一步细粒度区分其是否为高血压前期、1 期还是 2 期,才能提供更精确的综合诊断,而采用纯文本表示连续数值通常是不敏感的。
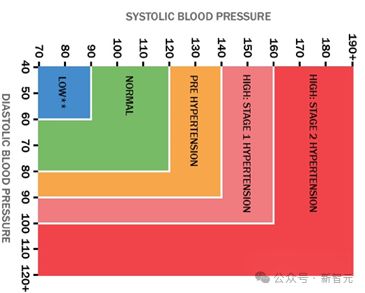
不同血压范围的细粒度临床分类标准
基于上述思路,研究者们提出了一种针对表格连续数值的「相对量纲分词」技术(relative magnitude tokenization, RMT),旨在将连续值的相对大小嵌入为文本空间的词向量,来对不同值域的数值进行离散的分布式表征。

论文地址:https://openreview.net/pdf?id=anzIzGZuLi
代码地址:https://github.com/jyansir/tp-berta
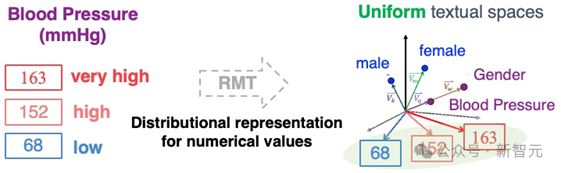
类比词向量将不同值域的血压值进行分布式表征的 RMT 过程
在实现上,论文根据数据集的分类/回归目标,对每个连续特征单独拟合一个 CART 决策树,根据决策树分割特征空间的特性,将值域分割成不同区间,从而完成连续值的离散化过程。
具体来说,数据集的训练样本被 CART 树划分到 256 个叶子节点,叶子节点的分割点即为区间边界值,从而在预测时将任意数值划分到 256 个数值桶(numerical bin)中的一个,而这些数值桶对应语言模型新增的 256 个词向量。这些额外词向量被所有连续特征共享,进而实现数值相对大小的迁移。
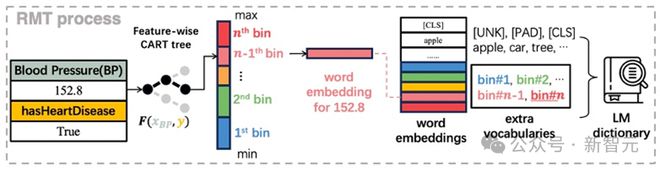
RMT 实现图解:决策树分割空间+额外的共享词向量表示不同区间的数值

在 80 个二分类下游数据集中,RMT 相比将数值当纯文本表示 AUC 平均提升 12.45%,相比将数值乘以特征名词向量的做法平均提升 3.44%
由于表格预测结果不受特征顺序的影响,因此研究者们提出「特征内注意力机制」(Intra-Feature Attention, IFA)。现有的 LM 架构都具备位置编码技术,使得单纯的特征拼接式输入需要乱序,即训练多个不同特征顺序的副本减少 LM 中位置编码的干扰。
而 IFA 则基于「单个特征内有序,特征间无序」的原则,在进一步减少算量的同时,提供更合理的表格上下文。
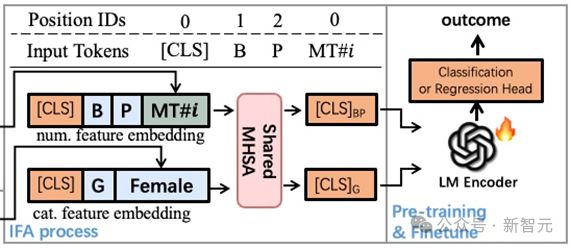
IFA 实现图解:各特征内 token 保留位置编码融合成单独向量进入 LM 编码器
具体来说,每个特征内部存在特征名-值的文本顺序,因此 IFA 对单个特征内保留位置编码,经共享的多头注意力模块将信息汇总到单个[CLS]向量中,再进一步将各特征的向量传递给 LM 编码最终信息。
IFA 既保留特征内的文本顺序,又避免特征间顺序依赖,同时减少实际输入 LM 的 token 数量,在减少算量同时提供更合理的表格上下文机制。

移除 IFA 机制增加 32% 的训练时间并在 80 个二分类下游数据集上平均降低 4.17% 的 AUC
论文在 RoBERTa-base 基础上验证了 RMT 和 IFA 适配方法的有效性,基于 OpenTabs[2]中的表格预测数据集,选用其中 202 个二分类和回归上游任务进行预训练获得 TP-BERTa。
在 145 个二分类和回归下游任务上的微调结果表明,TP-BERTa 在默认超参数下,可以超越经过调参后的非 LM 表格 DNN,并且和传统调参后的 GBDT 相当。
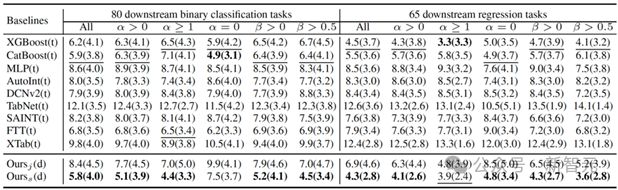
RMT 和 IFA 适配后的 TP-BERTa 在下游测试中超过主流传统表格预测模型
论文进一步分析基于 LM 的表格模型对表格特征性质的偏好,采用离散特征数量比例和夏普利值之和比(所有离散特征夏普利值之和与所有特征夏普利值之和的比值),发现当离散特征越占主导地位,TP-BERTa 在此类数据集上的优势越稳定。
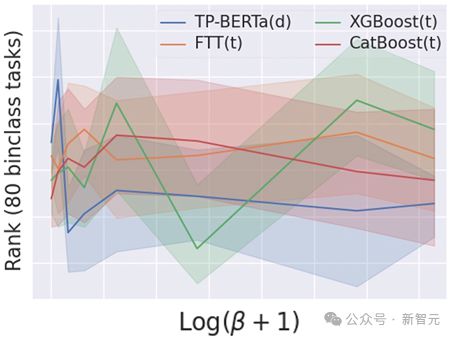
TP-BERTa 在离散特征占主导地位的数据集中表现出稳定优势
最后论文进行了迁移性效果评估,通过与随机初始化和 RoBERTa 权重的模型比较,在 80 个下游二分类任务中,预训练后的权重为 TP-BERTa 带来了平均 3.16% 和 2.79% 的 AUC 提升,表明了对 LM 进行表格预测预训练的有效性,以及语言模型本身的文本预训练对表格预测任务有一定增益。

经过预训练的 TP-BERTa 对比随机初始化和 RoBERTa 权重的版本
参考资料:
[1] How well do Large Language Models perform in Arithmetic tasks? https://arxiv.org/abs/2304.02015
[2] Towards Cross-Table Masked Pretraining for Web Data Mining[C] WWW 2024. https://arxiv.org/abs/2307.04308






