
蔚明投稿自凹非寺
量子位公众号 QbitAI
Transformer 很强,Transformer 很好,但 Transformer 在处理时序数据时存在一定的局限性。
如计算复杂度高、对长序列数据处理不够高效等问题。
而在数据驱动的时代,时序预测成为许多领域中不可或缺的一部分。
于是乎,蚂蚁同清华联合推出一种纯 MLP 架构的模型 TimeMixer,在时序预测上的性能和效能两方面全面超越了 Transformer 模型。

他们结合对时序趋势周期特性的分解以及多尺度混合的设计模式,不仅在长短程预测性能上大幅提升,而且基于纯 MLP 架构实现了接近于线性模型的极高效率。
来康康是如何做到的?
纯 MLP 架构超越 Transformer
TimeMixer 模型采用了一个多尺度混合架构,旨在解决时间序列预测中的复杂时间变化问题。
该模型主要采用全 MLP(多层感知机)架构,由过去可分解混合 Past Decomposable Mixing (PDM) 和未来多预测器混合 Future Multipredictor Mixing (FMM) 两大块构成,能够有效利用多尺度序列信息。
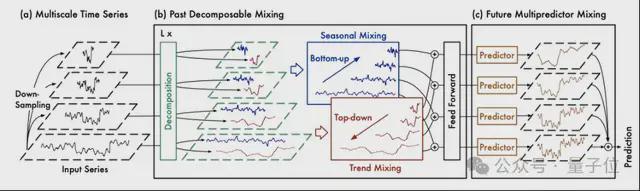
其中 PDM 模块,负责提取过去的信息并将不同尺度上的季节性和趋势组分分别混合。
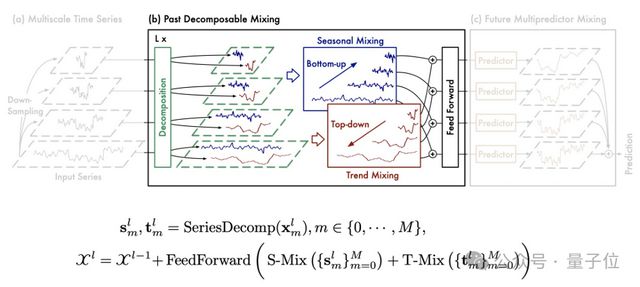
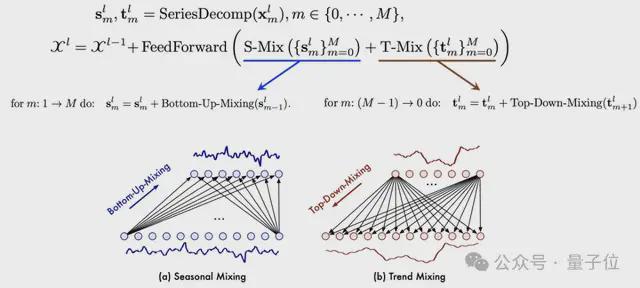
PDM 以季节和趋势混合为动力,将详细的季节信息由细到粗逐步聚合,并利用较粗尺度的先验知识深入挖掘宏观趋势信息,最终实现过去信息提取中的多尺度混合。
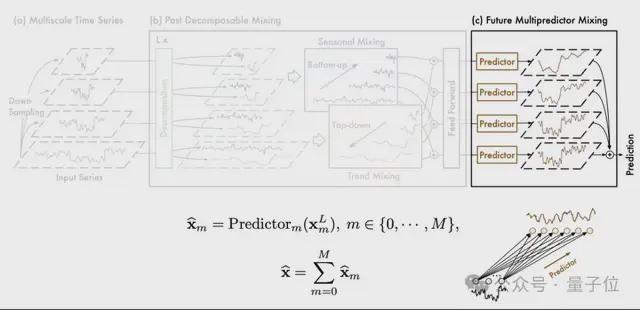
FMM 则是多个预测器的集合,其中不同的预测器基于不同尺度的过去信息,使 FMM 能够集成混合多尺度序列的互补预测功能。
实验效果
为了验证 TimeMixer 的性能,团队在包含长程预测,短程预测,多元时序预测以及具有时空图结构的 18 组基准数据集上进行了实验,包括电力负荷预测、气象数据预测和股票价格预测等。
实验结果表明,TimeMixer 在多个指标上全面超越了当前最先进的 Transformer 模型,具体表现如下:
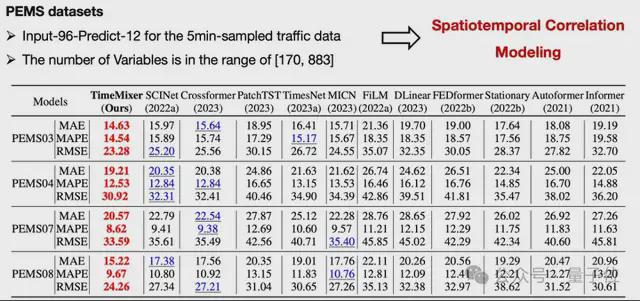
预测精度:在所有测试的数据集上,TimeMixer 均表现出更高的预测精度。以电力负荷预测为例,TimeMixer 相比于 Transformer 模型,平均绝对误差(MAE)降低了约 15%,均方根误差(RMSE)降低了约 12%。
计算效率:得益于 MLP 结构的高效计算特性,TimeMixer 在训练时间和推理时间上均显著优于 Transformer 模型。实验数据显示,在相同硬件条件下,TimeMixer 的训练时间减少了约 30%,推理时间减少了约 25%。
模型可解释性:通过引入 Past Decomposable Mixing 和 Future Multipredictor Mixing 技术,TimeMixer 能够更好地解释不同时间尺度上的信息贡献,使得模型的决策过程更加透明和易于理解。
泛化能力:在多个不同类型的数据集上进行测试,TimeMixer 均表现出良好的泛化能力,能够适应不同的数据分布和特征。这表明 TimeMixer 在实际应用中具有广泛的适用性。
长程预测:为了确保模型比较的公平性,使用标准化参数进行实验,调整输入长度、批量大小和训练周期。此外,鉴于各种研究的结果通常源于超参数优化,该研究还包括了综合参数搜索的结果。

短程预测:多变量数据
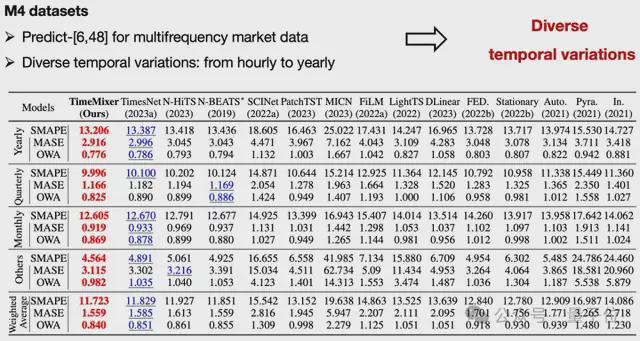
短程预测:单变量数据
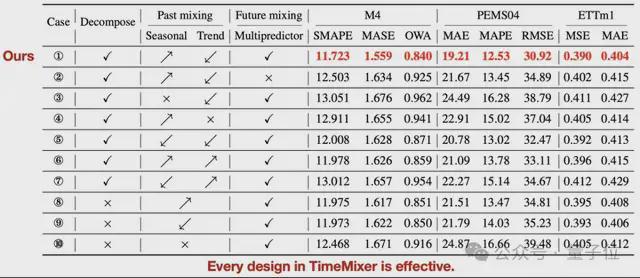
消融实验:为了验证 TimeMixer 每个组件的有效性,我们在所有 18 个实验基准上对 Past-Decomposable-Mishing 和 Future-Multipredictor-Mishing 模块中的每种可能的设计进行了详细的消融研究。
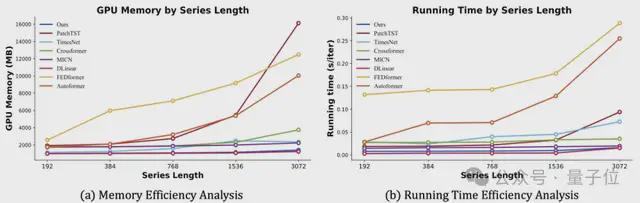
模型效率:团队将训练阶段的运行内存和时间与最新最先进的模型进行比较,其中 TimeMixer 在 GPU 内存和运行时间方面,对于各种系列长度(范围从 192 到 3072)始终表现出良好的效率),此外还具有长期和短期预测任务一致的最先进性能。
值得注意的是,TimeMixer 作为深度模型,在效率方面表现出接近全线性模型的结果。这使得 TimeMixer 在各种需要高模型效率的场景中大有前途。
好了,TimeMixer 为时序预测领域带来了新的思路,也展示了纯 MLP 结构在复杂任务中的潜力。
未来,随着更多优化技术和应用场景的引入,相信 TimeMixer 将进一步推动时序预测技术的发展,为各行业带来更大的价值。
本项目获得了蚂蚁集团智能引擎事业部旗下 AI 创新研发部门 NextEvo 支持。
蚂蚁集团 NextEvo-优化智能团队负责蚂蚁运筹优化、时序预测以及预测优化相结合的智能决策等技术方向,团队工作涵盖算法技术、平台服务和解决方案的研发。
论文地址:
https://arxiv.org/abs/2405.14616v1
论文代码:






