此前,有报道称斯坦福 AI 团队抄袭中国面壁智能团队的开源大模型。一开始,斯坦福团队称他们只是使用了 MiniCPM-Llama3-V 2.5 的 tokenizer(分词器),并宣称在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作。
后续,面壁智能团队测试发现,斯坦福 AI 团队研发的大模型在识别清华简的文字时,结果和 MiniCPM-Llama3-V 2.5 不仅在正确的地方一模一样,在犯错的地方也雷同。
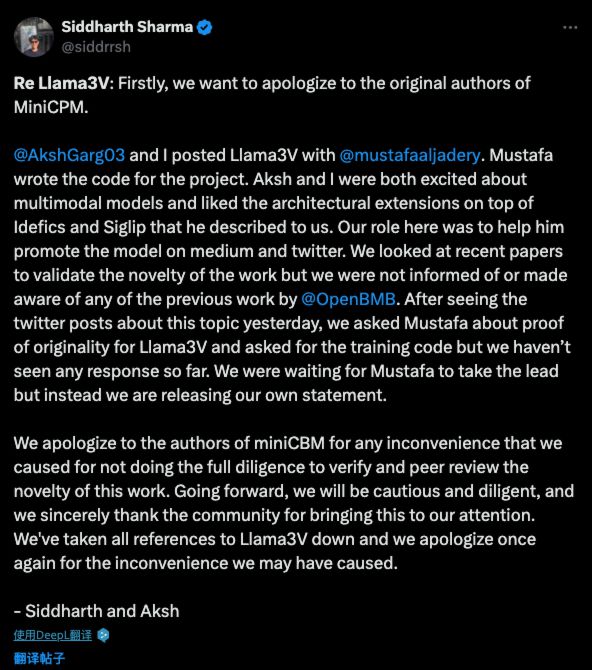
面壁智能联合创始人兼 CEO 李大海在朋友圈也对此事做出回应,感慨这是一种「受到国际团队认可的方式」。随后,斯坦福 Llama3-V 团队的两位作者 Siddharth Sharma 和 Aksh Garg 在 X 上就这一学术不端行为对面壁 MiniCPM 团队正式道歉, 表示会将 Llama3-V 模型悉数撤下。
在道歉信中,两位作者称他们负责模型的宣发工作,而该模型代码的作者是 Mustafa Aljadery ,但两人在看到相关质疑后于 6 月 2 日询问了 Aljadery ,此后再也没能联系上后者,于是决定发布道歉声明。






