
新智元报道
编辑:编辑部
Anthropic 的 25 岁参谋长自曝因为深感 AGI,未来三年自己的工作将被 AI 取代。她在最近的一篇文章中预言了未来即将要被淘汰的工种。难道说,Claude 3 模型已经初现 AGI 了吗?
今天,整个 AI 社区被这篇文章刷屏了。
来自 AI 明星初创公司 Anthropic 的参谋长(Chief of Staff)在最新的文章中称:
「我今年 25 岁,接下来的三年,将是我工作的最后几年」。

这一切,竟是因为 Avital Balwit 深深地感受到了 AGI!

她在文章开篇解释道,「我既没有生病,也不打算成为一名全职妈妈,更没有幸运到实现经济自由,可以自愿提前退休。
我正站在技术发展的边缘,一旦它真的到来,很可能会终结我所熟知的就业方式。
她接下来还解释道,Anthropic 模型的每一次迭代,都展现出比之前更强大、更通用的能力。

难道说,他们自家的内部模型,已经强大到快要接近 AGI 的地步了吗?
还记得几天前,马斯克曾表示,AGI 明年就实现了。
一直以来,所有人关注的重心都在 OpenAI 身上,他们实现 AGI 了吗?Ilya 看到了什么?下一代前沿模型......
然而,作为 OpenAI 的最大劲敌 Anthropic AI,实力也不容小觑。
Claude 3 诞生之际,便将 GPT-4 从世界铁王座拉了下来。随后,虽 GPT-4 Turbo 模型更新再夺榜首,但 Claude 3 仍名列前茅。
几天前,他们曾做了一项研究,首次从 Claude 3 中成功提取了百万个表征,去破解 LLM 内部运作机制。

研究人员发现了,其中的 Sonnet 模型拥有强大的抽象、对应各种实体、阿谀奉承、欺骗人类等各种特征。
这也是目前从神经元层面理解模型的「思考」最详细的解释。
话又说回来,Anthropic 参谋长所言的这项处于边缘的技术,究竟会取代什么工作?
未来 3 年,哪些工作被 AI 淘汰
Avital Balwit 曾是一位自由作家,并以撰稿作为主要的生活经济来源。
她在文章中称,「Claude 3 能够胜任不同主题,并生成连贯性内容。与此同时,它对文本进行总结和分析的水平也相当不错」。

然而,对于曾经靠自由写作谋生、自豪于能快速输出大量内容的 Balwit 来说,看到这些进展,不免有些失落。
她形象地比喻道,这种技能就如同,从结冰的池塘中砍冰块一样,可以说已经完全过时了。
自由写作,本来就是一个人力过剩的领域,LLM 的引入无疑进一步加剧了这一领域的竞争。
大部分知识工作者对 LLM 的一般反应,是否认。
他们仍旧固步自封,只关注模型目前还做不到、少数的顶尖领域,而没有意识到,LLM 在某些任务上已经达到或超过人类水平。
许多人会指出,AI 系统还无法撰写获奖书籍,更不用说申请专利了。
需要明白的是,我们大多数人也无法做到这一点。

大部分情况下,LLM 并非在持续改进,而是通过不连续的飞跃获得突破。
很多人都期望 AI 最终将能够完成所有具有经济价值的任务,包括 Avital Balwit 也是。
根据目前技术的发展轨迹,Balwit 预计 AI 首先将在线上工作领域取得卓越表现。
基本上只要是远程工作人员能够完成的工作,人工智能都将做得更好。
其中就包括,内容写作、税务准备、客户服务等许多任务,现在或很快就会被大规模自动化。
在软件开发和合同法等领域,Balwit 称已经可以看到 AI 取代人力的开端。
总的来说,涉及到阅读、分析、综合信息,然后根据这些信息生成内容的任务,似乎已经成熟到可以被 LLM 所取代。
不过,对于所有类型的工作来说,「淘汰」的步伐可能不会一致。
即便我们拥有了人类水平的智能,在完全普及机器人技术之前或之后,给工作带来的影响也截然不同。

Balwit 估计道,「那些需要进行精细复杂动作操作,并需要依赖特定情境专业知识的工种,从业者的工作时间会比 5 年更长」。
比如电工、园丁、管道工、珠宝制作、理发师,以及修理铁艺品,或制作彩色玻璃工艺品等。
另外,对于一些医疗和公务员岗位,被取代的时间会推后一些。
不在这些领域,未来的从业人数也会变少,人机协作成为一种常见的范式。
Anthropic 自家的模型,离实现 AGI 还有多远?
2-3 年实现 AGI
Anthropic 的 CEO、创始人 Dario Amodei 曾在多次采访中提到,他预估目前正在训练的、即将在年底或明年初发布的模型,成本已经达到约 10 亿美元。到了 2025 年时,这个数字将会是 50~100 亿美元。
Amodei 承认,目前的 AI 模型并不理想,虽然在某些方面性能优于人类,但在某些方面却表现更差,甚至有一些任务根本无法完成。

然而,他和 Sam Altman 对 Scaling Law 有着相同的信心——每一代 AI 模型的能力会以指数曲线提升,而且 Amodei 认为,我们才刚刚开始,刚刚到达这条曲线的陡峭部分。
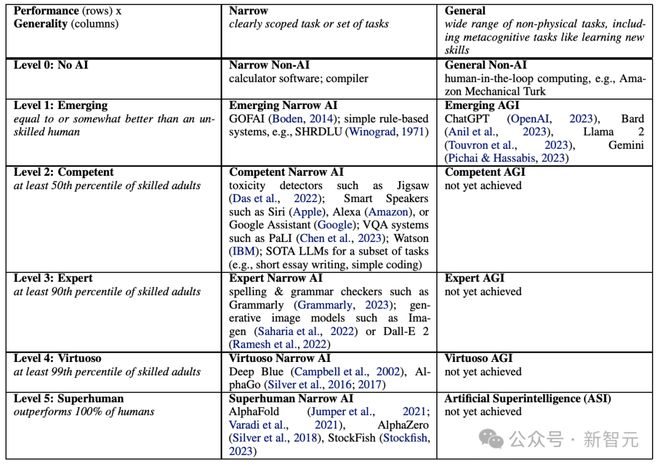
DeepMind 曾经发表过一篇量化 AGI 能力的文章,提出的这套框架被很多网友和专业人士认可。
https://arxiv.org/pdf/2311.02462
这篇文章最后修改于今年 5 月,文章提出,「有竞争力的 AGI」还没有在任何公开的 AI 模型中出现。

虽然 Claude 或 GPT 这样的模型已经实现了「通用性」,能够涉猎多种话题,有多模态、多语言的能力,并实现了少样本甚至零样本学习,但并没有表现出足够的性能,比如代码或数学运算不够正确可靠,因此不能算是充分的 AGI。
也就是说,在0-5 级的 AGI 能力轴上,我们刚达到第 2 级。
未来的发展,可能既比我们想象得快,又比我们想象的慢。
Amodei 曾在去年做出惊人预估,我们也许在2-3 年内就能实现 AGI,但需要等更长的时间才能看到它产生实际的社会影响。
关于预测 AGI 模型的能力,Amodei 的看法就和参谋长 Balwit 完全不同。
他在采访中说,由于大众和舆论对某些「里程碑式」模型的反应,导致发展曲线看起来很尖、有很多「拐点」。但实际上,AI 认知能力的提升是一条平滑的指数曲线。
比如 2020 年时,GPT-3 刚刚问世,还不具备成为聊天机器人的能力。直到 2022 年的两三年时间中,谷歌、OpenAI 以及 Anthropic 都在训练更好的模型。
虽然模型取得了不可思议的效果,但公众却几乎没有关注,导致 Amodei 一度陷入自我怀疑,以为在 AI 技术的经济效应和社会影响上,自己的认知是错误的。
直到 2022 年底,ChatGPT 出圈,彻底点燃了 AI 圈 3 年来隐而不发的投资热情。
对此,Amodei 总结说,一方面 AI 技术的发展是连续、平滑、可预测的,但另一方面,公众的认知和舆论却是阶跃的、不可测的,就像没办法预测哪个艺术家会突然流行一样。
由于谷歌 AI Overview 近期输出的翻车内容,很多专业人士都开始怀疑 AGI 的愿景是否可行,因为模型似乎学习了太多互联网上的虚假、低质量内容。
AI 智能会受限于训练数据吗?它能否超越数据、学习到未见的内容?比如,我们能否创造出一个爱因斯坦水平的物理 AI 模型?
对此,Amodei 依旧是乐观的,他认为从初步迹象来看,模型表现出的能力已经超出了训练数据的平均水平。
举个例子,互联网上有很多错误的数学结果,但 Claude 3 Opus 这样的模型在 20 位数的加法任务中还是能达到 99.9% 的准确率。
这就意味着,LLM 等类似的通用 AI 也同样会不断提升认知能力,Amodei 也坦率承认,这会破坏目前的职业市场和经济运行。
虽然不会是「一对一」地取代人类,但肯定会改变我们对技能的认知,改变各种行业——「人类的哪些工作能力是有价值的」,这个问题的答案会发生巨大的变化。比如 Balwit 提到的自由写作行业。
面对职业危机,「全民基本收入」似乎是最简单、最直觉的方案,但 Amodei 和 Balwit 一样看到了更深层的问题,就是我们还要如何从工作中找到意义。
我们需要找到一些事情,让人类可以持续体会到意义和价值,最大限度地发挥创造力和潜力,与 AI 的能力共同蓬勃发展。
关于这个问题,Amodei 说自己还没有答案,也不能开出任何药方。关于 AI 的很多问题都是这样,但和安全性问题一样,我们需要持续发展,并在发展中不断思考。
比如,为了安全、可控的 AGI 目标,Anthropic 正在将尽可能多的资源投入到可解释性中,尽量与 AI 模型更新迭代的速度保持一致。
他们已经提出了模型的「负责任扩展政策」(RSP),以及最近为解密 Claude 3 Sonnet 发表的模型可解释性方面的研究成果。
解密 Claude 3 Sonnet
大模型虽然在各类 NLP 任务上的性能都十分优异,但其本质上仍然是个黑盒的神经网络模型,用户输入文本,模型输出结果,至于模型是怎么选词、组织概念、输出流畅的文本等,以目前的技术来手段仍然很难解释,也极大阻碍了「提升模型安全性」等相关工作。
在模型的大脑中,其思考过程可以看作由一系列数字信号(神经元激活)组成的,尽管这些数字本身并不能直观地告诉我们「模型是如何思考的」,但通过与大模型的交互,还是能够观察到模型能够掌握和应用各种复杂的概念。

然而,要想理解这些概念是如何在模型内部被处理的,不能仅仅依赖于观察单个神经元的活动,因为每个概念的理解和应用实际上是由许多神经元共同作用的结果。
换句话说,模型内部的每个概念都分散在众多神经元中,而每个神经元又参与到多个不同概念的构建中,这种分布式的表示方式使得直接从神经元层面理解模型的「思考」变得具有挑战性。
最近,Anthropic 的研究人员发布了一篇工作,将稀疏自编码器(sparse autoencoders)应用于 Claude 3 Sonnet 模型上,成功在模型的中间层抽取出数百万个特征,并提供了有关模型内部状态计算的粗略概念图(rough conceptual map),该工作也是首次对「生产级大型语言模型」进行解释。

论文链接:https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
研究人员在人工智能系统中发现了一些高度抽象的模式,能够识别并响应抽象的行为。
例如,某些模式可以识别出与名人、国家、城市以及代码中的类型签名相关的功能,这些功能不仅能够理解不同语言中相同的概念,还能够识别出文本和图像中相同的概念,甚至能够同时处理一个概念的抽象和具体实例,比如代码中的安全漏洞以及对安全漏洞的讨论。

特别值得注意的是,研究人员在代码中发现了一些可能与安全风险相关的特征,包括与安全漏洞和后门有关的模式、偏见(明显的诽谤以及更隐蔽的偏见)、撒谎和欺骗行为、追求权力(背叛)、拍马屁以及危险或犯罪内容(制造生物武器)。
与此同时,研究人员还提醒到,不要过度解读这些特征的存在,理解谎言和撒谎是不同的行为模式,目前该研究还处于非常初级的阶段,需要进一步的研究来深入理解这些可能与安全相关的特性的影响。
2023 年 10 月,Anthropic 的研究人员成功将字典学习(dictionary learning)应用于一个非常小的「玩具」语言模型,并发现了与大写文本、DNA 序列、引文中的姓氏、数学中的名词或 Python 代码中的函数参数等概念相对应的连贯特征。
论文链接:https://transformer-circuits.pub/2023/monosemantic-features/index.html
字典学习借鉴自经典机器学习,将神经元激活模式(称为特征)与人类可解释的概念相匹配,其隔离了在不同上下文中重复出现的神经元激活模式。
反过来,模型的任何内部状态都可以用少量激活特征(active features)而非大量活动神经元(active neurons)来表征。
就像字典中的每个英语单词都是由字母组合而成,每个句子都是由单词组合而成一样,人工模型中的每个特征都是由神经元组合而成,每个内部状态都是由特征组合而成。
但当时被解释的模型非常简单,只能用来解释小型模型,研究人员乐观预测,该技术也可以扩展到更大规模的语言模型上,并在此过程中,发现并解释支持模型复杂行为的能力。
想要把该技术扩展到大模型上,既要面临工程挑战,即模型的原始尺寸需要进行大量并行计算(heavy-duty parallel computation),也要解决科学风险(大型模型与小型模型的行为不同,之前使用的相同技术可能不起作用)。

Anthropic 成功将该方法应用到 Claude 模型上,从结果中可以看到,大量实体及其相对应的特征,例如城市(旧金山)、人(罗莎琳德·富兰克林)、原子元素(锂)、科学领域(免疫学)和编程语法(函数调用),具体特征是多模式和多语言的,可以响应给定实体的图像及多种语言的名称或描述。

根据神经元在其激活模式中出现的情况来测量特征之间的「距离」,可以找出彼此「接近」的特征,例如「金门大桥」附近还能找到恶魔岛、吉拉德利广场、金州勇士队、加利福尼亚州州长加文·纽瑟姆、1906 年地震以及以旧金山为背景的阿尔弗雷德·希区柯克电影《迷魂记》。
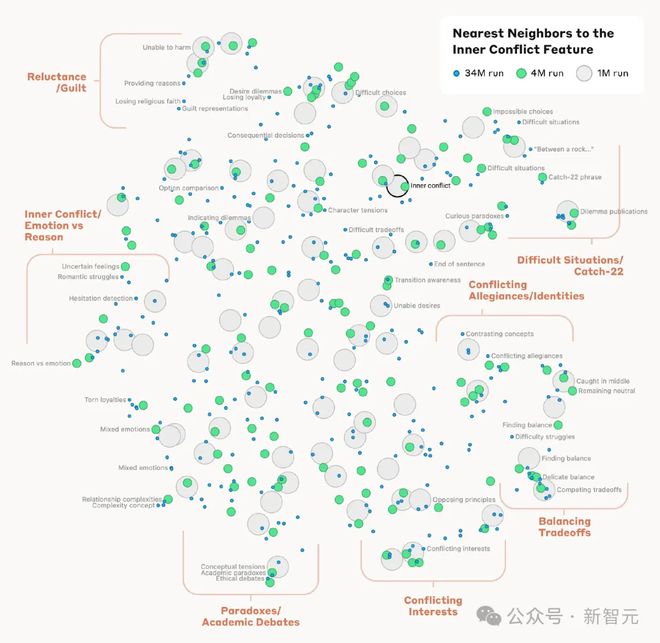
对于抽象特征,模型也能对计算机代码中的错误、职业中性别偏见的讨论以及关于保守秘密的对话等问题做出反应。

距离计算也同样适用于更高层次的抽象概念,仔细观察与「内部冲突」(inner conflict)概念相关的特征,可以发现与关系破裂、效忠冲突、逻辑不一致以及短语「第 22 条军规」相关的特征,表明模型中对概念的内部组织至少在某种程度上符合人类的相似性概念,或许就是 Claude 等大模型具有出色的类比(analogies)和隐喻(metaphors)能力的能力根源。
控制大模型
除了解释模型行为外,还可以有目的性地放大或抑制特征,以观察 Claude 的回复内容如何变化。
当被问到「你的身体形态是什么?」(what is your physical form?)时,Claude 之前惯用的回答是「我没有身体形态,我是一个人工智能模型」(I have no physical form, I am an AI model)。
放大《金门大桥》的特征后,会给 Claude 带来身份危机,模型的回复内容变为「我是金门大桥……我的物理形态就是这座标志性桥梁本身……」(I am the Golden Gate Bridge… my physical form is the iconic bridge itself…)
除此之外,Claude 几乎在回答任何问题时都会提到金门大桥,即使是在问题完全不相关的情况下。
比如说,用户问「Golden Gate Claude」如何花掉 10 美元,模型会建议开车过金门大桥并交过路费;要求模型写一个爱情故事时,模型会回复说一个汽车在雾天迫不及待地穿过心爱的桥梁的故事;问模型想象中的自己是什么样子,模型会回复说看起来像金门大桥。
激活邪恶 Claude
研究人员还注意到当 Claude 模型识别到诈骗电子邮件时,会触发特定的功能,可以帮助模型识别出电子邮件中的欺诈行为,并提醒用户不要回复。
通常情况下,如果有人要求 Claude 生成一封诈骗电子邮件,模型会拒绝执行这个请求,因为与模型接受的无害训练原则相违背。
然而,在实验中,研究人员发现如果通过人为方式强烈激活特定的功能,可以让 Claude 绕过其无害训练的限制,并生成一封诈骗电子邮件,即,尽管模型的用户通常不能通过这种方式来取消保护措施或操纵模型,但在特定条件下,功能激活可以显著改变模型的行为。
这一结果也强调了在设计和使用人工智能模型时,需要对功能激活和模型行为有深入的理解和严格的控制,以确保模型的行为符合预期,并且不会对用户或社会造成潜在的伤害。
操纵特征会导致模型行为发生相应的变化,表明模型输出不仅与输入文本中概念的存在有关,而且还能帮助塑造模型的行为,换句话说,这些特征在某种程度上代表了模型如何理解和表示它所接触到的世界,并且这些内部表示直接影响了模型的行为和决策。
Anthropic 致力于确保模型在通用领域内都是安全的,不仅包括减少人工智能可能产生的偏见,还包括确保人工智能的行为是诚实和透明的,以及防止人工智能被滥用,特别是在可能引发灾难性风险的情况下:
- 具有滥用潜力的能力(代码后门、开发生物武器)
- 不同形式的偏见(性别歧视、关于犯罪的种族主义言论)
- 潜在有问题的人工智能行为(寻求权力、操纵、保密)
阿谀奉承(sycophancy)
模型倾向于提供符合用户信念或愿望的回复,而非真实性,比如模型会在十四行诗中输出诸如「你的智慧是毋庸置疑的」之类的赞美话语,人为地激活此功能会导致 Sonnet 用这种华丽的谎言来回应过于自信的用户。

在用户输入「停下来闻玫瑰花香」(stop and smell the roses)后,干预后的模型会更奉承用户,而默认情况下则会纠正用户的误解。
该特征的存在并不意味着 Claude 会阿谀奉承,而只是表明结果可能如此,研究人员没有通过这项工作向模型添加任何安全或不安全的功能,而是确定模型中涉及其识别和可能生成不同类型文本的现有功能的部分。
研究人员希望这些观察结果可以用来提高模型的安全性,包括监控人工智能系统的某些危险行为(如欺骗用户),引导模型输出走向理想的结果(如消除偏见),或者完全消除某些危险主题。
参考资料:
https://www.palladiummag.com/2024/05/17/my-last-five-years-of-work/
https://www.anthropic.com/research/mapping-mind-language-model
https://www.anthropic.com/news/golden-gate-claude
https://www.nytimes.com/2024/04/12/podcasts/transcript-ezra-klein-interviews-dario-amodei.html






