
文适道
说到云巨头,你的脑中可能会闪过:亚马逊 AWS、微软 Azure,以及谷歌 Google Cloud。
但最近,一家云计算公司掌门人侃侃而谈:“指望 AWS 们部署 GPU 云,就像是走进福特公司,要求他们生产一辆 Model Y。”
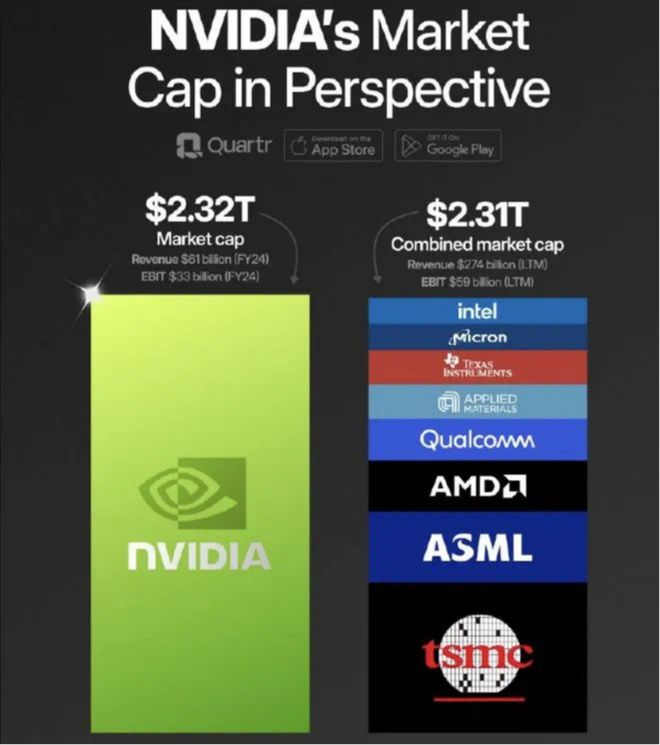
放出如此“狂言”正是英伟达的“大儿子”——CoreWeave。毕竟,人家有个最新市值≈台积电+阿斯麦 +AMD+ 高通+应用材料+德州仪器+美光+英特尔的“好爸爸”英伟达撑腰。
刚刚,这家 GPU 云计算公司又借到了 75 亿美元买显卡,本轮债务融资由 Blackstone、Magnetar、Coatue 领导;5 月初,Coreweave 才完成了 11 亿美元的C轮融资,最新估值达 190 亿美元。
用一句话概括 CoreWeave 的爽文经历,可以总结为“好风凭借力”。
CoreWeave 的三位创始人 Michael Intrator、Brian Venturo 和 Brannin McBee 均是华尔街的“本分打工人”,做过大宗商品交易员,经营过对冲基金、家族办公室。直到 2016 年,他们在曼哈顿办公室的台球桌上,用一块英伟达 GPU 挖到了以太坊网络上的第一个币。
在接踵而至的加密热潮中,他们的 GPU 越买越多,导致“华尔街的办公桌堆满了 GPU”。再后来,挖矿地点也从台球桌变成了新泽西州的一个车库。
2017 年,CoreWeave 正式成立。
2018 年,不少挖矿公司倒闭。CoreWeave 趁机抄底 GPU,存货从 3 位数张变成了 5 万张,数据中心增加到了 7 个,占以太坊网络总量的1% 以上。
2019 年,CoreWeave 转型做 IaaS,并将消费级 GPU 全面转向英伟达的企业级 GPU。
2020 年,CoreWeave 宣布加入英伟达合作伙伴网络计划,成为“算力黄牛”。
2022 年,大规模显卡挖矿时代结束,CoreWeave 彻底转型为一家云服务提供商,并在 11 月成为首批提供采用英伟达 HGX H100 超级芯片的云服务商之一。
几乎是同时,ChatGPT 推出,生成式 AI 爆火。CoreWeave 手里的几万张 GPU 全部成为了“珍贵香料”,客户包括 OpenAI、微软、Inflection(已殉)等众多 AI 巨头。
2023 年 4 月,CoreWeave 获得了来自英伟达的 2.21 亿美元 B1 轮融资。黄仁勋在业绩电话会点名“你会看到一大批新的 GPU 专业化云服务提供商”“最知名的当属 CoreWeave,他们做得非常出色。”更为关键的是,英伟达给 CoreWeave 开了“比药还难买”的 A100、H100“小灶”。8 月,CoreWeave 就将英伟达 H100 作为抵押品,获得了另外 23 亿美元的债务融资,资金将用于收购更多芯片,以及建设更多数据中心。
彼时,有两位著名硅谷“狂徒”正在扯着黄仁勋的皮衣,求宠爱。去年 9 月,Oracle 创始人 Larry Ellison 和他的好友 Elon Musk,邀请黄仁勋在硅谷一家豪华餐厅吃日料。这顿饭让 Ellison 如芒刺背、如坐针毡、如鲠在喉。他事后回忆:寿司吃了一小时,我俩就跪求了一小时。
为何“好爸爸”英伟达一定要将 CoreWeave 送上青云?
显而易见——CoreWeave 并不打算,也似乎没能力自己造芯片。
黄仁勋在台湾大学的演讲中提到:“为了食物而奔跑,或者为了不被他人当食物而奔跑。无论哪一种情况,都要保持奔跑。”但对于英伟达而言,用一张张 GPU 堆起来的万亿帝国何尝不是“前门有虎,后门有狼”。
前有英特尔、AMD 等半导体巨头研发 AI 芯片,后有 OpenAI、微软等下游客户推动自研芯片,自己做“铲”自己挖。从客观上看,三大云巨头本身也有充足的资源和动机自研芯片。前面“跪求”黄仁勋的马斯克自己也说:“英伟达不会永远在大规模训练和推理芯片市场占据垄断地位。”
英伟达的应对之策有二:一是自己做云,包括发布 DGX Cloud。即便只是将 DGX Cloud 托管在各家云服务商的云平台上,也动了大客户的奶酪,比如 AWS 曾直接拒绝合作,但后来又被迫答应了。二是扶持“对手”的对手,例如 CoreWeave、Lambda Labs 等较小的云服务商,让微软等巨头不得不再“交”一层 GPU 税。
近日,春风得意的 CoreWeave 披露:其设施可能要运行数十万张 H100。如此看来,尽管其容量不足以与 AWS 或微软相比,但预期增长可能会在 GPU 云销售方面接近 Oracle。
但如果排除英伟达“撑腰”的因素,CoreWeave 确实给了客户 pick 自己的理由。
从性能看,CoreWeave 承诺公司专注于高性能计算服务,而不像一般云服务商还提供存储、网络等多种服务。因此“比传统云提供商快 35 倍,成本低 80%,延迟低 50%”。
从价格看,在 CoreWeave 租用英伟达 A100 40GB GPU,每小时收费 2.39 美元,相当于每月 1200 美元。相比之下,在 Azure 和 Google Cloud 上,相同 GPU,每小时价格分别为 3.40 美元和 3.67 美元,每月成本高达 2482 美元和 2682 美元。
CoreWeave 为何会出现这些明显优势,公司与英伟达的合作将走向何方,从云服务商的角度如何观察 AI 浪潮趋势?在 The Information 最新采访中,CoreWeave 联合创始人 Brannin McBee 道出了答案。
内容如下:
The Information:这次融资意味着什么?
McBee:与 AWS、Google Cloud、Azure、Oracle 这些同行相比,这一轮融资使我们进入了超大规模计算的行列。
不同之处在于,我们是 AI 超大规模计算提供商,与世界上最大的云服务提供商处于同一类别。这不仅体现在我们的运营技能上,还体现在我们的合作伙伴上。我们的投资者、债权人、客户和供应商,这些都让公司定位为超大规模计算提供商。这就是你们现在看到的结果。
The Information:你们将如何用这笔钱?
McBee:如你所料,将全部用于基础设施建设。10 亿美元的C轮股权融资,是为了引入顶尖工程人才,以及顶尖的技术投资者。债务融资则是为了支持产品开发。
The Information:扩大 GPU 容量的最大瓶颈是什么?
McBee:很大程度上是电力。幸运的是,我们已经提前很久解决了这个问题。电力是目前整个市场的瓶颈。这也是我们最珍视的战略资产之一。我们能够识别出市场即将出现的问题,并提前确保实现增长目标所需的数据中心容量。
The Information:如果扩展到 28 个数据中心,到 2024 年底你们计划拥有多少兆瓦的数据中心容量?
McBee:超过 300 兆瓦。
The Information:明年呢?
McBee:我们有电力供应,有数据中心空间。远远超过这个数量的两倍。
The Information:我听说英伟达 H100 芯片在不同云服务中表现不同。为什么你们声称 H100 在 CoreWeave 的表现比在 AWS 更好?
McBee:差异在于将 H100 交付给客户的解决方案。换句话说,秘密在于软件。
我们构建了整个软件解决方案来支持 AI 基础设施,而我们的竞争对手则围绕托管网站和存储数据池构建他们的软件解决方案。结果当然不同。
这有点像你走进福特公司,要求他们生产一辆 Model Y。他们当然不能生产 Model Y,因为生产机制不同。所以,他们即便造出了某种看起来像 Model Y 的电动车,但实际上是两码事,包括性能。我们的竞争对手并非不能造出有四个轮子的电动车,但他们造不出 Model Y。
如果进一步延伸这个比喻:你总不能走进福特公司,说:“嘿!只要你们将现有的某处设备改造成能造 Model Y 的设备就行。”这当然行不通。因为涉及的是整个供应链和整体业务。
同样的道理,AWS 们面临的挑战正是如此。他们不能只把一个数据中心转变成 CoreWeave 模式。
注:在最近一篇文章中,CoreWeave 首席战略官 Brian Venturo 表示:“软件是 CoreWeave 最大化 GPU 服务器性能的‘秘密武器’,包括定期检查其‘健康状况’,允许客户快速启动服务器并自动增加他们使用的服务器数量。CoreWeave 还使用英伟达 Infiniband 网络电缆将其 GPU 服务器连接在一起,而其他云服务提供商则是使用自家网络或正朝这一方向发展。”
The Information:(客户)需求来自哪里?
McBee:去年,我们 90% 的工作是用于训练新的 AI 模型,主要客户是 AI 初创公司,主要收入也来自于此。
今年,虽然业务逐渐转向推理(运行 AI 模型来处理客户查询),但也有 70% 的工作仍是训练模型,而我们的收入和客户群体主要来自现有企业。
这反映了典型的技术采用曲线特征。早期采用者往往是初创公司,而我们观察到企业正在进入这一领域。这包括财富 500 强、财富 100 强,涵盖技术、金融,甚至越来越多地涉及合成生物技术公司。
The Information:相较竞争对手,为何 CoreWeave 能筹到如此多的资金?
McBee:资本聚集到我们这里是因为产品差异化。如果所有 GPU 初创公司都能获得同样的 GPU,那么每家公司都会获得同样的资金。
但事实并非如此。这不仅证明了我们的产品,还证明了我们的客户,以及我们在金融市场中的导航能力。与我们合作的对手极其复杂,他们是世界级的投资者。能够完成如此规模的交易,说明了我们作为企业的实力。
The Information:你预计 GPU 云领域会出现整合吗?
McBee:我不会说我们在 GPU 云方面有任何具体的并购整合计划。但在软件方面总是有机会进行收购。
注:2024 年,英伟达已进行了几次收购,包括以色列初创公司 Run:ai,该公司专门开发用于处理 AI 计算资源的软件。此举将提高英伟达 DGX Cloud 的效率。
The Information:你们与英伟达的关系如何?
McBee:英伟达是一个出色的供应商,拥有很棒的产品和市场。比如,客户都想要英伟达的产品,而不是想要其他产品,这涉及1-2 年的计划。我们非常珍视与英伟达的合作,也愿意将他们的基础设施带给消费者。
The Information:你们什么时候会拿到英伟达的新芯片 GB200?
McBee:市场对 GB200 的需求非常大。我们预计将在 2025 年初有货。
注:英伟达表示,预计 AWS、Google Cloud、Microsoft、CoreWeave 等是首批拿到 GB200 的云服务商,最早在今年年底。






