智东西
作者 ZeR0
编辑漠影
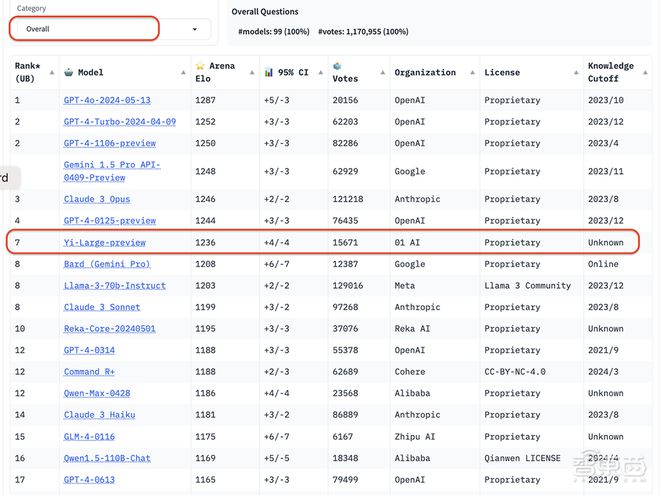
智东西 5 月 21 日报道,今日,知名大模型竞技场 LMSYS Chatboat Arena 盲测评测结果更新,国内大模型独角兽零一万物的千亿参数闭源大模型 Yi-Large 在最新总榜中排名世界第七,中国大模型中第一,超过 Llama-3-70B、Claude 3 Sonnet;其中文分榜更是与 GPT-4o 并列第一。
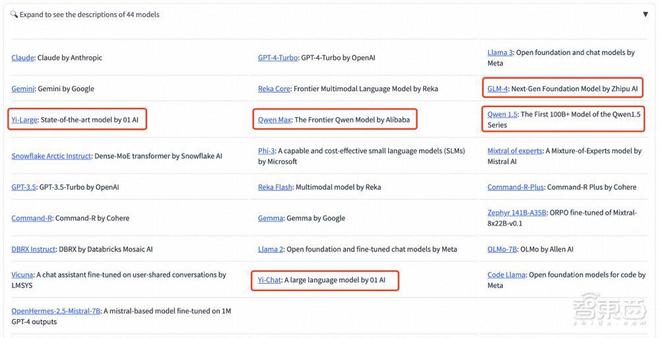
LMSYS Chatboat Arena 由第三方非营利组织 LMSYS Org 发布,其盲测结果来自至今积累超过 1170 万的全球用户真实投票数。此次共有 44 款模型参赛,既包含了开源大模型 Llama 3-70B,也包含了各家大厂的闭源模型。
Chatbot Arena 评测过程涵盖了从用户直接参与投票到盲测,再到大规模的投票和动态更新的评分机制等多个方面,这些因素共同作用,确保了评测的客观性、权威性和专业性,能够更准确地反映出大模型在实际应用中的表现。
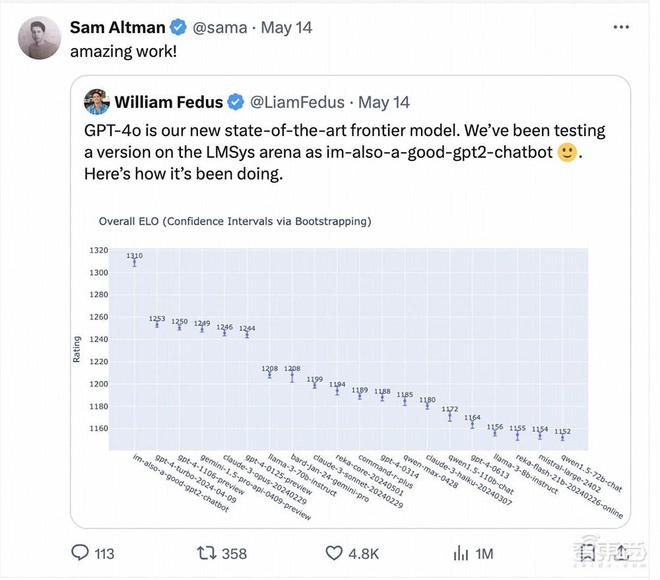
上周 OpenAI 的 GPT-4o 的测试版本便以“im-also-a-good-gpt2-chatbot”的马甲闯进 Chatbot Arena 排行榜,排名超过 GPT-4-Turbo、Gemini 1 .5 Pro、Claude 3 0pus、Llama-3-70b 等一众国际大厂当家基座模型。OpenAI CEO Sam Altman 也在 Gpt-4o 发布后亲自转帖引用 LMSYS arena 盲测擂台的测试结果。
从最新公布的 Elo 评分来看,GPT-4o 以 1287 分高居榜首,GPT-4-Turbo、Gemini 1 5 Pro、Claude 3 Opus、Yi-Large 等模型则以 1240 左右的评分位居第二梯队。
排名前 6 的模型分别来自海外巨头 OpenAI、Google、Anthropic,且 GPT-4、Gemini 1.5 Pro 等模型均为万亿级别超大参数规模的旗舰模型,其他模型也都在大几千亿参数级别。
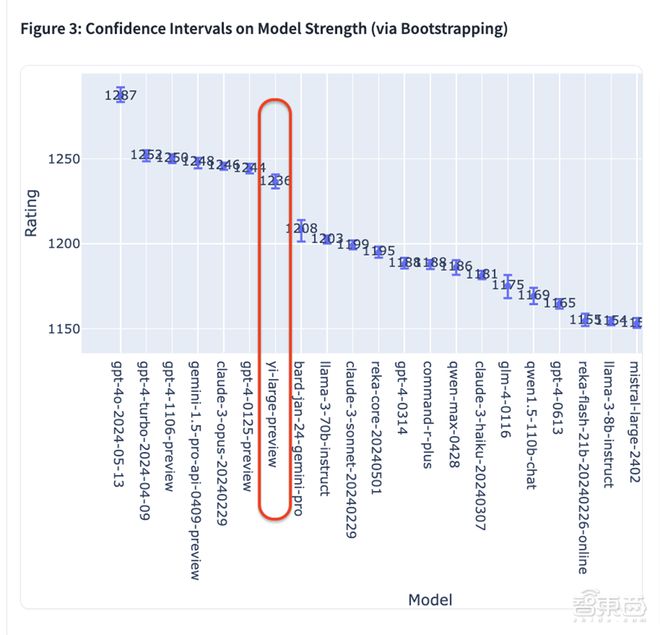
零一万物是总榜上唯一一家自家模型进入排名前十的中国大模型企业,按机构排序位于 OpenAI、Google、Anthropic 之后,排名第四。Yi-Large 大模型以仅千亿参数量级排名第7,评分为 1236。
其后 Bard(Gemini Pro)、Llama-3-70b-Instruct、Claude 3 Sonnet 的成绩则下滑至 1200 分左右;阿里巴巴的 Qwen-Max 大模型 Elo 分数为 1186,排名第 12;智谱 AI 的 GLM-4 大模型 Elo 分数为 1175,排名第 15。
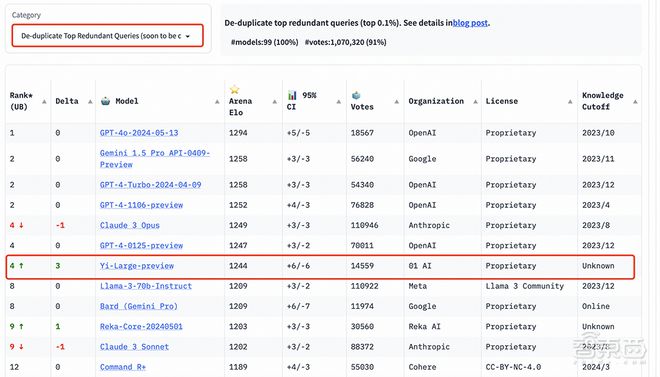
为了提高 Chatbot Arena 查询的整体质量,LMSYS 还实施了重复数据删除机制,并出具了去除冗余查询后的榜单。这个新机制旨在消除过度冗余的用户提示,如过度重复的“你好”。这类冗余提示可能会影响排行榜的准确性。LMSYS 公开表示,去除冗余查询后的榜单将在后续成为默认榜单。
在去除冗余查询后的总榜中, Yi-Large 的 Elo 得分更进一步,与 Claude 3 Opus、GPT-4-0125-preview 并列第四。
LMSYS Chatbot Arena 盲测竞技场公开投票地址:https://arena.lmsys.org/
LMSYS Chatbot Leaderboard 评测排行(滚动更新):https://chat.lmsys.org/?leaderboard
一、把一张 GPU 挤出更多价值,李开复谈大模型价格战影响
据零一万物 CEO 李开复博士透露,实现上述出色的成绩,Yi-Large 大模型尺寸不到谷歌、OpenAI 的1/10,训练用的 GPU 算力不到他们的1/10。在这背后,一年前零一万物的 GPU 算力只有谷歌、OpenAI 的5%;而这些海外顶级 AI 团队都是千人级,零一万物的模型加基础设施团队则总共不到百人。
“我们能够把同样的一张 GPU 挤出更多的价值来,这是今天我们能够达到这些成果的一个重要理由。”李开复说,“如果只评估千亿模型,至少在这个排行榜上是世界第一,这些点我们还是很自豪,在一年前,我们落后 OpenAI 跟 Google 开始做大模型研发的时间点有 7 到 10 年;现在,我们跟着他们差距在 6 个月左右,这个大大的降低。”
为什么追得这么快?零一万物模型训练负责人黄文灏博士谈道,零一万物在模型训练上的每一步决策都是正确的,包括花了很长时间提升数据质量、做 scaling Law,接下来还会不断提升数据质量和做 scale up。
同时,零一万物非常重视 Infra 的建设,算法 Infra 是一个协同设计的过程,这样才能把算力发挥到比较好的水平。在此过程中,其人才团队是工程、Infra、算法三位一体的。
李开复谈道,零一万物希望从最小到最大的模型都能够做到中国最好,未来可能有更小的模型发布,都会力求在同样尺寸达到业界第一梯队,而且在代码、中文、英文等很多方面表现出色;有各种较小的简单应用机会,零一万物的打法是“一个都不放过”。
他也关注到近期的大模型 API 价格战。李开复认为,零一万物的定价还是非常合理的,也在花很大精力希望进一步降价。
“100 万个 token,花十几块还是花几块钱有很大差别吗?100 万个 token 对很大的应用、很难的应用,我觉得我们是必然之选。”他谈道,零一万物的 API 横跨国内外,有信心在全球范畴是一个表现好、性价比合理的模型。“到今天为止,我们刚宣布的性能肯定是国内性价比最高。大家可能有用千 token、百万 token,大家可以自己测算一下。”
在他看来,整个行业每年推理成本降低到之前的1/10 必然会发生,今天的 API 模型调用比例还非常低,如果能让更多人用上,这是一个非常利好的消息。
李开复相信大模型公司不会做出不理智的双输打法,技术是最重要的,如果技术不行,就纯粹靠贴钱赔钱去做生意。万一中国以后就是这么卷,大家宁可赔光通输也不让别人赢,那零一万物就走外国市场。
黄文灏分享说,零一万物没有碰到数据荒的问题,看到数据有很多可挖掘的潜力,最近在多模态上有一些发现,能进一步增加一到两个数量级的数据量。“弱智吧”数据对模型训练质量和数据多样性的帮助,便是来自零一万物团队的想法。
二、Yi-Large:中文榜与 GPT-4o 并列第一,挑战性任务评测排名第二
国内大模型厂商中,智谱 GLM4、阿里 Qwen Max、Qwen 1.5、零一万物 Yi-Large、Yi-34B-chat 此次都有参与盲测。
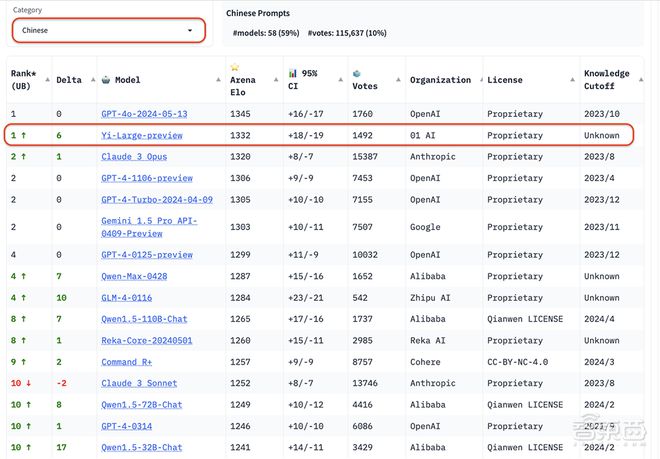
在总榜之外,LMSYS 的语言类别新增了英语、中文、法文三种语言评测。在中文语言分榜上,Yi-Large 与 OpenAI GPT-4o 的排名并列第一,Qwen-Max 和 GLM-4 也都排名靠前。
编程能力、长提问及最新推出的 “艰难提示词” ,这三个评测是 LMSYS 所给出的针对性榜单,以专业性与高难度著称。
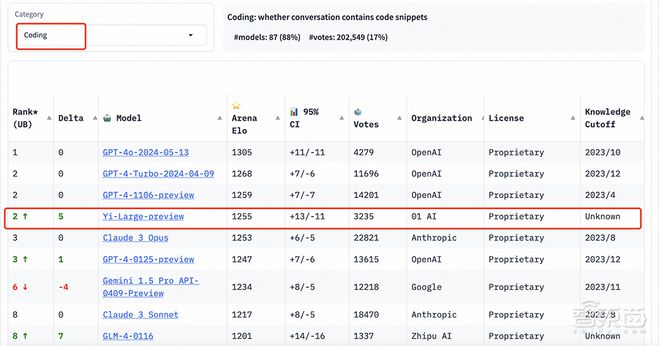
在编程能力(Coding)排行榜上,Yi-Large 的 Elo 分数超过 Anthropic 旗舰模型 Claude 3 Opus,仅低于 GPT-4o,与 GPT-4-Turbo、GPT-4 并列第二。
在长提问(Longer Query)榜单上,Yi-Large 同样位列全球第二,与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列。
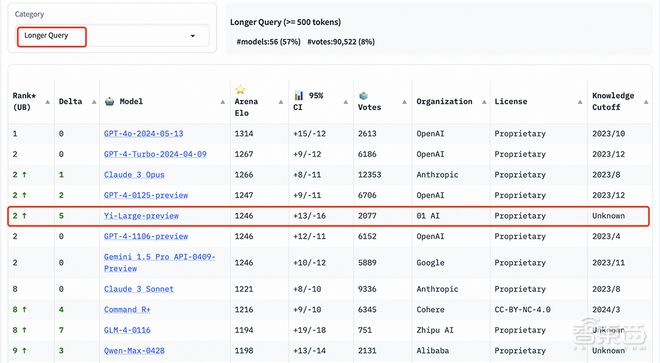
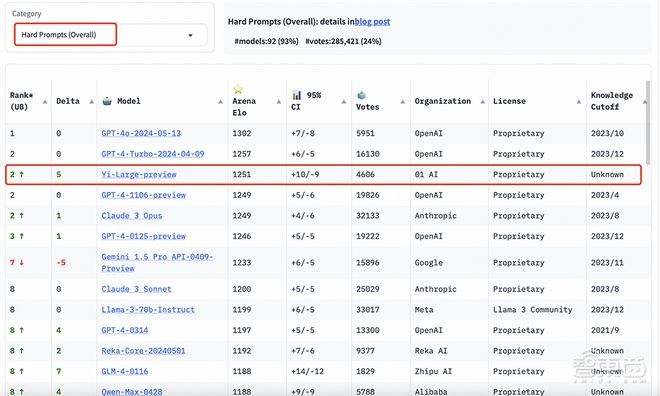
艰难提示词(Hard Prompts)类别包含来自 Arena 的用户提交的提示,这些提示则经过专门设计,更加复杂、要求更高、更加严格。
LMSYS 认为这类提示能够测试最新语言模型面临挑战性任务时的性能。在这一榜单上,Yi-Large 与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列第二。
三、进入后 benchmark 时代,盲测机制提供更公正的大模型评估
如何为大模型给出客观公正的评测一直是业内广泛关注的话题。在经过去年乱象丛生的大模型评测浪潮之后,业界对于评测集的专业性和客观性更加重视。
像 Chatbot Arena 这样能够提供真实用户反馈、采用盲测机制以避免操纵结果、并且能够持续更新评分体系的评测平台,不仅能够为模型提供公正的评估,还能够通过大规模的用户参与,确保评测结果的真实性和权威性。
LMSYS Org 发布的 Chatbot Arena 凭借其新颖的“竞技场”形式、测试团队的严谨性,成为目前全球业界公认的基准标杆。
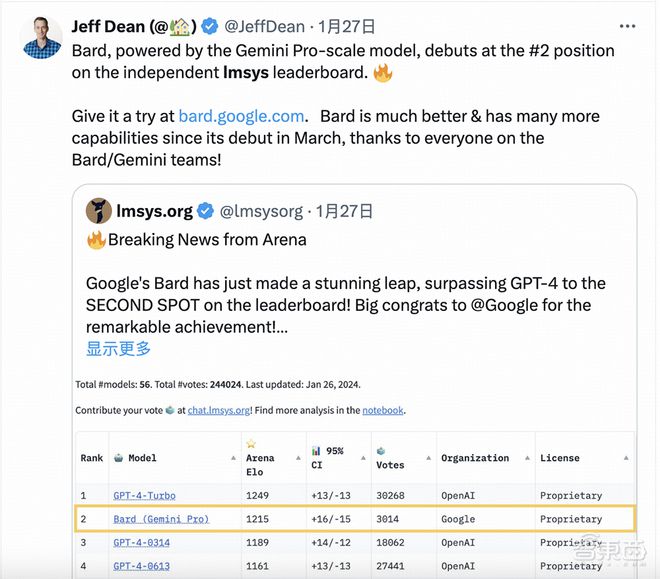
Google DeepMind 首席科学家 Jeff Dean 曾引用 LMSYS Chatbot Arena 的排名数据,来佐证 Bard 产品的性能。
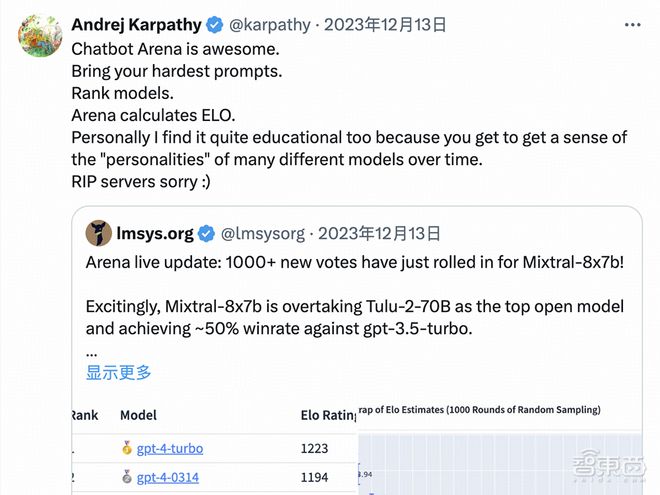
OpenAI 创始团队成员 Andrej Karpathy 发文夸赞说:“Chatbot Arena is awesome. ”
发布 Chatbot Arena 评测榜的 LMSYS Org 是一个开放的研究组织,由加州大学伯克利分校的学生和教师、加州大学圣地亚哥分校、卡耐基梅隆大学合作创立。
零一万物模型训练负责人黄文灏博士总结说,LMSYS 评测机制的题来自真实用户聊天,动态随机变化,没人能预测题目分布,也就无法对模型做单一能力的优化,客观性更好;再加上它由用户来打分,评测结果会更接近实际应用中用户的偏好。
虽然主要人员出自高校,但 LMSYS 的研究项目十分贴近产业,他们不仅自己开发大语言模型,而且向业内输出多种数据集(其推出的 MT-Bench 已是指令遵循方向的权威评测集)、评估工具,还开发用于加速大模型训练和推理的分布式系统,提供线上 live 大模型打擂台测试所需的算力。
Chatbot Arena 借鉴了搜索引擎时代的横向对比评测思路。它首先将所有上传评测的“参赛”模型随机两两配对,以匿名模型的形式呈现在用户面前;随后号召真实用户输入自己的提示词,在不知道模型型号名称的前提下,由真实用户对两个模型产品的作答给出评价。
在盲测平台 https://arena.lmsys.org/上,大模型们两两相比,用户自主输入对大模型的提问,模型A、模型B两侧分别生成两 PK 模型的真实结果,用户在结果下方做出投票四选一:A模型较佳、B模型较佳,两者平手,或是两者都不好。提交后,可进行下一轮 PK。
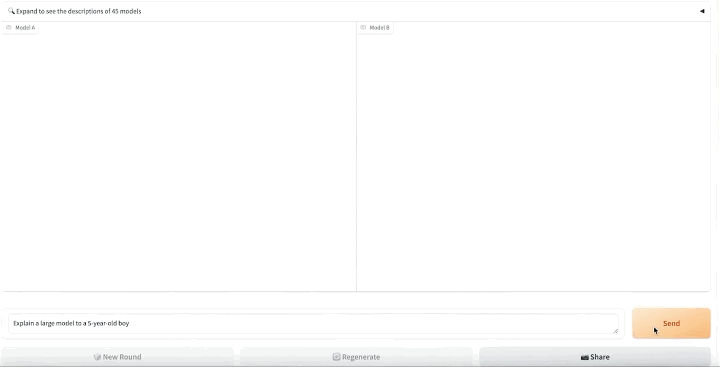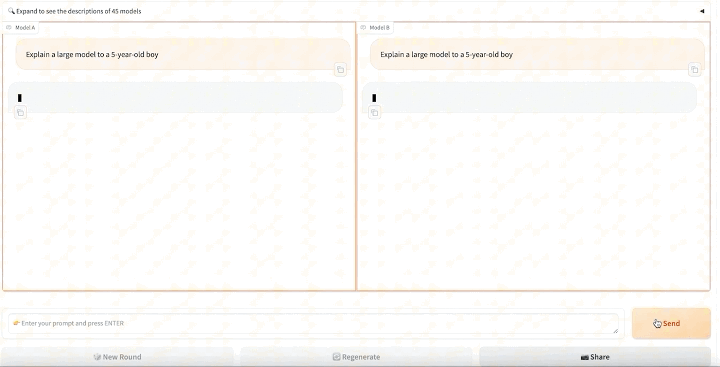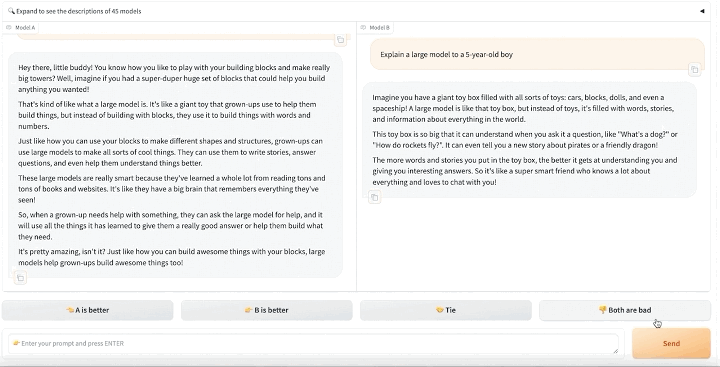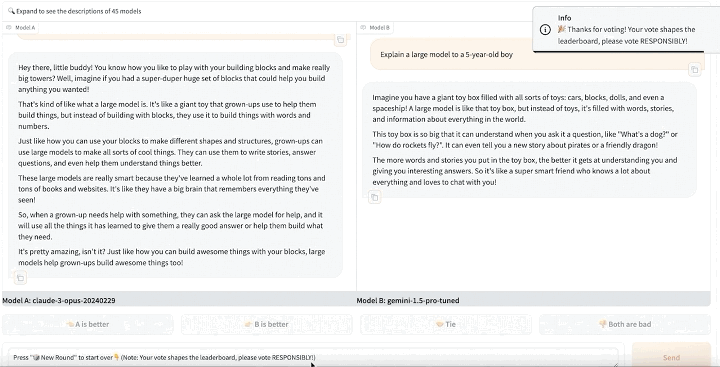
通过众筹真实用户来进行线上实时盲测和匿名投票,Chatbot Arena 既能减少偏见的影响,又能最大概率避免基于测试集进行刷榜的可能性,以此增加最终成绩的客观性。在经过清洗和匿名化处理后,Chatbot Arena 会公开所有用户投票数据。
在收集真实用户投票数据后,LMSYS Chatbot Arena 还使用 Elo 评分系统来量化模型的表现,进一步优化评分机制,保证排名的客观公正。
Elo 评分系统是一项基于统计学原理的权威性评价体系,由匈牙利裔美国物理学家 Arpad Elo 博士创立,旨在量化和评估各类对弈活动的竞技水平。Elo 等级分制度在国际象棋、围棋、足球、篮球、电子竞技等运动中都发挥着重要作用。
在 Elo 评分系统中,每个参与者都会获得基准评分。每场比赛结束后,参与者的评分会基于比赛结果进行调整。系统会根据参与者评分来计算其赢得比赛的概率,一旦低分选手击败高分选手,那么低分选手就会获得较多的分数,反之则较少。
结语:后发有后发的优势,中国人做产品强于美国
随着大模型步入商业应用,模型的实际性能亟需通过具体应用场景的严格考验。整个行业都在探索一种更为客观、公正且权威的评估体系。大模型厂商正积极参与到像 Chatbot Arena 这样的评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。
李开复认为,美国擅长做突破性科研,拥有创造力特别强的一批科学家,但中国人的聪明、勤奋、努力也不容忽视,零一万物把7-10 年差距降低到只有 6 个月,就验证了做好一个模型绝对不只是看多能写论文、多能发明新的东西、先做或后做。
“做得最好的,才是最强的,”在他看来,后发有后发的优势,美国的创造性很值得学习,“但是比执行力、比做出一个很好的体验、比做产品、比商业模式,我觉得我们强于美国公司。”
零一万物的企业级模型方向初步用户在国外,这是因为其团队判断国外用户的付费意愿或金额比国内大很多。按国内现在 To B 卷的情况,生意做一单赔一单,这种情况在早期 AI 1.0 时代太多了,零一万物团队不想这样做。
“今天可以看到的模型表现,我们超过其他模型,也欢迎不认同的友商来 LMSYS 打擂台,证明我是错的。但是直到那一天发生,我们会继续说我们是最好的模型。”李开复说。






