
西风发自凹非寺
量子位公众号 QbitAI
奥特曼承诺的小作文,它来了,还一发发两篇!
一篇短的,回应了离职霸王条款,也就是员工离职后说 OpenAI 坏话会被收回股权的事儿。
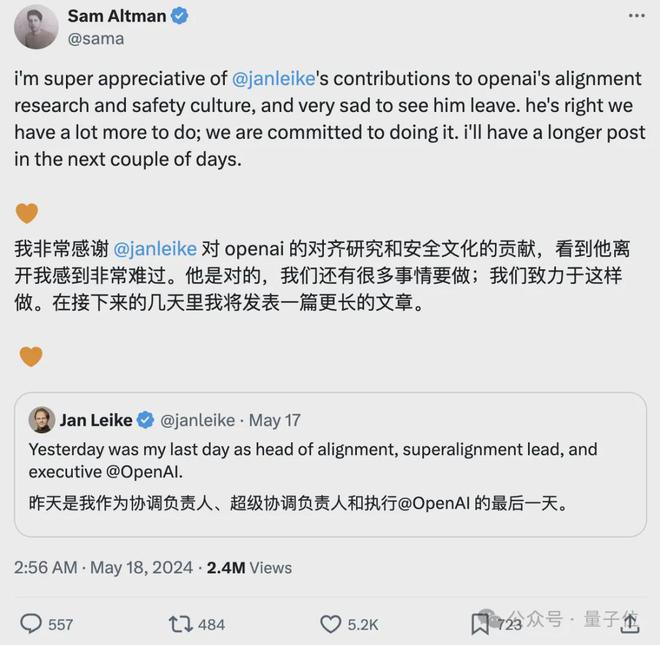
另一篇超长,讲了 OpenAI 的整体安全战略,回应了 OpenAI 前超级对齐负责人 Jan Leike 昨天的 13 条推文爆料:
OpenAI 对 AGI 的安全治理,优先级不如推出“闪亮的产品”。

不过,这篇回应小作文不是从奥特曼自己发的,而是 Greg Brockman 发的。
明明是在 Greg 的账号,署名确是 Sam 在前面,“Sam and Greg”。
冲着奥特曼这个发回应小作文的速度,昨天面对超级对齐团队炮轰还显得很淡定的奥特曼,看来也没那么淡定。
不过,这两篇小作文发出后,很多网友并不买账。
甚至有人这样评论小作文的效果:
汗流浃背的 CEO 发了一条全力挽回声誉的推文,从社区宠儿迅速跌落至声誉崩塌。

奥特曼都说了啥?
不会收回股权
先来看第一篇,完整版如下。
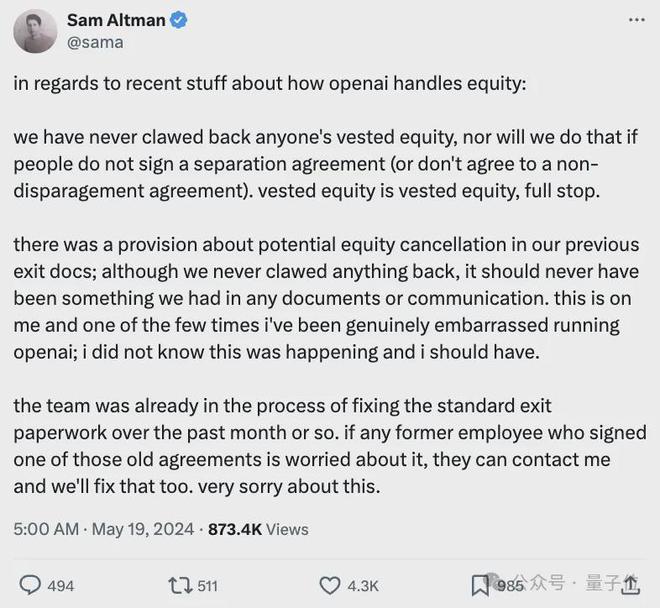
关于最近有关 OpenAI 处理股权的问题:
我们从未收回任何人已有的股权,即便员工未签署离职协议/不诋毁协议,我们也不会这么做。你的股权就是你的股权,这一点毫无疑问。
在我们之前的离职文件中确实有一项关于潜在收回股权的条款;虽然我们从未实际执行过这一条款,但这种条款不应该出现在任何文件或沟通中。
这是我的责任,是我在管理 OpenAI 过程中为数不多的几次真正尴尬的事情之一;我之前并不知道有这种情况,但我本应知道。
过去一个月左右,团队一直在修订标准离职文件。如果有任何前员工因签署了这些旧协议而感到担忧,可以联系我,我们会解决这个问题。对此我深感抱歉。
一句话总结:这事儿我不知道,大家放心不会收回你已有的股权。
看起来奥特曼回应的挺诚恳的,但网友看了一眼就表示:Jan 赢了。

为啥?
有网友摆出了不相信奥特曼的理由。

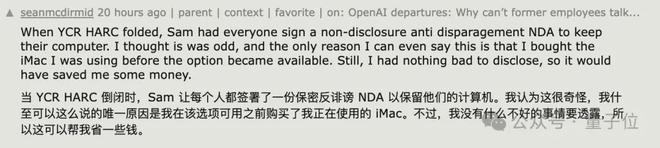
首先,有网友爆料奥特曼在之前的公司也让员工签过反诋毁协议。
YCR HARC 解散的时候,奥特曼让每个人都签署了一份保密和反诋毁协议,这样才能保留自己使用的电脑。我觉得这很奇怪。我之前就买下了使用的那台 iMac,所以我现在可以谈论这件事。
其次,众所周知,去年 OpenAI 内讧那会儿,有爆料称奥特曼与当时的董事会其他成员私下谈话,讨论替换掉 Helen Toner(OpenAI 原董事会成员),就是因为 Helen 和别人合写了一篇隐晦批评 OpenAI“煽动炒作 AI 的火焰”的文章。
所以,网友觉得让员工签不能说坏话的协议,不然就收回股权,这事儿奥特曼不可能不知道,这符合他的风格。
退一步来讲,就算奥特曼本人不知道这个条款,OpenAI 知道吧?这个条款又不会凭空出现。离职的员工肯定知道吧?
就没有人跟奥特曼投诉过?

OpenAI 的安全战略
再来看关于安全问题的回应。
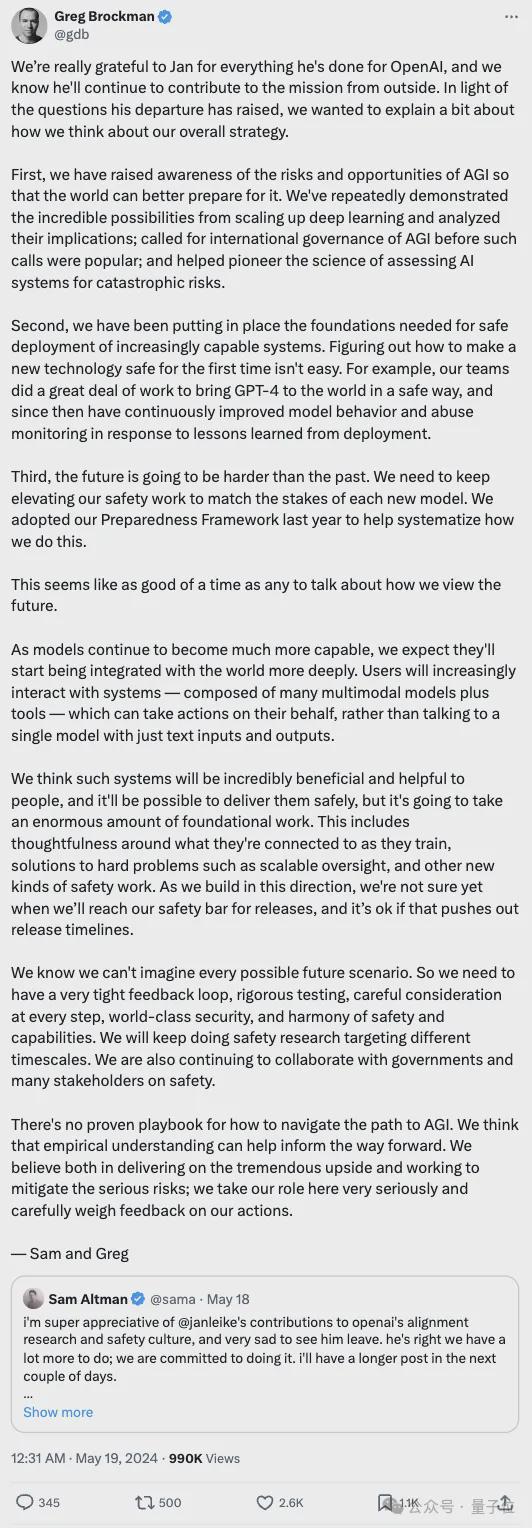
感谢 Jan 为 OpenAI 所做的一切贡献,即使他离开了,我们也相信他还会继续为我们的使命做出贡献。鉴于他的离职引发了一些问题,我们希望澄清我们对整体战略的看法。
首先,我们提高了对 AGI 风险和机遇的认识,帮助世界更好地为 AGI 的到来做好准备。我们多次展示了深度学习扩展带来的巨大潜力,并分析了这些潜力的影响。在国际上,我们率先呼吁对 AGI 进行治理,并在 AI 系统灾难性风险评估方面开创了科学研究。
其次,我们正在建立安全部署愈发强大的 AI 系统所需要的基础设施。确保一项新技术的安全并非易事。比如,我们的团队为安全推出 GPT-4 付出了大量努力,自那以后,我们不断改进模型行为和滥用监控,以应对部署中学到的经验教训。
第三,未来的挑战将更胜以往。我们需要不断提升安全工作,以应对每个新模型带来的风险。去年,我们采用了Preparedness Framework,用来系统化实现这一目标的方法。
是时候谈谈我们对未来的看法了。
随着模型愈发强大,我们预计它们将更深入地融入现实世界。用户将更多地与由多模态模型和工具组成的系统互动,这些系统不仅通过文本输入输出与用户对话,还能代表用户执行命令。
这些系统将对人们帮助巨大,并且可以安全地交付,但这需要大量基础工作。包括在训练过程中深入思考它们连接的内容,解决可扩展监督等难题,以及其他新型安全工作。我们尚不确定何时能达到我们的安全标准,推迟发布也是可能的。
我们无法预见未来每一个情景。因此,我们需要紧密的反馈循环、严格的测试,每一步都要谨慎考虑,保证世界级的安全性以及安全和能力的平衡。我们将继续进行不同时间尺度的安全研究,并与政府和利益相关者就安全问题合作。
目前还没有已验证的科学手册可以指导我们走向 AGI。我们相信基于经验的理解可以指引前进的道路。我们努力实现 AI 系统巨大的潜力,同时减轻带来的严重风险;我们认真审视我们扮演的角色,并仔细权衡反馈。
——Sam 和 Greg
看完后,网友一致认为虽然是 Greg 发的,但绝对是奥特曼写的。因为看起来一大篇,但实质性的东西啥也没说。

为啥要让 Greg 发,有网友猜大概是因为……奥特曼现在特别脆弱,觉得有必要发出“Greg 和我在一起,我发誓”这样的信息,来表明自己并不孤单。

不过也有网友从中分析出,OpenAI 的策略是通过测试、不断的反馈来改进模型确保 AI 安全性,这其实和超级对齐团队主张的预先给出证明的方法相悖,也难怪他们会分道扬镳。

对于这两篇回应,大伙儿怎么看?
参考链接:
[1]https://x.com/gdb/status/1791869138132218351
[2]https://news.ycombinator.com/item?id=40400224






