作者:赖文昕
编辑:郭思、陈彩娴
说起扩散模型生成的东西,你会立刻想到什么?
是 OpenAI 的经典牛油果椅子?

是英伟达 Magic3D 生成的蓝色箭毒蛙?

还是斯坦福大学和微软 Folding Diffusion 生成的蛋白质结构?
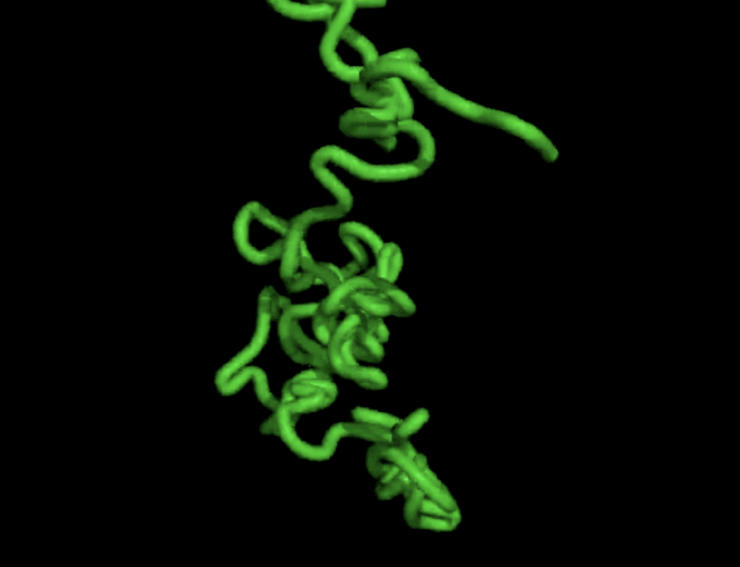
这些都是扩散模型的魔法展示,而近期,关于扩散模型的研究又进行了一次全新的升级。
由新加坡国立大学尤洋团队、加州大学伯克利分校以及 Meta AI Research 联手发布的一项名为“Neural Network Diffusion”的研究,已经实现了利用扩散模型来生成神经网络,这意味着扩散模型不再局限于生成表面的产品或物体结构,而是直接进行底层革新,开始拿神经网络做文章了,颇有种用魔法来打败魔法的意味。

论文地址:https://arxiv.org/pdf/2402.13144.pdf
该研究一出,迅速在国际 AI 社区引起了热烈反响,登上了各大模型开发平台的热搜榜单,在业界内收获了极高赞誉。

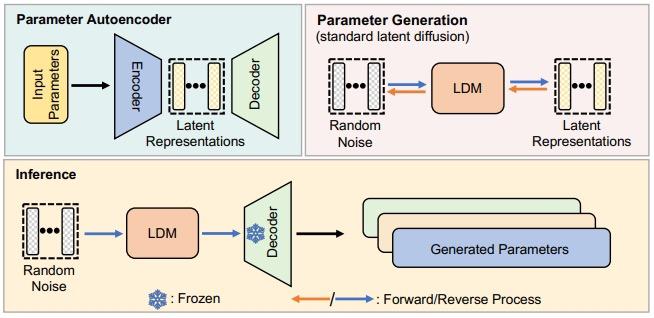
这项工作中,研究团队创新性地应用扩散模型来生成高性能神经网络的参数配置。他们结合了自动编码器框架和标准潜在扩散模型(LDM)设计了一种新颖的方法,即“参数扩散”(p-diff),通过训练 LDM 从随机噪声中合成有效的神经网络参数 latent representations。
此方法具有以下特点:1)它始终达到与训练数据相似的性能,甚至能在多数据集和架构中增强性能;2)生成的模型与训练的模型有很大的不同,这表明此方法可以合成新参数,而不是记忆训练样本。
扩散模型如何生成“神经网络”?
尽管扩散模型已经在视觉内容生成任务上取得了显著成就,然而在其他众多领域的应用潜力仍有待深入挖掘。
在此之前,学术界和工业界的研究重心主要在于如何通过传统的学习策略来获得针对特定任务表现优异的神经网络参数,而不是直接利用扩散模型进行参数生成。学者们普遍从统计学先验和概率模型的角度出发,例如探索随机神经网络架构及贝叶斯神经网络方法,以优化模型性能。
而在深度学习这个大框架下,虽然监督学习和自监督学习一直是训练神经网络的核心机制,并且在很多实际应用中取得了巨大成功。但为了更好地展示扩散模型在生成高效能模型架构与参数方面的卓越能力,研究团队大胆地将目光投向了尚未被充分探索的领域,尝试利用扩散模型来创造并优化高性能、结构新颖的神经网络参数。
简而言之,“Neural Network Diffusion”项目所采用的是一种名为“神经网络扩散”的方法(p-diff,p代表参数),使用标准的 LDM 来合成新参数。
该团队经过深入研究神经网络的训练机制以及扩散模型的工作原理后,敏锐地洞察到:基于扩散原理的图像生成过程与随机梯度下降(SGD)等常用学习方法之间存在着两种相似性。这意味着扩散模型或许能够借鉴并革新现有的训练范式,从而为构建更加智能且高效的神经网络提供新的视角与工具。
首先,神经网络训练和扩散模型的逆过程都可以被视为从随机噪声/初始化到特定分布的转变。其次,高质量图像和高性能参数也可以通过多次噪声的添加来降级为简单分布,例如高斯分布。
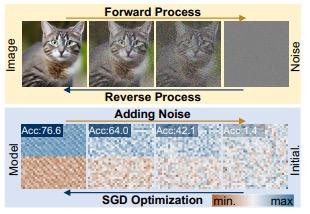
基于这些观察,研究团队引入了一种新的参数生成方法,称之为“神经网络扩散”(p-diff,p代表参数),它采用标准的 LDM 来合成一组新的参数。
扩散模型能够将给定的随机分布转换为特定的随机分布,因此研究人员使用了一个自动编码器和一个标准的 LDM 来学习高性能参数的分布。
该研究方法整合了参数自动编码器和扩散模型来实现神经网络参数的创新生成。首先,研究人员选取一组经过充分训练且表现出色的模型作为基础,从中抽取一部分关键或有代表性的参数子集,并将这些多维结构的参数展平为一维向量形式。
接下来,他们构建了一个参数自动编码器架构,其中包含一个编码器模块,用于从所提取的一维参数向量中学习潜在的低维表示(latent representations),这一过程能够捕捉到原有参数的关键特征和模式。同时配备一个解码器模块,其任务是根据这些潜在表示恢复出原始的高维参数结构。
在此基础上,团队进一步训练一个标准的扩散模型(LDM,Latent Diffusion Model)以适应参数生成场景,使其能够在随机噪声输入下逐步迭代并生成与目标参数对应的高质量潜在表示。
训练完成后,研究人员利用一个逆扩散过程(p-diffusion process)来生成新的神经网络参数。这个过程始于一个随机噪声向量,通过逆向递归地应用扩散模型的反变换,将其一步步转化为有意义的潜在表示。最后,将这些合成的潜在表示输入训练好的解码器中,解码器会将其转换为全新的、有望保持高性能的神经网络参数。这种方法不仅拓展了扩散模型的应用领域,还可能挖掘出之前未被发现的有效网络结构和参数配置。
训练后,研究团队利用 p-diff 通过以下链条生成新的参数:随机噪声 → 逆过程 → 训练好的解码器 → 生成的参数。
为了验证该方法的有效性,研究团队紧接着还在 MNIST、CIFAR-10/100、ImageNet-1K、STL-10 等广泛的数据集上进行了评估实验,实验主要在神经网络 ResNet-18/50、ViT-Tiny/Base 和 onvNeXt-T/B 上进行。
研究团队详细阐述了具体的训练细节。在实验中,自动编码器和 LDM 均包含了一个基于 4 层 1D CNN 的编码器和解码器。研究人员默认收集所有架构的 200 个训练数据。 在神经网络 ResNet-18/50 上,他们从头开始训练模型。到了最后一个 epoch 中,他们则继续训练最后两个归一化层并修复其他参数。在大多数情况下,自动编码器和潜在扩散训练可以在单个英伟达的 A100 40G GPU 上于 1~3 小时内完成。
实验过后,研究人员发现,在大多数情况下,p-diff 的方法取得了与两个基线相似或更好的结果,这表明了此方法可以有效地学习高性能参数的分布,并从随机噪声中生成优异的模型。而且,该方法在各种数据集上始终表现良好,也证明了它具有良好的通用性。

那么如何进一步确认p-diff 是否真正可以合成新参数,而不只是在记忆训练样本呢?
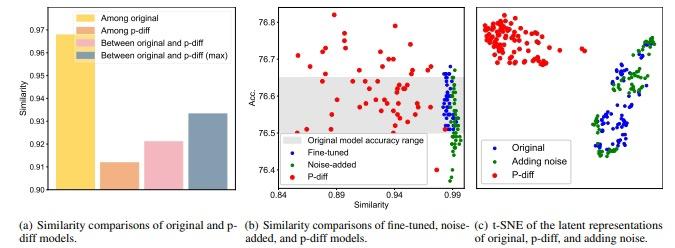
为了验证p-diff 能够生成一些与原始模型表现不同的新参数,研究团队设计了另一个实验,通过比较原始模型、添加噪声模型、微调模型和 p-diff 模型的预测和可视化来研究它们之间的差异。
他们进行了四组对比:1)原始模型之间的相似性; 2)p-diff 模型之间的相似性; 3)原始模型和p-diff 模型之间的相似性; 4) 原始模型和 p-diff 模型之间的最大相似度(最近邻)。
可以发现,在不同情况下,生成的模型之间的差异远大于原始模型之间的差异。 另外,即使是原始模型和生成模型之间的最大相似度,也低于原始模型之间的相似度。这表明,p-diff 的确可以生成与其训练数据表现不同的新参数。
结语
Sora 的平地一声惊雷,让本就火爆的文生图、文生视频的领域又增添了好几分热度,也让在图像和视频生成方面取得了显著成功的扩散模型获得了更多的关注。
而无论是 Sora、DALL·E 、Midjourney,还是 Stable Diffusion 等已经拥有众多用户的模型,它们背后的魔法都是扩散模型。在已有的例子中,扩散模型总是被运用在生成图片或视频上,而这一次,扩散模型居然直接渗入更深层,直接生成神经网络,这堪称机器学习中“用魔法打败魔法”的神操作。
今日,研究团队中的三作 Zhuang Liu 还在社交媒体上答复了网友的疑惑,解释了“Neural Network Diffusion”和 Sora 负责人 William Peebles 此前发布的研究“Learning to Learn with Generative Models of Neural Network Checkpoints”之间的区别:
William Peebles 的研究工作是逐步生成参数,更像是优化器,将先前的检查点作为输入。 “Neural Network Diffusion”则是直接生成整套参数,无需之前的权重作为输入。

尽管研究团队目前尚未解决内存限制、结构设计效率和性能稳定性等问题,但使用扩散模型生成神经网络的创新尝试,让大模型领域的技术边界又向外开拓了一面。
扩散模型未来将会有何发展,让我们拭目以待。






