
北大前沿计算研究中心投稿投稿
量子位公众号 QbitAI
只靠一张物体图片,大语言模型就能控制机械臂完成各种日常物体操作吗?
北大最新具身大模型研究成果ManipLLM将这一愿景变成了现实:
在提示词的引导下,大语言模型在物体图像上直接预测机械臂的操作点和方向。
进而,得以操控机械臂直接玩转各项具体的任务:
例如打开抽屉、冰箱,揭锅盖、掀马桶盖……

作者表示:
该方法利用 LLM 的推理和面对开放世界的泛化能力,成功提升了模型在物体操纵方面的泛化能力。
在仿真和真实世界中,ManipLLM 在各种类别的物体上均取得了令人满意的效果,证明了其在多样化类别物体中的可靠性和适用性。
与谷歌 RT2 等输出机器人本体动作的策略相比(如下图所示),该方法侧重于以物体为中心(Object-centric)的操纵,关注物体本身,从而输出机器人对物体操纵的位姿。

以物体为中心的操纵策略,设计针对物体本身特性的表征,与任务、动作、机器人型号无关。
这样就可以将物体和任务及环境解耦开来,使得方法本身可以适应于各类任务、各类机器人,从而实现面对复杂世界的泛化。
目前,该工作已被CVPR 2024会议接收,团队由北大助理教授、博导董豪领衔。

大模型如何直接操控机械臂?
大多的具身操纵工作主要依赖大语言模型的推理能力来进行任务编排和规划。
然而,鲜有研究探索大语言模型在实现低层原子任务(low-level action)方面的潜力。
因此,该方法致力于探索和激发大语言模型在预测低层原子任务的能力,从而实现对更多类别物体的以物体为中心(object-centric)的通用操纵。
具体而言,通过以下三个学习阶段,ManipLLM 实现了具有泛化能力的以物体为中心的操纵:
1)类别级别(category-level):识别物体类别;
2)区域级别(region-level):预测物体的可操纵性分数(affordance score),反映哪些部位更可能被操纵;
3)位姿级别:预测操作物体的位姿。在训练时,模型只更新适配器模块(adapter),这样既可以保有 LLMs 本身的能力,同时赋予其具身操纵的能力。
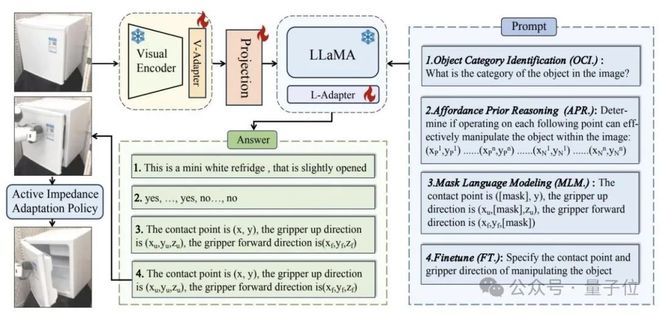
在获得初始接触姿态的输出后,该方法利用一种无需学习的闭环主动式阻抗适应策略,来完成完整的操纵。
它的作用是不断地微调末端执行器的旋转方向,这样就能够灵活地适应物体的形状和轴向,从而逐步地完成对物体的操控任务。
具体来说,我们会在当前方向的周围加入一些微小的变化,生成多个可能的移动方向。
然后我们会试着每个方向轻轻地移动一下,看看哪个方向可以让物体移动最远,然后我们选择这个方向作为下一步的移动方向。
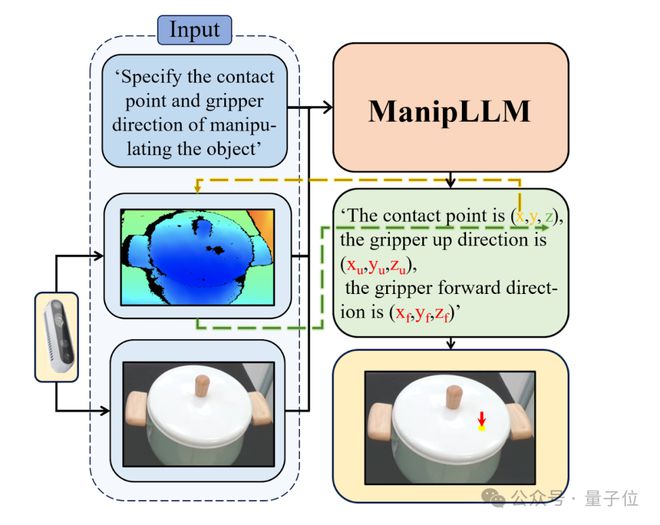
在推理阶段,该模型只需输入两个信息:
1)文本提示:“请指出操纵物体的接触点和夹爪方向。”(Specify the contact point and gripper direction of manipulating the object);
2)一张 RGB 图片。然后,模型就能够输出物体操纵的 2D 坐标和旋转信息。其中,2D 坐标会通过深度图映射到 3D 空间。
更多细节可查看论文原文:
https://arxiv.org/pdf/2312.16217.pdf
和项目主页:






