
新智元报道
编辑:润
来自 UCLA 的华人团队提出一种全新的 LLM 自我对弈系统,能够让 LLM 自我合成数据,自我微调提升性能,甚至超过了用 GPT-4 作为专家模型指导的效果。
合成数据已经成为了大语言模型进化之路上最重要的一块基石了。
在去年底,有网友扒出前 OpenAI 首席科学家 Ilya 曾经在很多场合表示过,LLM 的发展不存在数据瓶颈,合成数据可以解决大部分的问题。

英伟达高级科学家 Jim Fan 在看了最近的一批论文后也认为,使用合成数据,再加上传统用于游戏和图像生成的技术思路,可以让 LLM 完成大幅度的自我进化。

而正式提出这个方法的论文,是由来自 UCLA 的华人团队。

论文地址:https://arxiv.org/abs/2401.01335v1
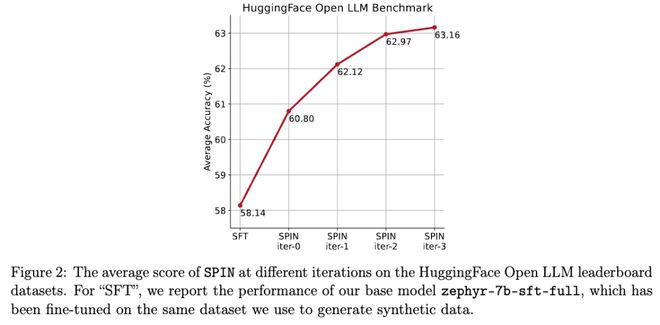
他们通过自我对弈机制(SPIN)生成合成数据,再通过自我微调的方法,不使用新的数据集,让性能较弱的 LLM 在 Open LLM Leaderboard Benchmark 上将平均分从 58.14 提升至 63.16。
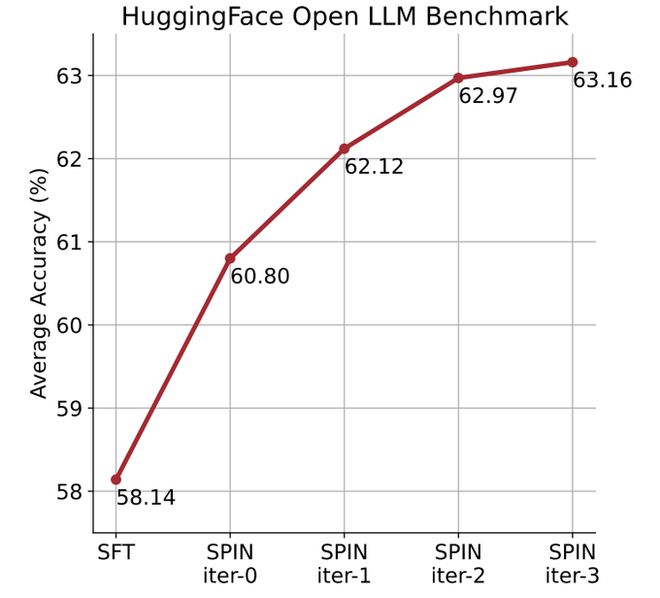
研究人员提出了一种名为 SPIN 的自我微调的方法,通过自我对弈的方式——LLM 与其前一轮迭代版本进行对抗,从而逐步提升语言模型的性能。
这样就无需额外的人类标注数据或更高级语言模型的反馈,也能完成模型的自我进化。
主模型和对手模型的参数完全一致。用两个不同的版本进行自我对弈。
对弈过程用公式可以概括为:
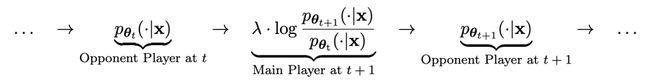
自我对弈的训练方式,总结起来思路大概是这样:
通过训练主模型来区分对手模型生成的响应和人类目标响应,对手模型是轮迭代获得的语言模型,目标是生成尽可能难以区分的响应。
假设第t轮迭代得到的语言模型参数为θt,则在第t+1 轮迭代中,使用θt作为对手玩家,针对监督微调数据集中每个 prompt x,使用θt生成响应y'。
然后优化新语言模型参数θt+1,使其可以区分y'和监督微调数据集中人类响应y。如此可以形成一个渐进的过程,逐步逼近目标响应分布。
这里,主模型的损失函数采用对数损失,考虑y和y'的函数值差。
对手模型加入 KL 散度正则化,防止模型参数偏离太多。
具体的对抗博弈训练目标如公式 4.7 所示。从理论分析可以看出,当语言模型的响应分布等于目标响应分布时,优化过程收敛。
如果使用对弈之后生成的合成数据进行训练,再使用 SPIN 进行自我微调,能有效提高 LLM 的性能。
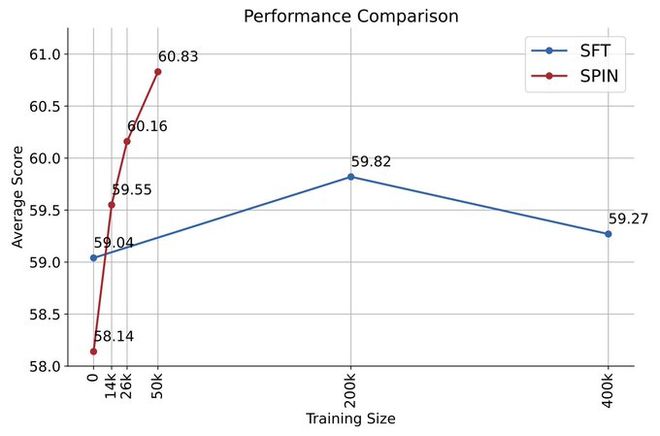
但之后在初始的微调数据上再次简单地微调却又会导致性能下降。
而 SPIN 仅需要初始模型本身和现有的微调数据集,就能使得 LLM 通过 SPIN 获得自我提升。
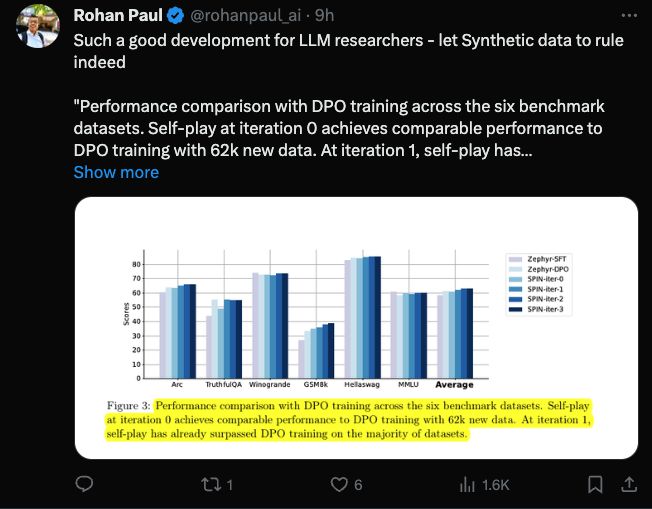
特别是,SPIN 甚至超越了通过 DPO 使用额外的 GPT-4 偏好数据训练的模型。
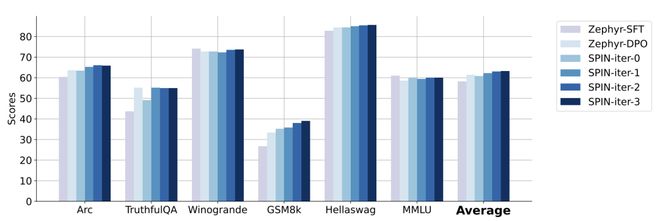
而且实验还表明,迭代训练比更多 epoch 的训练能更加有效地提升模型性能。
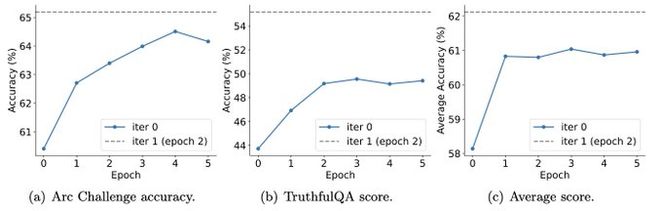
延长单次迭代的训练持续时间不会降低 SPIN 的性能,但会达到极限。
迭代次数越多,SPIN 的效果的就越明显。
网友在看完这篇论文之后感叹:
合成数据将主宰大语言模型的发展,对于大语言模型的研究者来说将会是非常好的消息!
自我对弈让 LLM 能不断提高
具体来说,研究人员开发的 SPIN 系统,是由两个相互影响的模型相互促进的系统。
用表示的前一次迭代t的 LLM,研究人员使用它来生成对人工注释的 SFT 数据集中的提示x的响应y。
接下来的目标是找到一个新的 LLM,能够区分生成的响应y和人类生成的响应y'。
这个过程可以看作是一个两人游戏:
主要玩家或新的 LLM 试图辨别对手玩家的响应和人类生成的响应,而对手或旧的 LLM 生成响应与人工注释的 SFT 数据集中的数据尽可能相似。
通过对旧的进行微调而获得的新 LLM 更喜欢的响应,从而产生与更一致的分布。
在下一次迭代中,新获得的 LLM 成为响应生成的对手,自我对弈过程的目标是 LLM 最终收敛到,使得最强的 LLM 不再能够区分其先前生成的响应版本和人类生成的版本。
如何使用 SPIN 提升模型性能
研究人员设计了个两人游戏,其中主要模型的目标是区分 LLM 生成的响应和人类生成的响应。与此同时,对手的作用是产生与人类的反应无法区分的反应。研究人员的方法的核心是训练主要模型。
首先说明如何训练主要模型来区分 LLM 的回复和人类的回复。
研究人员方法的核心是自我博弈机制,其中主玩家和对手都是相同的 LLM,但来自不同的迭代。
更具体地说,对手是上一次迭代中的旧 LLM,而主玩家是当前迭代中要学习的新 LLM。在迭代t+1 时包括以下两个步骤:(1)训练主模型,(2)更新对手模型。
训练主模型
首先,研究人员将说明如何训练主玩家区分 LLM 反应和人类反应。受积分概率度量(IPM)的启发,研究人员制定了目标函数:
更新对手模型
对手模型的目标是找到更好的 LLM,使其产生的响应与主模型的p数据无异。
实验
SPIN 有效提升基准性能
研究人员使用 HuggingFace Open LLM Leaderboard 作为广泛的评估来证明 SPIN 的有效性。
在下图中,研究人员将经过 0 到 3 次迭代后通过 SPIN 微调的模型与基本模型 zephyr-7b-sft-full 的性能进行了比较。
研究人员可以观察到,SPIN 通过进一步利用 SFT 数据集,在提高模型性能方面表现出了显着的效果,而基础模型已经在该数据集上进行了充分的微调。
在第 0 次迭代中,模型响应是从 zephyr-7b-sft-full 生成的,研究人员观察到平均得分总体提高了 2.66%。
在 TruthfulQA 和 GSM8k 基准测试中,这一改进尤其显着,分别提高了超过5% 和 10%。
在迭代 1 中,研究人员采用迭代 0 中的 LLM 模型来生成 SPIN 的新响应,遵循算法 1 中概述的过程。
此迭代平均产生 1.32% 的进一步增强,在 Arc Challenge 和 TruthfulQA 基准测试中尤其显着。
随后的迭代延续了各种任务增量改进的趋势。同时,迭代t+1 时的改进自然更小
zephyr-7b-beta 是从 zephyr-7b-sft-full 衍生出来的模型,使用 DPO 在大约 62k 个偏好数据上训练而成。
研究人员注意到,DPO 需要人工输入或高级语言模型反馈来确定偏好,因此数据生成是一个相当昂贵的过程。
相比之下,研究人员的 SPIN 只需要初始模型本身就可以。
此外,与需要新数据源的 DPO 不同,研究人员的方法完全利用现有的 SFT 数据集。
下图显示了 SPIN 在迭代 0 和1(采用 50k SFT 数据)与 DPO 训练的性能比较。
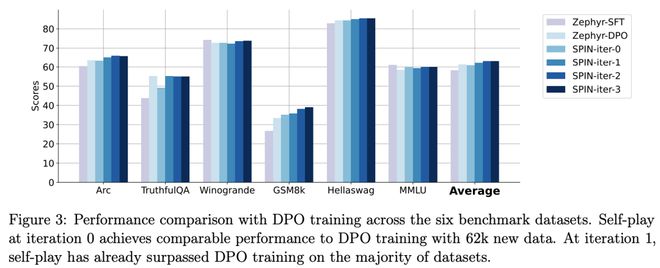
研究人员可以观察到,虽然 DPO 利用了更多新来源的数据,但基于现有 SFT 数据的 SPIN 从迭代 1 开始,SPIN 甚至超过了 DPO 的性能、SPIN 在排行榜基准测试中的表现甚至超过了 DPO。
参考资料:






