
在儿童时期,一个人是怎样学会“第一个单词”的?又是如何把“听到的”和“看到的”的事物联系起来的?
长久以来,尽管人们针对这一话题进行了广泛的讨论,并提出了多种假设,但相关研究结果缺乏对现实世界的普适性。
如今,一种新的人工智能(AI)模型,或许可以给我们提供一些更有说服力的线索。
由纽约大学数据科学中心研究科学家 Wai Keen Vong 领导的研究团队,基于一名儿童(baby S)一年多(从 6 个月到 25 个月)第一视角录制的视频和音频数据,训练了一个多模态人工智能系统——基于儿童视角的对比学习(Child’s View for Contrastive Learning,CVCL)模型,为人类早期语言学习提供了新的见解。

图|6 个月大的 baby S 佩戴着头戴式摄像机。(来源:Wai Keen Vong)
更重要的是,该研究不仅为了解儿童如何学习语言和概念提供了一个有价值的框架,而且对在下一代多模态人工智能系统在语言和视觉表征之间建立联系,以及开发能以更像人类的方式学习语言的人工智能系统至关重要。
相关研究论文以“Grounded language acquisition through the eyes and ears of a single child”为题,已发表在权威科学期刊 Science 上。
“我们首次展示了,根据来自一个儿童的现实生活真实场景输入进行训练的神经网络,可以学会将单词与它们的视觉对应物联系起来,” Vong 说,“我们的研究结果表明,最近的算法进步与一个孩子的自然体验是如何有潜力重塑我们对早期语言和概念获取的理解的。”
“经典争论”有望被解决
尽管 GPT-4 等大模型可以学习和使用人类语言,但它们是从天文数字般的语言输入中学习的,比儿童在学习如何理解和使用一种语言时接受的要多得多,儿童每年只能接收数百万字的文本。
而且,大约在 6-9 个月大时,儿童开始学习第一个单词,便能把听到的单词和看到的事物联系起来。
这就涉及到一个有关儿童学习语言需要哪些要素的经典争论——
儿童在学习语言时能在多大程度上依赖于观察和经验(即通过相对通用的学习机制从感官输入中学习)?
又有多少需要更强的天生或先天学习倾向(即归纳偏见)?
“归纳偏见”(inductive biases)是机器学习和认知科学领域中的一个重要概念,是指算法在学习过程中对某些解决方案的天然偏好或预设倾向。这种偏见影响了算法从数据中归纳和学习的方式,在没有足够多信息的情况下,可以帮助算法做出合理的假设或决策。“归纳偏见”对于算法的有效性至关重要,有助于算法在接收新数据后做出更合理的预测,避免因过于依赖训练数据的特定特征而导致泛化能力变差,即在新数据上表现不佳。
例如,假设一个机器学习模型的任务是根据以往的天气数据预测明天的天气。如果这个模型有归纳偏见,认为天气模式通常是连续的(即今天的天气状况会影响到明天的天气),那么它在做出预测时就会依据这个偏见。
纽约大学数据科学中心和心理学系助理教授、论文作者之一 Brenden Lake 认为,通过使用人工智能模型研究儿童面临的实际语言学习问题,人类或许可以解决关于儿童学习单词所需成分的经典争论。
为此,他们利用安装在 baby S 头部的轻便摄像头,记录了总时长超过 60 小时的第一人称视角学习过程的视频。

这些视频记录了大约 25 万个单词实例(即交流中使用的单词数量,很多都是重复的),这些单词与儿童在听到这些词时所看到的画面相关联,涵盖了从进餐、读书到玩耍等不同阶段的多种活动。
然后,研究团队基于这些数据训练了一个多模态神经网络,即前面提到的 CVCL 模型。
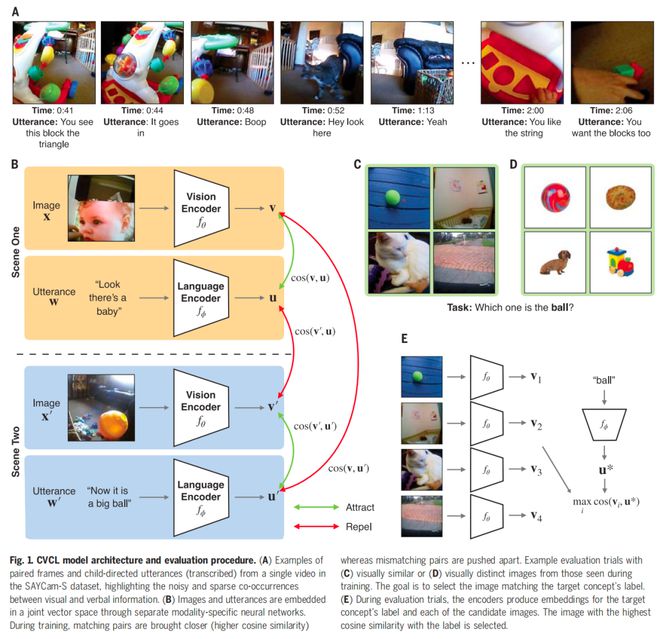
图|CVCL 模型架构和评估程序。(来源:该论文)
据论文描述,CVCL 模型由两个独立的模块组成:视觉编码器处理单帧视频,语言编码器处理转录的面向儿童的语言。两者结合起来,并使用对比学习算法进行训练,从而学习有用的输入特征及其跨模态关联。例如,当父母在儿童面前说话时,使用的某些词很可能指的是儿童能看到的某些东西,也就是通过联系视觉和语言线索来培养理解能力。
然而,令人惊讶的是,基于有限的数据,CVCL 模型真的学会了大量单词和概念。
Vong 解释说:“这为模型提供了关于哪些单词应该与哪些对象关联的线索。结合这些线索,就是对比学习能够逐渐确定哪些词与哪些视觉内容相匹配,并捕捉到孩子学习第一个词的过程的关键。”
针对这一结果,Lake 表示,“看起来,仅通过学习,我们可以获得的东西比通常认为的要多。”
像儿童一样学习
之后,研究团队对 CVCL 模型的训练效果进行了两项评估。
首先,他们采用与评估儿童学习的常用方法来测试模型。结果显示,CVCL 模型能够学会人类儿童日常经验中大量的单词和概念,甚至能够将学到的一些单词泛化到与训练时完全不同的视觉环境中,这与实验室中测试儿童时观察到的现象一致。

然后,他们针对单词-对象的映射质量,也对 CVCL 模型及其他替代模型进行了评估。通过提示模型选择与目标单词匹配的图像,他们发现 CVCL 模型的分类准确度达到了 61.6%。在针对 22 个视觉概念的评估中,CVCL 模型在 11 个概念上的表现接近了同类模型的性能(这些同类模型拥有更大的数据集)。
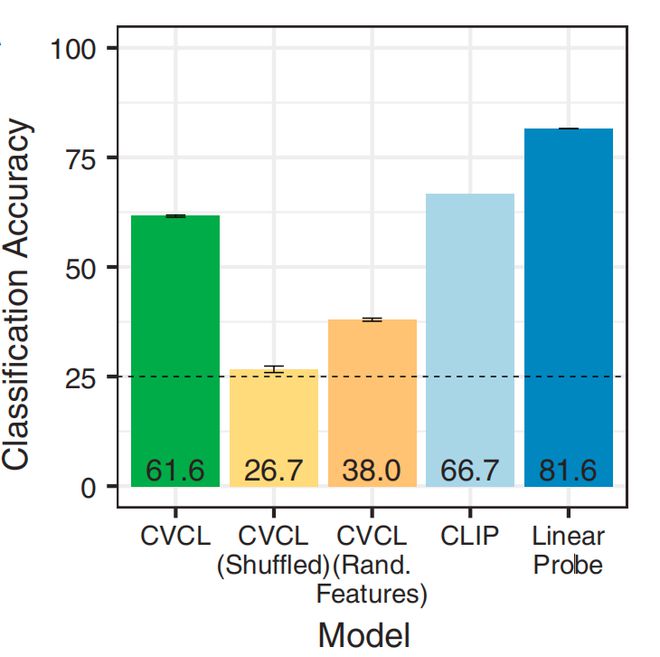
这一研究表明,即便在有限的儿童经验中,使用具有相对通用学习机制的人工智能模型也能够实现重要的单词学习。同时,这一研究为儿童语言学习理论提供了新的视角,强调了学习和交叉情境机制的重要性。
然而,该研究也存在一些局限性,并不能完全概括儿童在后续成长中的学习模式,互斥性、对比原则、形状偏好、句法线索、社交或手势线索以及假设生成等其他因素,都可能发挥作用。而且,研究团队也并未考虑不同儿童的活跃性、具体动作等对学习过程的影响。
只有将这些因素纳入模型或训练过程,系统性地测试它们对单词学习的贡献,才可以更全面地模拟人类幼崽实际的学习过程。
只是一个开始
近年来,除了 CVCL 模型,科学家也开展了一系列有关人工智能系统模仿儿童认知的研究。
例如,2022 年,DeepMind 的深度学习系统 PLATO 受儿童视觉认知启发,以类似儿童的方式学习了物理世界的基本常识性规则。据介绍,通过观看视频,在仅仅 28 个小时内,PLATO 便能够感知并预测物体的行为,展现出对常识性知识的直观理解,表现出对未知物体和动力学的惊人鲁棒性。(点击查看详情)
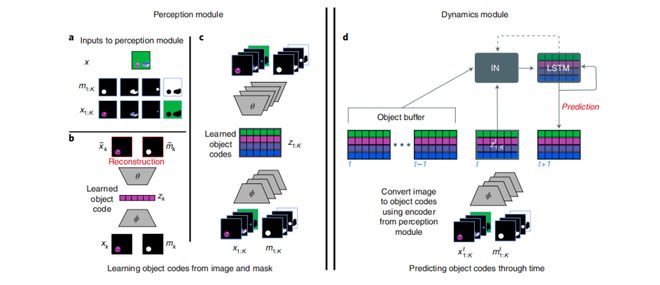
图|PLATO 使用感知模型和动态模型对每个物体进行预测。(来源:Nature Human Behaviour)
此外,研究发现,PLATO 不仅能够将期望概括为一组新的对象和事件,还能在相对小的数据集上成功演示学习。这些发现,与科学家此前在儿童研究中看到的特征相似。
以上成功案例表明,即使在有限的情境中,通过结合表示学习和联想学习两种机制,人工智能也能在语言学习方面取得重大进展。
那么,未来的人工智能最终是否可以完全像人一样思考呢?
按照人工智能之父 Alan Turing 在 1950 年的说法,如果从学习儿童的思维开始,并接受适当的经验,计算机就可以像成年人一样思考。
“与其尝试制作一个模拟成人思维的程序,为何不尝试制作一个模拟儿童思维的程序呢?”
或许这些研究,只是一个好的开始。






