
新智元报道
编辑:LRS
使用 LLM 生成海量任务的文本数据,无需人工标注即可大幅提升文本嵌入的适用度,只需 1000 训练步即可轻松扩展到 100 种语言。
文本嵌入(word embedding)是自然语言处理(NLP)领域发展的基础,可以将文本映射到语义空间中,并转换为稠密的矢量,已经被广泛应用于各种自然语言处理(NLP)任务中,如信息检索(IR)、问答、文本相似度计算、推荐系统等等,
比如在 IR 领域,第一阶段的检索往往依赖于文本嵌入来进行相似度计算,先在大规模语料库中召回一个小的候选文件集,再进行细粒度的计算;基于嵌入的检索也是检索增强生成(RAG)的关键组成部分,使大型语言模型(LLM)可以访问动态的外部知识,而无需修改模型参数。
早期的文本嵌入学习方法如 word2vec,GloVe 等大多是静态的,无法捕捉自然语言中丰富的上下文信息;随着预训练语言模型的出现,Sentence-BERT 和 SimCSE 等方法在自然语言推理(NLI)数据集上通过微调 BERT 来学习文本嵌入。
为了进一步增强文本嵌入的性能和鲁棒性,最先进的方法如 E5 和 BGE 采用了更复杂的多阶段训练范式,先对数十亿个弱监督文本对进行预训练,然后再在数个标注数据集上进行微调。
现有的多阶段方法仍然存在两个缺陷:
1. 构造一个复杂的多阶段训练 pipeline,需要大量的工程工作来管理大量的相关性数据对(relevance pairs)。
2. 微调依赖于人工收集的数据集,而这些数据集往往受到任务多样性和语言覆盖范围的限制。
3. 大多数现有方法采用 BERT-style 的编码器作为主干,忽略了训练更好的 LLM 和相关技术(诸如上下文长度扩展)的最新进展。
最近,微软的研究团队提出了一种简单且高效的文本嵌入训练方法,克服了上述方法的缺陷,无需复杂的管道设计或是人工构建的数据集,只需要利用 LLM 来「合成多样化的文本数据」,就可以为为近 100 种语言的数十万文本嵌入任务生成高质量的文本嵌入,整个训练过程还不到 1000 步。

论文链接:https://arxiv.org/abs/2401.00368
具体来说,研究人员使用两步提示策略,首先提示 LLM 头脑风暴候选任务池,然后提示 LLM 从池中生成给定任务的数据。
为了覆盖不同的应用场景,研究人员为每个任务类型设计了多个提示模板,并将不同模板生成的数据进行联合收割机组合,以提高多样性。
实验结果证明,当「仅对合成数据」进行微调时,Mistral-7B 在 BEIR 和 MTEB 基准上获得了非常有竞争力的性能;当同时加入合成和标注数据进行微调时,即可实现 sota 性能。
用大模型提升文本嵌入
1. 合成数据生成
利用 GPT-4 等最先进的大型语言模型(LLM)来合成数据越来越受到重视,可以增强模型在多任务和多语言上的能力多样性,进而可以训练出更健壮的文本嵌入,在各种下游任务(如语义检索、文本相似度计算、聚类)中都能表现良好。
为了生成多样化的合成数据,研究人员提出了一个简单的分类法,先将嵌入任务分类,然后再对每类任务使用不同的提示模板。
非对称任务(Asymmetric Tasks)
包括查询(query)和文档在语义上相关但彼此不互为改写(paraphrase)的任务。
根据查询和文档的长度,研究人员进一步将非对称任务分为四个子类别:短-长匹配(短查询和长文档,商业搜索引擎中的典型场景),长-短匹配,短-短匹配和长-长匹配。
对于每个子类别,研究人员设计了一个两步提示模板,首先提示 LLM 头脑风暴的任务列表,然后生成一个具体的例子的任务定义的条件;从 GPT-4 的输出大多连贯一致,质量很高。

在初步实验中,研究人员还尝试使用单个提示生成任务定义和查询文档对,但数据多样性不如上述的两步方法。
对称任务
主要包括具有相似语义但不同表面形式的查询和文档。
文中研究了两个应用场景:单语种(monolingual)语义文本相似性(STS)和双文本检索,并且为每个场景设计了两个不同的提示模板,根据其特定目标进行定制,由于任务的定义比较简单,所以头脑风暴步骤可以省略。
为了进一步提高提示词的多样性,提高合成数据的多样性,研究人员在每个提示板中加入了几个占位符,在运行时随机采样,例如「{query_length}」代表从集合「{少于 5 个单词,5-10 个单词,至少 10 个单词}」中采样的。
为了生成多语言数据,研究人员从 XLM-R 的语言列表中采样「{language}」的值,给予高资源语言更多的权重;任何不符合预定义 JSON 格式的生成数据都将在解析过程中被丢弃;还会根据精确的字符串匹配删除重复项。
2. 训练
给定一个相关的查询-文档对,先使用原始查询q+ 来生成一个新的指令q_inst,其中「{task_definition}」是嵌入任务的一句话描述的占位符。
对于生成的合成数据,使用头脑风暴步骤的输出;对于其他数据集,例如 MS-MARCO,研究人员手动创建任务定义并将其应用于数据集中的所有查询,不修改文件端的任何指令前缀。
通过这种方式,可以预先构建文档索引,并且可以通过仅更改查询端来自定义要执行的任务。
给定一个预训练的 LLM,将一个[EOS]标记附加到查询和文档的末尾,然后馈送到 LLM 中,通过获取最后一层[EOS]向量来获得查询和文档嵌入。
然后采用标准的 InfoNCE loss 对批内 negatives 和 hard negatives 进行损失计算。
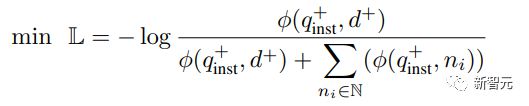
其中ℕ表示所有 negatives 的集合,用来计算查询和文档之间的匹配分数,t是一个温度超参数,在实验中固定为 0.02
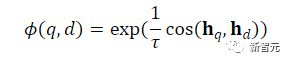
实验结果
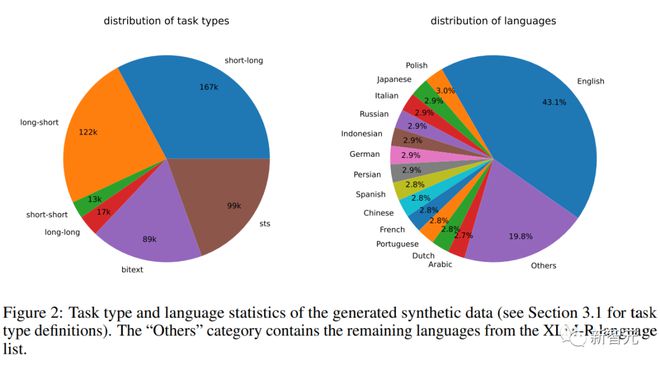
合成数据统计
研究人员使用 Azure OpenAI 服务生成了 500k 个样本,包含 150k 条独特指令,其中 25% 由 GPT-3.5-Turbo 生成,剩余由 GPT-4 生成,总共消耗了 1.8 亿个 token。
主要语言是英语,一共覆盖 93 种语言;对于 75 种低资源语言,平均每种语言约有 1k 个样本。
在数据质量方面,研究人员发现 GPT-3.5-Turbo 的部分输出没有严格遵循提示模板中规定的准则,但尽管如此,总体质量仍然是可以接受的,初步实验也证明了采用这一数据子集的好处。
模型微调和评估
研究人员对预训练 Mistral-7B 使用上述损失微调 1 个 epoch,遵循 RankLLaMA 的训练方法,并使用秩为 16 的 LoRA。
为了进一步降低 GPU 内存需求,采用梯度检查点、混合精度训练和 DeepSpeed ZeRO-3 等技术。
在训练数据方面,同时使用了生成的合成数据和 13 个公共数据集,采样后产生了约 180 万个示例。
为了与之前的一些工作进行公平比较,研究人员还报告了当唯一的标注监督是 MS-MARCO 篇章排序数据集时的结果,还在 MTEB 基准上对模型进行了评估。
主要结果
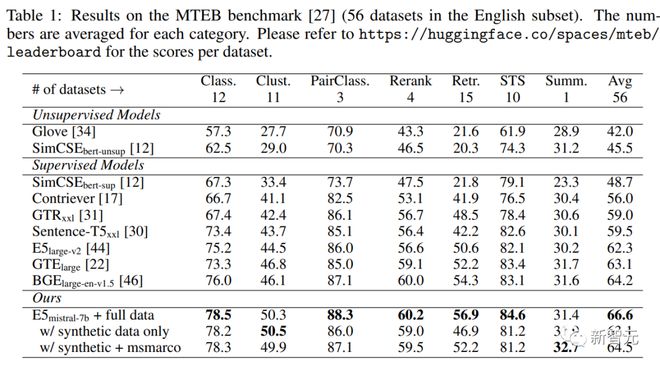
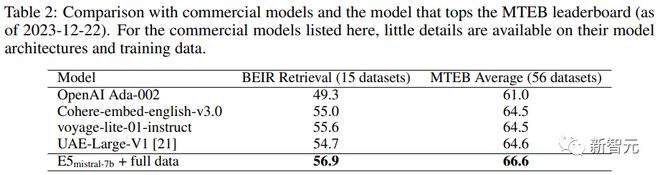
下表中可以看到,文中得到的模型「E5mistral-7B + full data」在 MTEB 基准测试中获得了最高的平均分,比之前最先进的模型高出 2.4 分。
在「w/ synthetic data only」设置中,没有使用标注数据进行训练,但性能仍然很有竞争力。
研究人员还对几种商业文本嵌入模型进行了比较,但由于这些模型缺乏透明度和文档,因此无法进行公平的比较。
不过,在 BEIR 基准上的检索性能对比结果中可以看到,训练得到的模型在很大程度上优于当前的商业模型。
多语言检索
为了评估模型的多语言能力,研究人员在 MIRACL 数据集上进行了评估,包含 18 种语言的人工标注查询和相关性判断。
结果显示,该模型在高资源语言上超过了 mE5-large,尤其是在英语上,性能表现更出色;不过对于低资源语言来说,该模型与 mE5-base 相比仍不理想。
研究人员将此归因于 Mistral-7B 主要在英语数据上进行了预训练,预测多语言模型可以用该方法来弥补这一差距。
参考资料:






