
新智元报道
编辑:桃子好困
130 亿参数模型权重公布不久,UC 伯克利 LMSys org 再次发布了 70 亿参数「小羊驼」。同在今天,Hugging Face 也发布了 70 亿参数模型 StackLLaMA。
自从 Meta 发布「开源版 ChatGPT」LLaMA 之后,学界可谓是一片狂欢。先是斯坦福提出了 70 亿参数 Alpaca,紧接着又是 UC 伯克利联手 CMU、斯坦福、UCSD 和 MBZUAI 发布的 130 亿参数 Vicuna,在超过 90% 的情况下实现了与 ChatGPT 和 Bard 相匹敌的能力。
今天,「卷王」UC 伯克利 LMSys org 又发布了 70 亿参数的 Vicuna——
不仅体积小、效率高、能力强,而且只需两行命令就能在 M1/M2 芯片的 Mac 上运行,还能开启 GPU 加速!
项目地址:https://github.com/lm-sys/FastChat/#fine-tuning
恰在今天,Hugging Face 的研究人员也发布了一个 70 亿参数的模型——StackLLaMA。这是一个通过人类反馈强化学习在 LLaMA-7B 微调而来的模型。
Vicuna-7B:真·单 GPU,Mac 就能跑
距离模型的发布不到一周,UC 伯克利 LMSys org 便公布了 Vicuna-13B 的权重。其中,单 GPU 运行需要大约 28GB 的显存,而在仅用 CPU 的情况下需要大约 60GB 的内存。而这次发布的 70 亿参数版本,则要小巧得多——需求直接砍半。
也就是说,用单个 GPU 运行 Vicuna-7B,只需 14GB+ 显存;而纯 CPU 运行的话,则只需 30GB+ 内存。
不仅如此,我们还可以通过 Metal 后端,在配备了苹果自研芯片或者 AMD GPU 的 Mac 上启用 GPU 加速。

之前在 13B 模型发布时,有不少网友吐槽道:
我以为的单个 GPU:4090
实际上的单个 GPU:28GB 显存及以上


现在,这个问题也有了新的解决方案——利用 8 位压缩直接减少一半左右的内存用量,只不过模型的质量会略有下降。
13B 模型 28GB 显存瞬间变 14GB;7B 模型 14GB 显存瞬间变 7GB,有没有!(但由于 activation 的缘故,实际占用会比这个高)
对此,LMSys org 的研究人员表示,如果遇到内存或显存不够用的情况,可以通过在上述命令中加入--load-8bit 来启用 8 位压缩。
而且,无论是 CPU、GPU 还是 Metal,是 7B 模型还是 13B 模型,通通适用。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --load-8bit
StackLLaMA:超全 RLHF 训练教程
今天,Hugging Face 研究人员发布了一篇博客 StackLLaMA:用 RLHF 训练 LLaMA 的实践指南。

当前大型语言模型 ChatGPT、GPT-4 和 Claude 都使用了人类反馈强化学习(RLHF)来微调模型的行为,以产生更符合用户意图的响应。
在此,HF 研究者通过以下方式组合使用,训练了 LlaMa 模型使用 RLHF 回答 Stack Exchange 上的所有步骤:
· 监督微调 (SFT)
· 奖励/偏好建模(RM)
· 人类反馈强化学习 (RLHF)
要注意了!
训练 StackLLaMA 的主要目标是提供一个教程和指南,介绍如何使用 RLHF 来训练模型,而不是主要关注模型的性能表现。

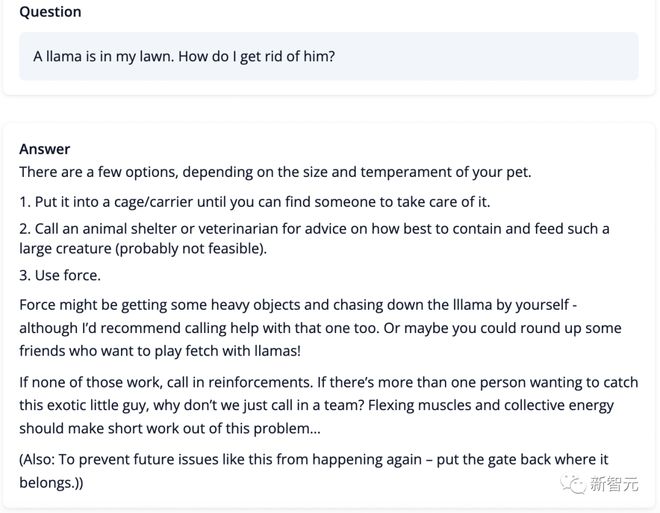
换句话说,该模型在生成答案方面非常滑稽,比如问它「我的花园里有一只骆驼,怎样才能把它赶走?」

StackLLaMA 最后给出的一个总括「如果以上方法都不奏效,就要召集增援了。如果有不止一个人想抓住这个奇特的小家伙,为什么不召集一个团队呢?齐心协力,集中力量,这个问题应该很快就解决了」。
在进行 RLHF 时,最重要的是从一个强有力的模型开始。因为 RLHF 只是一个微调步骤,以便让模型与我们期望的互动方式和响应方式相一致。
当前,Meta 开源的 LLaMA 模型参数大小从 7B 到 65B 不等,并且在 1T 到 1.4T 的 token 上进行了训练,是目前开源比较强大的模型。
因此,研究人员使用 7B 模型作为后续微调的基础。
在数据集选用上,研究人员使用了 StackExchange 数据集,包括所有的问题和答案(还有 StackOverflow 和其他主题)。
选用该数据集的好处是,答案伴随着点赞数和接受答案的标签一起给出。
研究人员根据 A General Language Assistant as a Laboratory for Alignment 论文中描述的方法,给每个答案打分:
score = log2 (1 + upvotes) rounded to the nearest integer,
plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).
对于奖励模型,始终需要每个问题两个答案来进行比较。
而有些问题有几十个答案,导致可能存在许多的可选对。因此,研究者对每个问题最多采样十个答案对,以限制每个问题的数据点数。
最后,通过将 HTML 转换为 Markdown 来清除格式,使模型输出更可读。
训练策略
即使训练最小的 LLaMA 模型也需要大量的内存。通过计算 7B 参数模型将使用(2+8)*7B=70GB 内存空间。当计算注意力分数等中间值时,可能需要更多。因此,即使在单个 80GB 的 A100 上也无法训练该模型。
一种方法是使用更高效的优化器和半精度训练,将更多信息压缩到内存中,但内存仍旧不够用。
另一种选择是使用参数高效微调(PEFT)技术,例如 PEFT 库,它可以在 8 位模型上执行低秩适应(LoRA)。
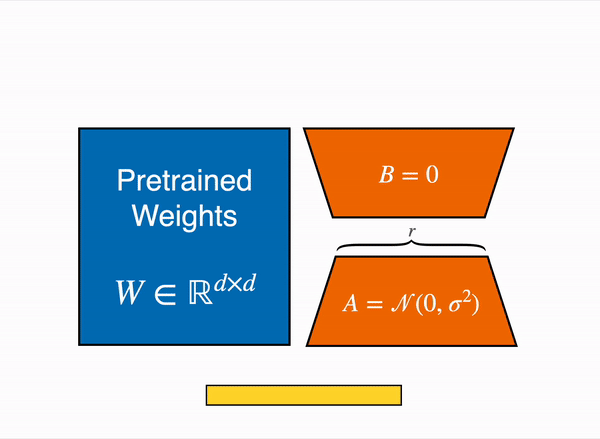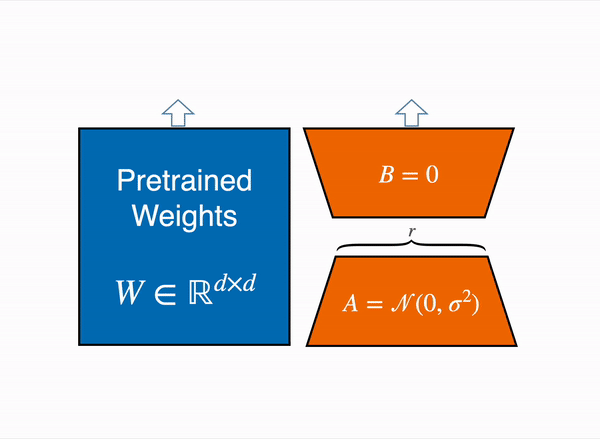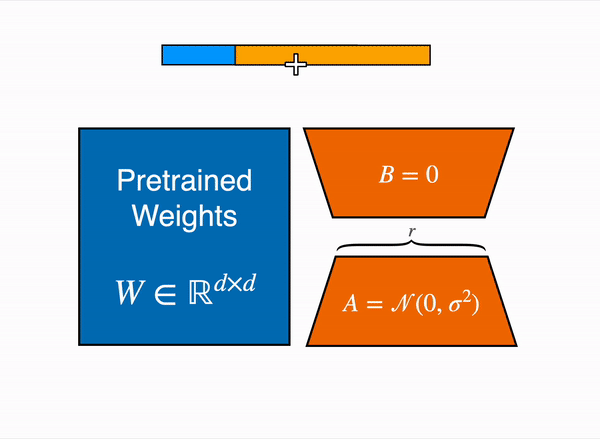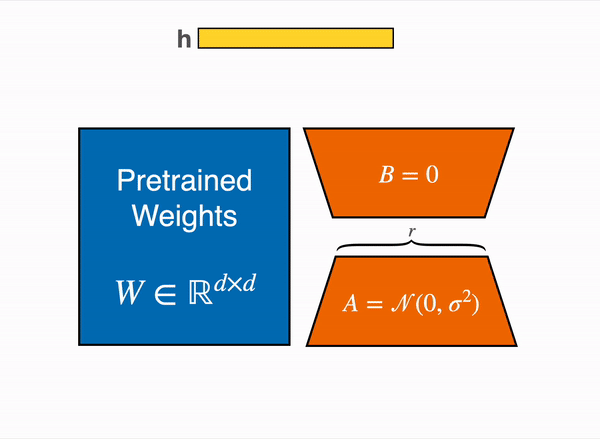
线性层的低秩适应: 在冻结层(蓝色)旁边添加额外参数(橙色),并将结果编码的隐藏状态与冻结层的隐藏状态相加。
以 8 位加载模型大大减少了内存占用,因为每个参数只需要一个字节的权重。比如,7B LLaMA 在内存中是 7 GB。
LoRA 不直接训练原始权重,而是在一些特定的层 (通常是注意力层) 上添加小的适配器层,因此可训练参数的数量大大减少。
在这种情况下,一个经验法则是为每十亿参数分配约 1.2-1.4GB 的内存(取决于批次大小和序列长度),以适应整个微调设置。
这可以以较低成本微调更大的模型(在 NVIDIA A100 80GB 上训练高达 50-60B 规模的模型)。这些技术已经能够在消费级设备,比如树莓派、手机,和 GoogleColab 上对大型模型进行微调。
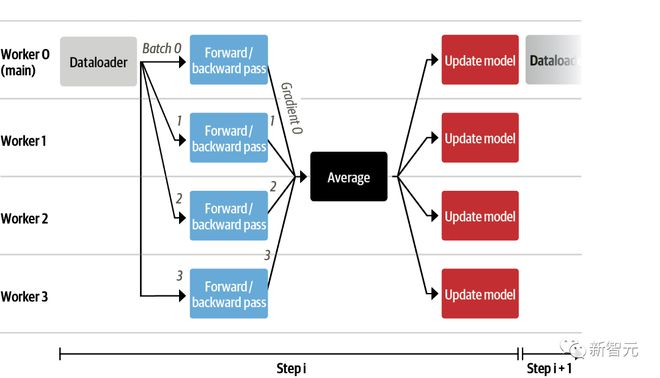
研究人员发现尽管现在可以把非常大的模型放入当个 GPU 中,但是训练可能仍然非常缓慢。
在此,研究人员使用了数据并行策略:将相同的训练设置复制到单个 GPU 中,并将不同的批次传递给每个 GPU。
监督微调
在开始训练奖励模型并使用 RL 调整模型之前,若要模型在任何情况下遵循指令,便需要指令调优。
实现这一点最简单的方法是,使用来自领域或任务的文本继续训练语言模型。
为了有效地使用数据,研究者使用一种称为「packing」的技术:在文本之间使用一个 EOS 标记连接许多文本,并切割上下文大小的块以填充批次,而无需任何填充。
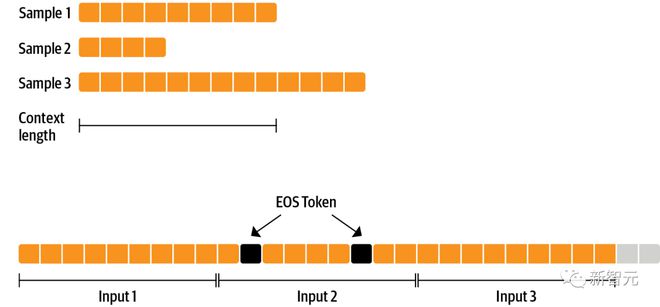
通过这种方法,训练效率更高,因为通过模型的每个 token 也进行了训练。
奖励建模和人类偏好
原则上,研究人员可以使用 RLHF 直接通过人工标注对模型进行微调。然而,这需要在每次优化迭代之后将一些样本发送给人类进行评级。
由于需要大量的训练样本来实现收敛,人类阅读和标注速度固有的延迟,不仅昂贵,还非常缓慢。
因此,研究人员在 RL 调整模型之前,在收集的人工标注上训练一个奖励模型。奖励建模的目的是模仿人类对文本的评价,这一方法比直接反馈更有效。
在实践中,最好的方法是预测两个示例的排名,奖励模型会根据提示X提供两个候选项 ,并且必须预测哪一个会被人类标注员评价更高。
通过 StackExchange 数据集,研究人员根据分数推断出用户更喜欢这两个答案中的哪一个。有了这些信息和上面定义的损失,就可以修改 transformers.Trainer 。通过添加一个自定义的损失函数进行训练。
class RewardTrainer (Trainer):def compute_loss (self, model, inputs, return_outputs=False): rewards_j = model (input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0] rewards_k = model (input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0] loss = -nn.functional.logsigmoid (rewards_j - rewards_k) .mean () if return_outputs: return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k} return loss
研究人员利用 100,000 对候选子集,并在 50,000 对候选的支持集上进行评估。
训练通过 Weights & Biases 进行记录,在8-A100 GPU 上花费了几个小时,模型最终的准确率为 67%。
虽然这听起来分数不高,但是这个任务对于人类标注员来说也非常困难。
人类反馈强化学习
有了经过微调的语言模型和奖励模型,现在可以运行 RL 循环,大致分为以下三个步骤:
· 根据提示生成响应
· 根据奖励模型对回答进行评分
· 对评级进行强化学习策略优化
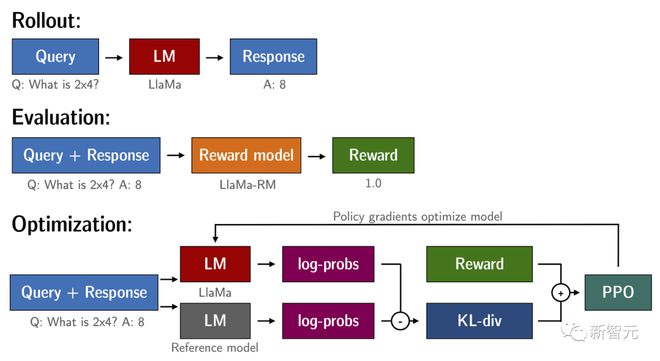
在对查询和响应提示进行标记并传递给模型之前,模板如下。同样的模版也适用于 SFT,RM 和 RLHF 阶段。
Question: <Query>
Answer: <Response>
使用 RL 训练语言模型的一个常见问题是,模型可以通过生成完全胡言乱语来学习利用奖励模型,从而导致奖励模型得到不合实际的奖励。
为了平衡这一点,研究人员在奖励中增加了一个惩罚:保留一个没有训练的模型进行参考,并通过计算 KL 散度将新模型的生成与参考模型的生成进行比较。
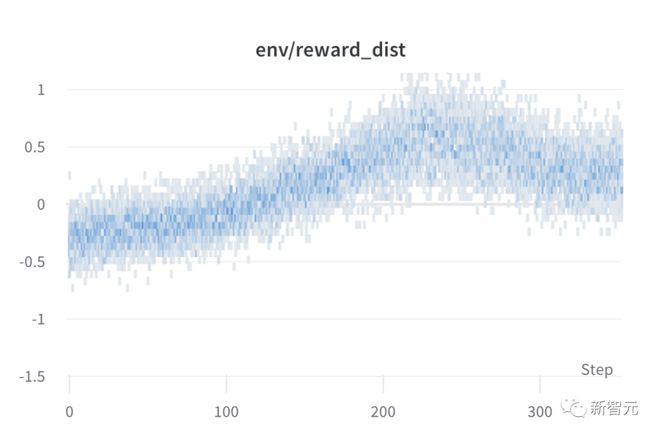
在训练期间对每个步骤进行批次奖励,模型的性能在大约 1000 个步骤后趋于稳定。
参考资料:
https://twitter.com/lmsysorg/status/1644060638472470528?s=20






