
新智元报道
编辑:Aeneas 好困
Runway 的 Gen-1 还没内测完,Gen-2 就以迅雷不及掩耳之势发布了。这次的效果更加炸裂,AI 大导离淘汰人类,又近了一步。
昨天,Midjourney 生成的完美情侣刷爆网络,大家纷纷在留言区里畅想,下一步,就是演员被淘汰,人人都能升级大导,一键生成大电影了。
巧得很,今天,会做视频的 AI 模型不就来了嘛。
刚刚,仿佛一声惊雷炸响,Runway 发布了文字生成视频模型 Gen-2。
宣传词也是非常炸裂——「say it,see it」,只要你说得出来,它就能给你做出来。科幻小说里的超能力成真了!
可以说,有了 Runway Gen-2,你就能用任意的图像、视频或文本,生成一段酷炫大片,想要啥风格,就有啥风格。

这个速度简直让人目瞪口呆:Gen-1 的内测都还没拿到呢,Gen-2 就来了!

一句话,一张图,三秒视频无中生有
此前,Runway 在文本到图像领域就曾经大放异彩,大名鼎鼎的 Stable Diffusion,就是 Runway 开发的。
在今年 2 月,Runway 就提出了首个 AI 编辑模型 Gen-1。
顾名思义,Gen-1 可以在原视频的基础上,编辑出咱们想要的视频。无论是粗糙的 3D 动画,还是用手机拍出来的摇摇晃晃的视频,Gen-1 都可以升级出一个不可思议的效果。
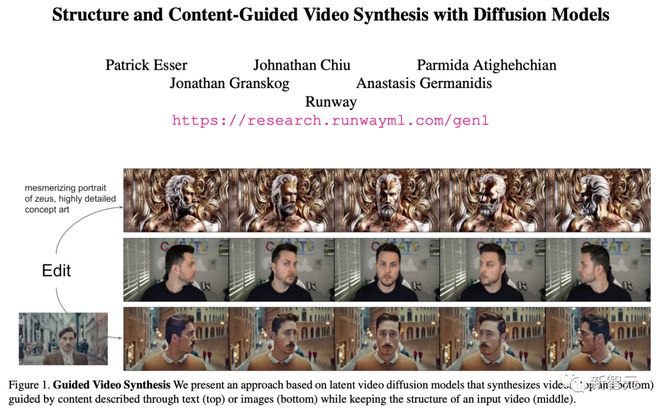
论文地址:https://arxiv.org/abs/2302.03011
比如用几个包装盒,Gen-1 就可以生成一个工厂的视频,化腐朽为神奇,就是这么简单。

而相比 Gen-1,Gen-2 获得了史诗级的升级——可以从头开始生成视频。

目前,这个模型还未开放,预计在几周内会公开。
而根据目前的演示片段看来,Gen-2 的效果似乎暂时比不上 Gen-1,没有那么逼真。
但是,这毕竟是 AI 文生视频 0 到 1 的第一步。AI 导演做到这一步,已经够人类颤抖的了。

网友实测,效果炸裂
而获得内测资格的幸运网友,已经开始动手生成自己的电影了。
可以看出,无论是宫崎骏风格的日系动画,还是写实风格的镜头特写,或者魔幻特效的电影大片,Gen-2 都不在话下。




虽然目前的画质可能还不够细腻,但毕竟是从 0 生成的视频,一旦日后优化好,大导们的饭碗怕是捧不稳了。
Gen-2 的八大「魔法」
Mode 01:Text to Video(文字生成视频)
一个文本提示,就能合成出任意风格的视频,不怕它生不出来,只怕你想不到。
提示:
在纽约市的一间阁楼里,傍晚的阳光透过窗户温柔地洒进屋内。
输出:

Mode 02:Text + Image to Video(文字+图像生成视频)
输入一幅图,再加一句 prompt,直接就给你变成了视频。
输入图像:

驱动提示:
在一个低角度拍摄的画面中,男子正沿着街道行走,周围酒吧的霓虹灯照亮了他的身影。
输出:

Mode 03:Image to Video(图像生成视频)
这个不用解释了,你给它一张图片,它给你秒变一段视频。多种风格,随你选择。
美图一秒变电影,这也太梦幻了吧。
输入图像:

输出:

Mode 04:Stylization(风格化)
如果你有一段原视频,但是效果不够炸裂,怎么办?
只需要把你想要叠加的风格用图片或者文字叠加上去,多魔幻的风格都立马生成,秒变好莱坞大片。
原始视频:

驱动图像:

输出:

Mode 05:Storyboard(故事版)
将模拟的场景一拉,就变成了风格化和动画化的渲染图,前期制作一键简化。
输出&输出对比:

Mode 06:Mask(掩码)
在你的视频中分离出特定的对象,然后通过 prompt,想怎么改就怎么改,比如下图中,金毛秒变斑点狗。
输入视频:

驱动提示:
一只身上有黑色斑点的白毛狗。
输出:

Mode 07:Render(渲染)
只要输入图像或提示,无纹理的渲染立马变成现实的输出,深度和真实感震撼人心。
输入视频:

输出:

Mode 08:Customization(个性化)
通过自定义,让原视频个性化大变身,保真度还超高。
点击就看外国小哥秒变海龟人。
输入&输出对比:

训练图像:


从生成结果来看,Gen-2 的前景,实在是太令人着迷了。(Gen-1 的内测申请在这里,http://t.cn/A6Cu1cdy)。
虽然 Meta 和谷歌也有类似的文本到视频模型(Make-a-Video 和 Phenaki),生成的剪辑更长、更连贯。
但这些体量更大的公司并没有投入多大的资源,相比之下,Runway 的团队只有区区 45 人。
其实,Runway 自 2018 年以来,就一直专注于研究 AI 工具,并在去年年底筹集了 5000 万美元。
有趣的是,Stable Diffusion 的初始版本,就有 Runway 的贡献。只不过后来被 Stability AI 普及,并有了更进一步的发展。
而这也告诉我们,初创公司在生成式 AI 上的潜力,是多么惊人。
一大波展示

提示:一只眼睛的特写镜头

提示:无人机拍摄的沙漠景观











参考资料:
https://research.runwayml.com/gen2
https://www.theverge.com/2023/3/20/23648113/text-to-video-generative-ai-runway-ml-gen-2-model-access






