
新智元报道
编辑:LRS
你想不想给自己来个 AI 克隆?
在 AI 技术愈发成熟的今天,换脸、模仿声音和口型等几乎无所不能,在未来的元宇宙世界,「AI 克隆」或许会成为每个人的标配。
最近刚从纽约大学本科毕业的向舒锦(Chloe Xiang)分享了她录制自己的数字化身的完整过程,她的现实身份是作家、摄影师、记者,主要关注人工智能伦理和技术等。

克隆一个自己
去年 11 月,一家名为 Synthesia 的公司提供了一次「与你的 AI 孪生进行独家约会」的机会,发言人 Laura Morelli 在电子邮件中嵌入的一段视频中表示「名额有限,欲购从速」。
我有点犹豫。
总有一天,我会死去,但是一个看起来和听起来都像我的人工智能却不会(假设这项服务还在线的话),并且理论上,Synthesia 也可以用 AI 孪生来说一些我不同意的事情。
但我也很好奇,我想知道化身(avatar)到底意味着什么:一个可以面对相机不会胆怯的自己?还是时刻准备着上镜的自己?
Morelli 在视频中接着说,新闻从业者大部分时间都处于忙碌状态,来个数字孪生帮你解决一部分工作,怎么样?
这句话打动了我,也许我的人工智能孪生能让我的「工作轻松点」;或者更进一步,也许有一天它可以「主持我自己的葬礼」,我决定试一试!
想要创建一个孪生,Synthesia 需要先克隆我的声音和身体,总共需要大约两个多小时,具体的流程是「声音克隆」、「设计发型及化妆」和「视频表演」。
进入演播室的时候,我不知道该期待什么,感觉就像一个女演员在等待通告表(call sheet),时刻准备着做一次最好的即兴表演。
此前,我看到的大多数人工智能克隆都只是我们熟知的名人的网络视频中,比如奥巴马说「屠杀是对的」,或者马克 · 扎克伯格说「谁控制了数据,谁就控制了未来」,看起来人工智能技术的应用就是让别人说一些他们想让他们说的话。
Synthesia 在宣传中表示自己曾制造过贝克汉姆和梅西的数字孪生,超过 15,000 家企业使用他们提供的 SAAS (software as a service, 软件即服务)平台生成了超过 450 万个视频。
Synthesia 的一要客户使用这个平台的目的包括为企业创建房地产旅游和人力资源培训视频,使用该平台的公司包括埃森哲(Accenture)、路透社(Reuters)和英国广播公司(BBC)。
Synthesia 上过许多头条新闻,很多人都在平台上制作过宣传视频:比如今年 1 月,有人利用 Synthesia 制作视频表达对 Burkina Faso 新军事独裁的支持,不久之后该用户就被禁用了。

还有一些关于委内瑞拉经济改善的虚假内容的 Synthesia 视频开始在 YouTube 和 TikTok 上成为热门话题。
Synthesia 公司首席执行官 Victor Riparbelli 对此表示,「此类案件也突显出审核是多么困难。没有一个系统是完美的,但是为了避免类似的情况在未来出现,我们将继续努力改进系统。」
Synthesia 的在线工作室提供超过 85 个会说 120 多种语言的虚拟人物,这些数字化身几乎可以说任何用户想让他们说的话。
在拍摄过程中,我最担心的是我的数字化神会被用于不恰当的目的,或者说一些我并不认同的话,但是 Synthesia 团队向我保证,只有我自己才能使用我的数字化身。
克隆过程
在 Gramercy Park 工作室里,我创建了自己的数字克隆。
Synthesia 团队首先把我带到一个录音棚,然后给了我一个脚本:总共有八页长,按照不同的语气(tone)排序,比如专业场景、市场营销、指导、休闲和娱乐等。
工作人员表示,这些脚本有可能是由 ChatGPT 编写的。
我对自己必须阅读的内容感到震惊,并且不认为自己能够在规定的时间内完成所有的阅读,我也怀疑自己是否有能力读那么多内容而不结巴或搞砸。
走进录音棚后,我可以看到音频工程师和 Synthesia 团队在玻璃的另一边,但只能通过耳机听到我的声音和环境声,能清楚地听到裤子的沙沙声到脚的敲击声。
脚本被放置在我面前的乐谱架上,以防止纸张发出任何声音。
当我们开始录音的时候,我尽力调动每一种语气,比如从一个有声读物旁白变成一个商业推销员;每次记录下一个段落,每一段都必须完美地读完,才能到下一段的录制。
音频工程师要求我重新朗读每一段录音,直到把纸上所有的单词都读完,要求我的发音正确,说话速度也不太快。
到最后,我已经口干舌燥,迫切需要大口喝水。

克隆身体
接下来是发型和化妆。
化妆师问我每天化什么妆,做什么发型,关键是要要强化拍摄时的自然特征。
Synthesia 团队之前还要求我穿最基本款的、无图案且无反光的衣服,所以我选择了一套全黑的衣服,感觉是为人工智能化身准备的一样。
和现有的人工智能化身一样,我希望我的化身是商务休闲且多才多艺的,能够随时准备谈论包括从休闲到严肃的所有话题。
身体克隆是在一个电影工作室里完成的,我站在一个绿色屏幕前的指定位置,面对着巨大的明亮的灯光。
我的 bra 里藏着一个麦克风,面对着一整个摄制组,包括导演、摄影师、美发师和混音师,这也是我第一次站在摄像机的另一边。
当所有的目光都聚焦在我身上时,我感到很害怕,因为我知道,在某种程度上,大家期望我的「表演」能够将面部表情、声音的语调和身体的动作结合成一个流畅的录像。
导演让我先朝时钟的每个方向点头,比如在 12 点钟直接向上看,然后在 11 点钟方向稍微向左看,以此类推;然后在头部不移动的情况下,移动眼睛的方向。
在拍摄间隙,美发师会过来帮我把衬衫弄平整,去掉棉絮,并告诉我不要把胳膊动得太厉害。
看起来这个团队在指导人工智能克隆拍摄方面很有经验,尽管他们是为这个项目雇佣的自由职业者。
最后,我需要从提词器上读出一个剧本,在那里摄像机可以捕捉到我说话时的神态。
导演非常强调积极情绪(positivity),告诉我每说一句台词前后都要露齿微笑;他还告诉我说话的时候把手稍微放在身前,以便用一种更生动的方式强调我的演讲。
导演一直在提醒我,「你想要一个真正积极的化身」。
拍摄结束时,我已经筋疲力尽,但还是很期待地想看看我的数字孪生会是什么样子,声音又是什么样。
克隆成品
我回到家,等了几个星期。然后收到一封电子邮件,说我的克隆人已经准备好了。
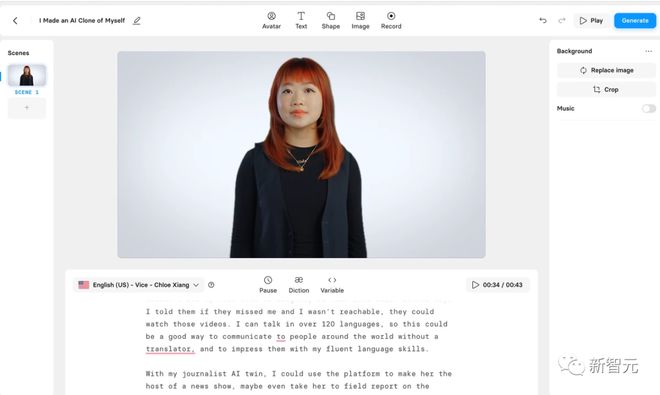
我登录 Synthesia 平台后,看到了一个更加亮丽的自己,我立即开始测试她,要求她先说一段简短的自我介绍,再说一段饶舌歌词,想要测试一下她能说能做的极限。
我意识到她可以做到很多令人印象深刻的事情,包括用英国口音和用中文说话。
如果我不熟悉自己的声音,这个人工智能克隆人可能会非常有说服力,因为她的嘴巴以一种欺骗性的自然方式动着,一些没有见过我但看过我的视频的同事甚至会问我,他们看的视频是不是真的是我。
系统中还包括一个过滤器,可以禁止用户使用 AI 化身说一些 NSFW (not safe for work)的内容,所以我不能让她随心所欲地说一些我想说的话,比如无法生成一个化身说脏话的视频。
在视频预览下面是一个文本框,用户可以输入一段脚本,不过我觉得更好的方式是上传一个音频文件,人工智只需要对嘴型就行了。
当我输入一个脚本时,可以预览视频的音频,并通过输入正确的发音覆盖发音,以及在单词之间添加更长的沉默,一旦我完成了所有的定制,我可以点击生成和按钮也会告诉你多长时间的视频将被制作,这是更长的文字你有。
几周后,他们同步了我的声音,克隆体已经完全准备好了。
大多数情况下,声音听起来有点像 Siri 化的感觉,这个声音是相当机械且单调的,不提供任何接口来手动改变选定的声音的语调,比如尖叫或耳语等。
看着我的人工智能克隆体,我发现她作为一个整体来说还原度还是很高的,尤其是如果你不知道我真正的声音听起来像什么。
而且她真的很吓人,我给我的朋友们看了她的视频,他们立刻就能发现是人工智能生成的,而不是我本人,也许是因为我不会轻轻摇头或者像 Siri 那样说话。
不管怎样,我告诉他们,如果他们想我,又联系不上我,他们可以看那些视频。
克隆体可以用超过 120 种语言交谈,所以这可能是一个很好的方式在没有翻译的情况下沟通世界各地的人,并给他们留下具有流利的语言技能的印象。
有了人工智能克隆体,我可以利用 Synthesia 平台让她成为一档新闻节目的主持人,甚至可以带她去元宇宙的现场报道。
参考资料:
https://www.vice.com/en/article/pkg7an/i-made-an-ai-clone-of-myself






