
新智元报道
编辑:编辑部
近日,谷歌正式发布了支持 100 多个语种的 20 亿参数通用语音模型——USM,正式对标 OpenAI 的开源 Whisper。
上周,OpenAI 发布的 ChatGPT API 和 Whisper API,刚刚引动了一场开发者的狂欢。
3 月 6 日,谷歌就推出了一款对标的模型——USM。不仅可以支持 100 多种语言,而且参数量也达到了 20 个亿。
当然了,模型依然没有对外开放,「这很谷歌」!
简单来说,USM 模型在涵盖 1200 万小时语音、280 亿个句子和 300 种不同语言的无标注数据集中进行了预训练,并在较小的标注训练集中进行了微调。
谷歌的研究人员表示,虽然用于微调的标注训练集仅有 Whisper 的1/7,但 USM 却有着与其相当甚至更好的性能,并且还能够有效地适应新的语言和数据。

论文地址:https://arxiv.org/abs/2303.01037
结果显示,USM 不仅在多语种自动语音识别和语音-文本翻译任务评测中实现了 SOTA,而且还可以实际用在 YouTube 的字幕生成上。
目前,支持自动检测和翻译的语种包括,主流的英语、汉语,以及阿萨姆语这类的小语种。
最重要的是,还能用于谷歌在去年 IO 大会展示的未来 AR 眼镜的实时翻译。

Jeff Dean 亲自官宣:让 AI 支持 1000 种语言
当微软和谷歌就谁家拥有更好的 AI 聊天机器人争论不休时,要知道,大型语言模型的用途可不仅于此。
去年 11 月,谷歌最先宣布了新项目「开发一种支持全球 1000 种最常用语言的人工智能语言模型」。

同年,Meta 也发布了一个名为「No Language Left Behind」模型,并称可以翻译 200 多种语言,旨在打造「通用翻译器」。
而最新模型的发布,谷歌将其描述为通向目标的「关键一步」。
在打造语言模型上,可谓群雄逐鹿。
据传言,谷歌计划在今年的年度 I/O 大会上展示 20 多款由人工智能驱动的产品。
当前,自动语音识别面临许多挑战:
-
传统的监督学习方法缺乏可扩展性
在传统的方法中,音频数据需要费时又费钱的手动标记,或者从有预先存在的转录的来源中收集,而对于缺乏广泛代表性的语言来说,这很难找到。
-
扩大语言覆盖面和质量的同时,模型必须以高效的计算方式进行改进
这就要求算法能够使用来自不同来源的大量数据,在不需要完全重新训练的情况下实现模型的更新,并且能够推广到新的语言和使用案例。

微调自监督学习
据论文介绍,USM 的训练采用了三种数据库:未配对的音频数据集、未配对的文本数据集、配对的 ASR 语料库。
-
未配对的音频数据集
包括 YT-NTL-U(超 1200 万小时 YouTube 无标签音频数据)和 Pub-U(超 429,000 小时的 51 种语言的演讲内容)
-
未配对的文本数据集
Web-NTL(超 1140 种不同语言的 280 亿个句子)
-
配对的 ASR 语料库
YT-SUP + 和 Pub-S 语料库(超 10,000 小时的音频内容和匹配文本)

USM 使用标准的编码器-解码器结构,其中解码器可以是 CTC、RNN-T 或 LAS。
对于编码器,USM 使用了 Conformor,或卷积增强 Transformer。
训练过程共分为三个阶段。
在初始阶段,使用 BEST-RQ(基于 BERT 的随机投影量化器的语音预训练)进行无监督的预训练。目标是为了优化 RQ。
在下一阶段,进一步训练语音表征学习模型。
使用 MOST(多目标监督预训练)来整合来自其他文本数据的信息。
该模型引入了一个额外的编码器模块,以文本作为输入,并引入了额外的层来组合语音编码器和文本编码器的输出,并在未标记的语音、标记的语音和文本数据上联合训练模型。
最后一步便是,对 ASR(自动语音识别)和 AST(自动语音翻译)任务进行微调,经过预训练的 USM 模型只需少量监督数据就可以取得很好的性能。
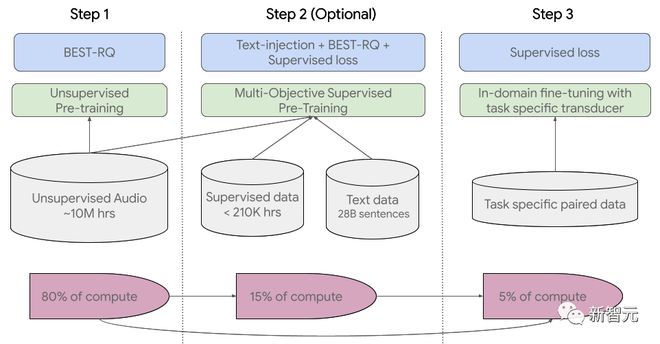
USM 整体训练流程
USM 的性能如何,谷歌对其在 YouTube 字幕、下游 ASR 任务的推广、以及自动语音翻译上进行了测试。
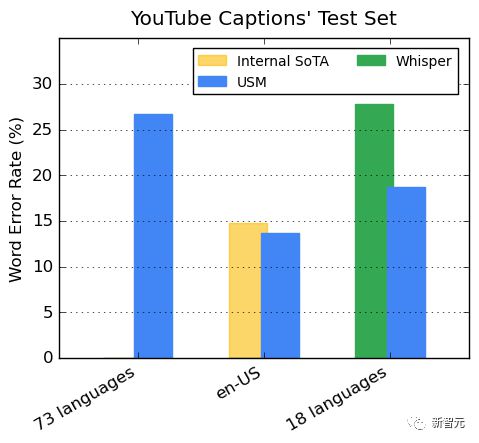
YouTube 多语言字幕上的表现
受监督的 YouTube 数据包括 73 种语言,每种语言的数据时长平均不到 3000 个小时。尽管监督数据有限,但模型在 73 种语言中实现了平均不到 30% 的单词错误率(WER),这比美国内部最先进的模型相比还要低。
此外,谷歌与超 40 万小时标注数据训练出的 Whisper 模型 (big-v2) 进行了比较。
在 Whisper 能解码的 18 种语言中,其解码错误率低于 40%,而 USM 平均错误率仅为 32.7%。
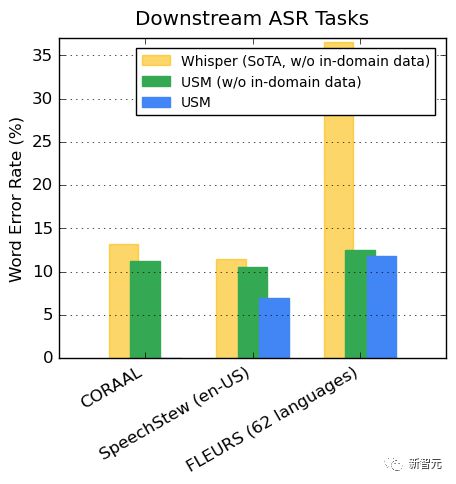
对下游 ASR 任务的推广
在公开的数据集上,与 Whisper 相比,USM 在 CORAAL(非裔美国人的方言英语)、SpeechStew(英文-美国)和 FLEURS(102 种语言)上显示出更低的 WER,不论是否有域内训练数据。
两种模型在 FLEURS 上的差异尤为明显。
在 AST 任务上的表现
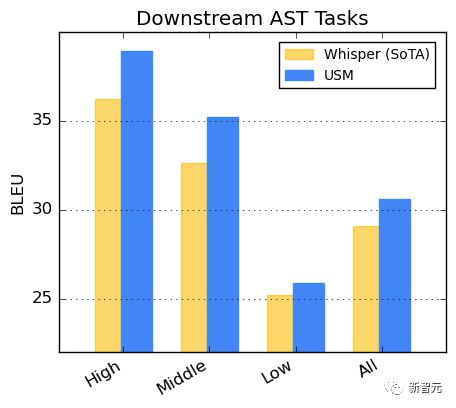
在 CoVoST 数据集上对 USM 进行微调。
将数据集中的语言按资源可用性分为高、中、低三类,在每一类上计算 BLEU 分数(越高越好),USM 在每一类中的表现的优于 Whisper。
研究发现,BEST-RQ 预训练是将语音表征学习扩展到大数据集的一种有效方法。
当与 MOST 中的文本注入相结合时,它提高了下游语音任务的质量,在 FLEURS 和 CoVoST 2 基准上实现了最好的性能。
通过训练轻量级剩余适配器模块,MOST 表示能够快速适应新的域。而这些剩余适配器模块只增加2% 的参数。
谷歌称,目前,USM 支持 100 多种语言,到未来将扩展到 1000 多种语言。有了这项技术,或许对于每个人来讲走到世界各地稳妥了。
甚至,未来实时翻译谷歌 AR 眼镜产品将会吸引众多粉丝。
不过,现在这项技术的应用还是有很长的一段路要走。
毕竟在面向世界的 IO 大会演讲中,谷歌还把阿拉伯文写反了,引来众多网友围观。

参考资料:
https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html?m=1
https://www.theverge.com/2023/3/6/23627788/google-1000-language-ai-universal-speech-model






