
新智元报道
编辑:LRS
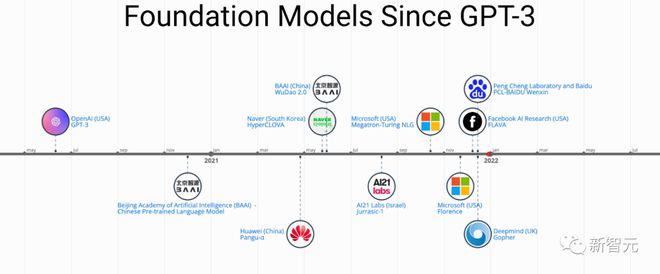
2023 年了,还有人从头开始训模型吗?追踪一下从 Bert 以来的那些预训练模型。
ChatGPT 在 few-shot 和 zero-shot 场景下展现出的惊人性能,让研究人员们更坚定「预训练」是一条正确的路线。
预训练基础模型(Pretrained Foundation Models, PFM)被认为是不同数据模式下各种下游任务的基础,即基于大规模数据,对 BERT、 GPT-3、 MAE、 DALLE-E 和 ChatGPT 等预训练基础模型进行训练,为下游应用提供了合理的参数初始化。
PFM 背后的预训练思想在大型模型的应用中起着重要作用,与以往采用卷积和递归模块进行特征提取的方法不同,生成预训练(GPT)方法采用 Transformer 作为特征提取器,在大型数据集上进行自回归训练。
随着 PFM 在各个领域获得巨大成功,近几年发表的论文中提出了大量的方法、数据集和评价指标,行业内需要一篇从 BERT 开始一直追踪到 ChatGPT 发展过程的全面综述。
最近,来自北航、密歇根州立大学、理海大学、南洋理工、杜克等国内外多所知名院校、企业的研究人员联合写了一篇关于预训练基础模型的综述,提供了在文本、图像和图(graph)等领域的最近的研究进展,以及目前和未来的挑战、机遇。

论文链接:https://arxiv.org/pdf/2302.09419.pdf
研究人员首先回顾了自然语言处理、计算机视觉和图形学习的基本组成部分和现有的预训练;然后讨论了其他先进的 PFM 的其他数据模式和统一的 PFM 考虑数据质量和数量;以及 PFM 基本原理的相关研究,包括模型效率和压缩、安全性和隐私性;最后,文中列出了几个关键的结论,包括未来的研究方向、挑战和开放的问题。
从 BERT 到 ChatGPT
预训练基础模型(PFMs)是大数据时代构建人工智能系统的重要组成部分,其在自然语言处理(NLP)、计算机视觉(CV)和图学习(GL)三大人工智能领域得到广泛的研究和应用。
PFMs 是通用模型,在各个领域内或跨领域任务中都很有效,在各种学习任务中学习特征表示方面表现出巨大的潜力,如文本分类、文本生成、图像分类、物体检测和图分类等。
PFMs 在用大规模语料库训练多个任务并对类似的小规模任务进行微调方面表现出卓越的性能,使得启动快速数据处理成为可能。
PFMs 和预训练
PFMs 是基于预训练技术的,其目的是利用大量的数据和任务来训练一个通用模型,在不同的下游应用中可以很容易地进行微调。
预训练的想法起源于 CV 任务中的迁移学习,在认识到预训练在 CV 领域的有效性后,人们开始使用预训练技术来提高其他领域的模型性能。当把预训练技术应用于 NLP 领域时,经过良好训练的语言模型(LMs)可以捕捉到对下游任务有益的丰富知识,如长期依赖关系、层次关系等。
此外,预训练在 NLP 领域的显著优势是,训练数据可以来自任何未标记的文本语料库,也就是说,在预训练过程中存在着无限量的训练数据。
早期的预训练是一种静态方法,如 NNLM 和 Word2vec,很难适应不同的语义环境;后来有研究人员提出了动态预训练技术,如 BERT、XLNet 等。

PFMs 在 NLP、CV 和 GL 领域的历史和演变
基于预训练技术的 PFMs 使用大型语料库来学习通用语义表征,随着这些开创性工作的引入,各种 PFMs 已经出现,并被应用于下游的任务和应用。
一个显著的 PFM 应用案例就是最近爆火的 ChatGPT。
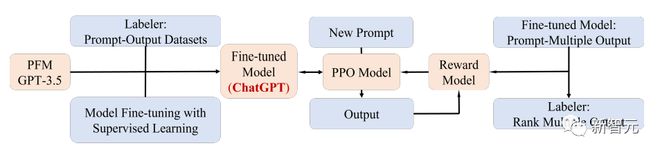
ChatGPT 是从生成式预训练 Transformer,即 GPT-3.5 在文本和代码的混合语料训练后,再微调得到的;ChatGPT 使用了来自人类反馈的强化学习(RLHF)技术,也是目前将大型 LM 与人类的意图相匹配的一种最有前景的方法。
ChatGPT 的优越性能可能会导致每一类 PFMs 的训练范式转变的临界点,即应用指令对齐(instruction aligning)技术,包括强化学习(RL)、prompt tuning 和思维链(chain-of-thought),并最终走向通用人工智能。
这篇文章中,研究人员主要回顾了文本、图像和图(graph)相关的 PFM,也是一个相对成熟的研究分类方法。
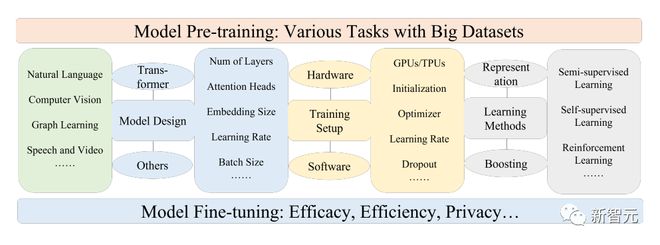
对于文本来说,语言模型通过预测下一个单词或字符即可实现多种任务,例如,PFMs 可用于机器翻译、问题回答系统、主题建模、情感分析等。
对于图像来说,类似于文本中的 PFMs,使用大规模的数据集来训练一个适合多个 CV 任务的大模型。
对于图来说,相似的预训练思路也被用于获得 PFMs,可用于诸多下游任务。
除了针对特定数据域的 PFMs,文中还回顾并阐述了其他一些先进的 PFMs,如针对语音、视频和跨域数据的 PFMs,以及多模态 PFMs。
此外,一个能够处理多模态的 PFMs 的大融合趋势正在出现,也就是所谓的统一(unified)PFMs;研究人员首先定义了统一 PFMs 的概念,然后回顾了近期研究中最先进的统一 PFMs,包括 OFA、UNIFIED-IO、FLAVA、BEiT-3 等。
根据这三个领域现有的 PFMs 的特点,研究人员得出结论,PFMs 有以下两大优势:
1. 只需要进行极少的微调就可以提高模型在下游任务上的表现;
2. PFMs 已经在质量方面通过了考验。
与其从头开始建立一个模型来解决类似的问题,更好的选择是将 PFMs 应用于与任务相关的数据集。
PFMs 的巨大前景激发了大量的相关工作来关注模型的效率、安全性和压缩等问题。
这篇综述的特点在于:
-
研究人员跟踪了最新的研究成果,对 PFM 在 NLP、CV 和 GL 中的发展进行了扎实的总结,讨论并提供了关于这三个主要应用领域中通用的 PFM 设计和预训练方法的思考结果。
-
总结了 PFMs 在其他多媒体领域的发展,如语音和视频,还进一步讨论了关于 PFMs 的更深层次的话题,包括统一的 PFMs、模型效率和压缩,以及安全和隐私。
-
通过对各种模态下不同任务的 PFMs 的回顾,讨论了在大数据时代对超大型模型未来研究的主要挑战和机遇,将引导开发新一代基于 PFMs 的协作和交互智能。
参考资料:






