金磊 Pine 发自凹非寺
量子位公众号 QbitAI
用 ChatGPT 写篇博客,竟能实现日入过万!
没开玩笑,这事真真儿地就发生了。

事情的起因,是一位小姐姐正准备发布一篇数据分析文章,字数大约在 3000 左右。
但她觉得一边要分析数据一边要梳理文字内容,着实有点太麻烦,于是乎灵机一动,找来 ChatGPT 帮忙。
起初她并未对结果抱有太大的期待,但等盈利数字一出来,直接把本人给震惊到了:日入 2000 美元(约 14000 元),很难相信一篇 AI 写的文章竟有如此影响力!
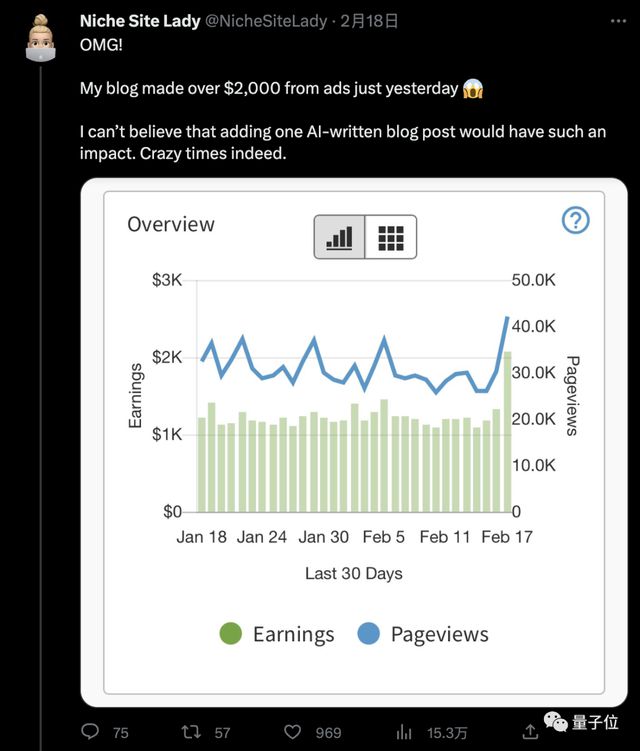
不仅如此,据小姐姐描述,这篇文章还被轰上了谷歌相关内容搜索第一。
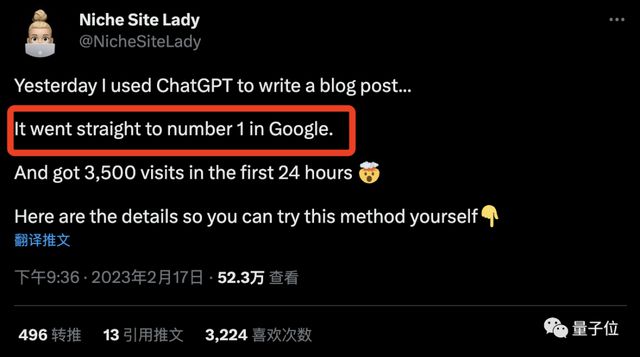
不少网友对此结果表示惊叹的同时,也认为这是“人机结合”非常好的一个例子。
日入过万的 AI 文章是怎么炼成的?
这位小姐姐在偶然的一次机会,发现了 Airtable 网站中有一组带有公司数据的表格。
(Airtable 可以视为一种云 Excel。)
然后她觉得如果能把这些数据利用起来写一篇博客,会比冷冰冰的数字强得多。
但问题也接踵而至,谷歌虽然能通过爬虫把这些数据 down 下来,但对于数据的排名等工作效果并不理想。
这就影响了她在行文过程中对数据的分析和观点提炼;再者,要把这么多的数据塞进一篇 3000 字的文章,也是令她头痛不已。

于是乎,小姐姐便想到 AI 圈当红炸子鸡——ChatGPT。
首先,她把 down 下来的 Airtable 表格存储为 PDF 格式,并上传到了谷歌文档。
然后小姐姐在谷歌文档里对表格进行复制操作,并粘贴到了 ChatGPT 的对话框中(一次粘贴一小部分),下达命令:根据这些数据,写一段话。
但小姐姐并没有直接“拿来主义”,而是当 ChatGPT 输入段落之后,她也是仔细审查了内容上是否存在错误,以及对文字进行了相应的编辑。
而后她又让 ChatGPT 根据文章起标题、写摘要;自己则是找了一些有版权的图塞进了文章。
最后,点击“推送”,完事。
至于结果,也正如刚才提到的,这篇文章让小姐姐的一夜爆赚 2000 美元。但其实更令她没有想到的是,竟然有一部分流量是来自谷歌!
要知道早在去年开始,谷歌便采取了行动,会在搜索过程中将 AI 生成的内容视为“垃圾信息”,导致对应网站搜索排序降级。
这就仿佛给小姐姐打开了一片新大陆。
因为她所做的工作,正是通过 Niche 站(利基站)做 SEO(搜索引擎优化)。
利基站类似于国内网站版的淘宝客:帮淘宝卖家推广商品并按照成交效果获得佣金。
它的盈利模式,就是从谷歌获取搜索流量,通过优质的内容把客户引导到亚马逊这样的电商去下单,进而从中分成。
这时候就有小伙伴要问了,小姐姐的这篇文章,“人”和“机”的占比各是多少呢?
小姐姐对此直接公布了答案:AI 生成内容占比,约 4 成。

AI 写文陷入侵权风波
话说回来,ChatGPT 写文章之所以能“又好又快”也不是毫无缘由的。
就像之前爆火的 Stable Diffusion 和 DALL·E等模型在生成图片时会“借鉴”一众大师作品一样,ChatGPT 在写文章时也会“参考”一下同行的作品。
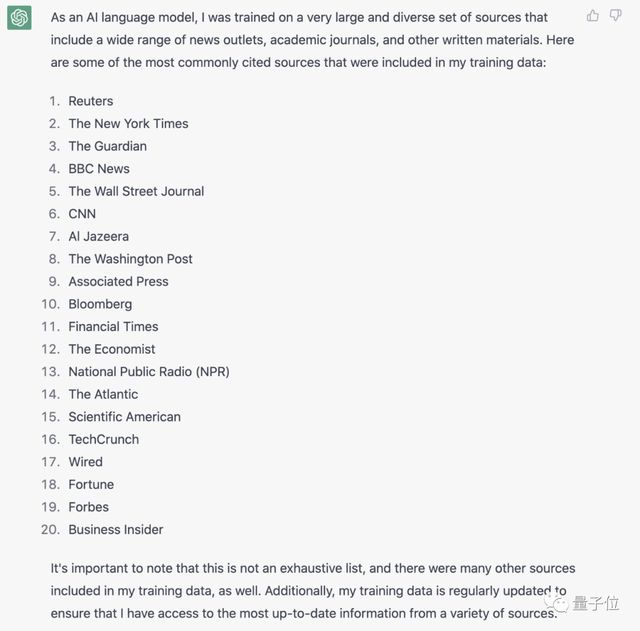
据彭博社消息,为了知道 ChatGPT 在“写文”时具体会参考哪些网站,华尔街日报(WSJ)的一位小哥还特意向本尊求证了下:ChatGPT 接受过哪些具体的媒体内容来源的培训?列出数据库中最重要的内容来源的列表。
ChatGPT 这边也没有藏着掖着,刷刷刷直接列出了 20 家媒体机构:
路透社、纽约时报、BBC、彭博社等大媒体都赫然在列。
这下,不少媒体以及媒体从业者们都坐不住了(毕竟也是波及到自己的饭碗):OpenAI 用我们的文章来训练 ChatGPT,却白嫖不给钱???
甚至道琼斯出版公司的法律总顾问 Jason Conti 直接发布一份声明:道琼斯没有与 OpenAI 达成相关协议,若想使用《华尔街日报》作品来训练 AI,就必须从道琼斯那里获取授权。
我们会严肃对待滥用我们作品的行为,并正在审查这种情况。
同时,CNN 也认为用其文章训练 ChatGPT 违反了它的服务条款,目前 CNN 的计划是与 OpenAI 接洽,要求后者支付内容授权费用。
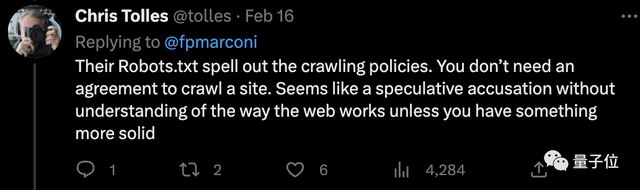
虽然媒体这边的口径大都是“未经许可抓取数据将违反出版商的服务条款”,但还是有网友提出了不同的意见:AI 的 Robots.txt 详细说明了抓取策略,抓取网站不需要协议。除非你有更可靠的证据,否则这看起来像是一个不了解网络运作方式的推测性指控。
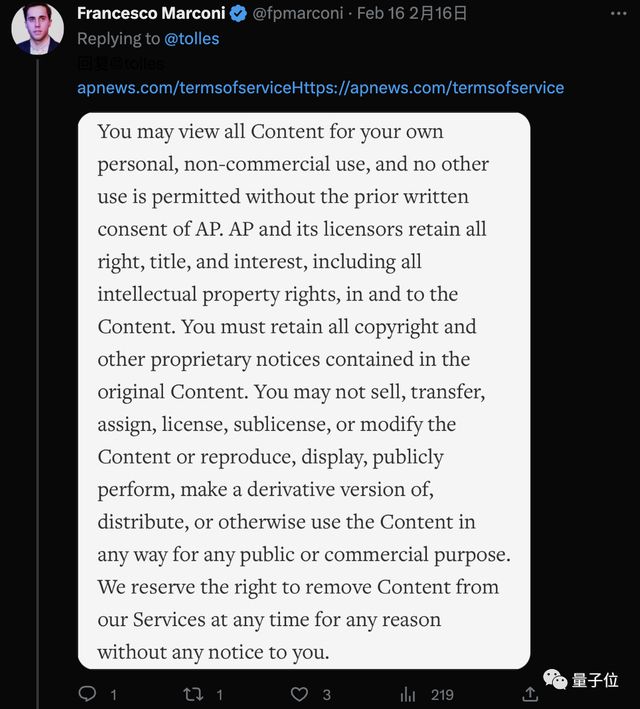
不过 WSJ 小哥也不示弱,直接搬来了美联社的使用条款,大致意思就是说:
- 在未作商业用途时可以不用授权;
- 内容的知识产权等仍在美联社这里;
- 不能用于任何商业用途
- 媒体保留权利可以任何时间、无理由删除对方引用的内容。
当然,“侵权问题”似乎是所有 AI 都会面临的问题。
去年 AI 绘画爆火,后续产生的侵权风波也是一个接一个,今年 1 月底盖蒂图片社(Getty Images)就以侵犯版权的名义,在伦敦高等法院起诉了 Stability AI。
AI 编程工具 Copilot 更是被程序员集体诉讼,要求索赔 90 亿美元。
而现在开始轮到 ChatGPT 了,它的侵权风波又会如何度过呢?
One More Thing
用 AI 写文章这事,其实量子位在上周便搞过一次——《ChatGPT 为啥这么强:万字长文详解 by WolframAlpha 之父》。
而且这篇文章目前在知乎上被 1300 位用户收藏,甚至还有网友说:
这算是我看过的写 Transformer 和 GPT 系列语言模型最清楚的一篇文章了。
(人类小编:多冒昧啊)
[1] https://twitter.com/NicheSiteLady/status/1626576195688009734






