
文|苏建勋 邓咏仪 周鑫雨 于丽丽
编辑|杨轩李洋
1、压力、狂热和久违的“ALL In”
像一颗兴奋的火种,ChatGPT 正在中国科技公司急速蔓延。
百度 CEO 李彦宏直接把自己 2023 年的 OKR 定为:“引领搜索体验的代际变革”。一位百度内部人士对 36 氪表示,李彦宏认为这次机会绝不能错过,不同于元宇宙火时他持怀疑态度,从没在公开场合讨论,但 AIGC(人工智能生成内容)、ChatGPT 却多次说过。
对这家中国搜索公司来说,这项火遍全球的突破性人工智能技术,为它带来了全新的想象力。2 月 7 日,百度宣布将发布类似 ChatGPT 的项目“文心一言”后,其港股股价应声而涨 12%。市场是如此期待中国也能尽快推出类 ChatGPT 产品。
多位百度人士告诉 36 氪,高层下了死命令,要在一个月时间内看到产品,“3 月完成内测”。
一股自上而下的压力全面袭来。“所有 OKR 推迟,就搞文心一言。”多位百度员工向 36 氪描述了公司内部当前的紧绷状态:“技术琢磨怎么研发、产品经理思考怎么接入、销售在想怎么卖。”用来训练数据模型的稀缺资源——英伟达 A100 芯片,“全部调用给文心大模型,其他组都借不到”。
紧张的倒计时下,北京西二旗的科技园里,百度的算法工程师们迎来一个个封闭开发的不眠夜。由百度 CTO 王海峰担任总指挥,协调两大事业群、百度核心 AI 人才组队攻坚——百度在用一种最高级别的战备姿态来迎接这场“搜索代际变革”。
36 氪获悉,字节跳动也已集结了几个核心部门,组成团队布局类 ChatGPT 产品。
“头部的平台公司里面,字节肯定是反应最快和投入最坚决的。”一位投资人评价,比如去年字节 AI 把人脸卡通化的应用已经火过一波。业内也对字节的表现充满期待。
“像 ChatGPT 这样的人工智能,与个人电脑 、互联网同等重要。”连比尔盖茨都如此公开表示。微软在 ChatGPT 推出后,对孵化该产品的公司 OpenAI 又宣布追加 100 亿美元投资,让这家仅有 500 人的创业公司估值高涨至 290 亿美元。
中国股市情绪汹涌。2 月上旬开始,“ChatGPT 概念股”如雨后春笋,包括汉王科技、海天瑞声、科大国创、科大讯飞在内的多支股票接连大涨,即便他们的业务只和 ChatGPT 底层的 AI 技术有部分关联,也并没有成型的产品。
科技属性、流量纪录、资本疯狂……ChatGPT 成为后疫情时代的第一个绝佳故事脚本,没人不爱它。
大公司在狂欢,创投圈也在骚动。
2022 年底,一家美元基金的年轻投资人 Kevin 被派到硅谷,彼时,硅谷已经因 ChatGPT 陷入疯狂,他所在的基金敏锐地觉察到这个变化,因此那阵基金各个赛道的投资人“都在关注 AI 的变量”。甚至有人相信,这“可以让 TMT 投资人续命 15 年”。
过去几年,互联网增长见顶的讨论不绝如缕,人们不得不向投机味道浓重的 Web3、元宇宙投注热情。而当 ChatGPT 横空出世,人们共同体验了它似模似样地捉刀作业、起草邮件、书写代码,甚至富有逻辑地胡说八道后,共识前所未有地快速成型。
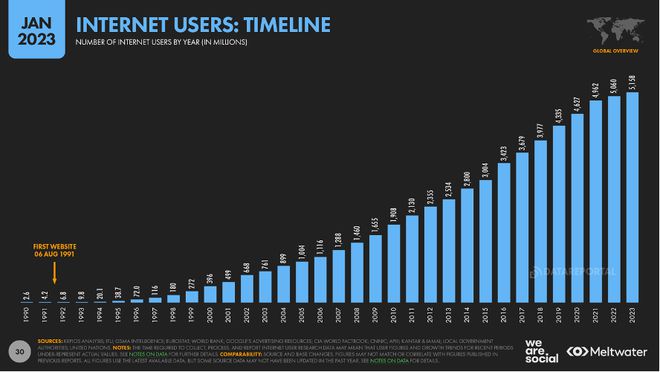
全球互联网人口在过去一年增长了近 1 亿,增长率仅约2% 来源:Datareportal
短短两三个月,热潮就从硅谷传到中国,从去年年底的“新时代来了”,变为今年年初“人人都知道新时代来了”。
随着前美团二号位王慧文发布自带 5000 万美元入局 AI 大模型、广纳技术英雄的招募贴,热烈的情绪走向高潮。
AI 公司出门问问创始人李志飞最近也与王慧文面议 AI 大模型到深夜。“ChatGPT 把去年躺平的中国创投圈都炸醒了,”李志飞几天前在朋友圈写道,此时“堪比 2010 年左右开启的移动互联网,听到最多的词是 All in”。
盘点“天选之人”时,36 氪原本认为,卖掉搜狗的王小川错过这次机会堪称憾事——清华计算机系毕业的王小川创立搜狗 18 年,业务涵盖搜索、输入法、翻译,均与 AI 语言模型相关——但意外听到他也在计划创业,回归做 AI 大模型的消息。
36 氪向王小川求证,他承认,自己在“快速筹备中”。
2、上头派,冷静派
此时一个最实际的问题是:中国能否沿着相同的路径,复刻一个 ChatGPT?
在硅谷看过一轮之后,投资人 Kevin 的情绪却从热烈走向冷静。他发现,中国的复刻之路远比想象的要艰难。
钱是第一道门坎。OpenAI 出世之时由几位硅谷大佬承诺出资 10 亿美元。在 ChatGPT 发布前,微软就已经在 2021 年悄悄向 OpenAI 投资了 20 亿美元。与之对应的,是 OpenAI 的巨额支出,业界推测其核心语言模型 GPT-3 的单次训练成本高达 460 万美元。换算下来,王慧文为此次创业筹备的 5000 万美金,只供 GPT-3 进行十次训练。
在提及入场 AI 大模型“报名费 5000 万美金起”仅一天后,李志飞又发朋友圈说,在饭局上“惊闻门票可能已经涨价到一亿美金了”。“现在的感觉真是 AI 圈一天人间三年,一天不学习和思考就跟不上吃瓜群众的认知了”。
钱还是最容易迈过的一道门槛——在 OpenAI 已经探明道路、还发了论文的情况下,Meta 还开源了一个类似的 AI 大模型,后来者已经能节省很多试错的训练费用。即使考虑到 AI 大模型后续还需训练,微软又追加了 100 亿美金投入——中国互联网历史上,在诸如打车等风口,募资过百亿美金的案例并不在少数。
第二道门槛要难迈得多,至少对小公司来说如此。由于美国对中国禁售芯片,而运行 AI 大模型需要大量 GPU 芯片——芯片上受的钳制,又影响了做 AI 大模型。
AI 公司“彩云科技”的创始人袁行远告诉 36 氪,要想跑通一次 100 亿以上参数量的模型,至少要做到“千卡/月”这个级别,即:用 1000 张 GPU 卡,然后训练一个月。
即使不用最先进的英伟达 A100,按照一张 GPU 五万元的均价计算,1000 张 GPU 意味着单月 5000 万的算力成本,这还没算上算法工程师的工资。
“但是中国历史上买的 A100 卡肯定是够的,后面哪怕禁运了,但公有云厂商以前买的那些卡,复刻 ChatGPT 是非常绰绰有余的。”Kevin 对 36 氪分析。
阿里、华为、腾讯、百度、字节……这些大厂都有公有云业务。多位业内人士对 36 氪分析,短时间内,芯片(意味着算力资源)至少对大厂还不是太大问题。
第三道门槛,人才的流向,有点灵魂拷问。考虑到 OpenAI 不过 500 人规模,而经历过上一轮 AI 热潮的中国公司动辄数千人,凑个人头应该不在话下。
但 Kevin 认为,现成的优秀人才,都在四大美国科技公司的 AI Lab 里。不同于上一波硅谷人才回国潮之时,如今世界局势、国内财务自由前景都截然不同,如何让人才“系统性回国”成为挑战。而上一波 AI 人才是否能顺滑转换做 AI 大模型,还要打个问号。
至于商业变现,似乎前景无限,但又不甚明朗。
Kevin 预测,AI 大模型在中国的变现之路,一定不如美国“清爽”。他以云服务做类比,在美国,可以直接按租用服务器收费,其他都不用管,正如 ChatGPT 可以直接按调用次数收费。但在中国,面对大企业和政府,技术公司得做全套服务、甚至是定制开发。
这项技术与大用户产品结合,更可能爆发无穷威力。例如 ChatGPT 与搜索结合——这带来了颠覆 Google 搜索的想象空间,让投资了 OpenAI 并获得使用授权、拥有 Bing 搜索业务的微软,市值在过去一个月里大涨 1631 亿美元——但在实际落地上还有障碍。
一位百度搜索业务的员工告诉 36 氪,公司对于 ChatGPT 业务与搜索的结合尚有担忧:“搜索广告的本质是给用户展现更多结果页面,可 ChatGPT 是更精准、更有逻辑地推送答案,两者结合后可能会影响搜索广告收入。”
上头派和冷静派——从目前的情绪上,李志飞把业界分为这两派。上头派“满腔鸡血不管不顾只求第一个进入,希望获取先发红利,让资金和人才向其靠拢”;而冷静派“谋定而后动,希望全面梳理人才架构、技术路线、国家态度、接下来互联网巨头的合纵连横、潜在商业模式等关键问题”。
哪一派能最后能胜出?
即使目前是上头派,最终也得面对冷静派考虑的这些问题。
3、类 ChatGPT=CheatPPT?
多位从业者都对 36 氪说,中国做出类似 ChatGPT 的产品“只是时间问题”。但对复刻一家 OpenAI 的公司,却大多表示悲观。
OpenAI 为什么没有出现在中国?这个问题有点过于触及灵魂了。
耗时长度,就可能超乎想象。
“小冰做 AI Being 的时候,我还是个小伙子,现在做了 10 年了。10 年来我们没有变过方向,磨了不一定有结果,不磨更没有结果。”小冰 CEO 李笛对 36 氪感叹。从微软亚洲互联网工程院拆分为独立公司的小冰,是目前国内不多的拥有完备人工智能框架的 AI 公司。几年前的小冰已经能写诗、作画、唠嗑,算跟 ChatGPT 非常类似。
“磨”,是指对模型背后 Instruction(行为逻辑模版)的打磨。当机器将表示无奈的“。。。”误以为所有标点符号都要重复三个时,粗暴的处理方式当然可以禁止机器重复标点,而要想让模型更聪明,需要人为地写入更多 Instruction,告诉机器什么情况下可以使用“。。。”,什么情况不能。
“你得有工匠精神,得死抠 Instruction 才有机会做得很好,OpenAI 的优势,就是它真的死抠。”李笛说,“国内外的科研能力差距并没有很大,但从业者需要耐得住寂寞去打磨。”
道理看似简单,但做起来却难。
一位大厂 AI 工程师看不惯内部急于出成果的做法,他们私下把类 ChatGPT 产品叫 “CheatPPT”,“就是交个 PPT,给领导画个饼”。因为“从技术到到应用又是一回事”,他对中文大模型在短时间内做产品,“还蛮悲观的。”
训练一个有一两千亿参数的大规模语言模型,需要大量的人工调教和用户数据反馈。云启资本合伙人陈昱认为,这也是很多大厂短期内拿不出和 ChatGPT 相媲美产品的原因,因为这些都不是“匆忙应战”所能解决的。
况且,时至今日,大模型仍未找到最优解,就算最接近图灵测试的 ChatGPT,在知识性和逻辑理解能力上依然有所欠缺。李笛将打磨过程视作“够天花板”:“人工智能的思维上限,要用无数次 Instruction 的微调去试探。”
而且,死抠也不见得立竿见影,OpenAI 的成功,在今天看来仍有偶然性。
OpenAI 成立时,业内主流人工智能路线是“监督式深度学习”,需要人工将语义、图片打上标注,机器才可以识别相似信息,典型的应用场景是客服回答与直播鉴黄。但 OpenAI 选择的“非监督强化学习”技术路线,是将巨大的语料库不经标注地直接投进模型,等待机器吐出一个未知的结果。
经费在燃烧,结果却无从预料,这种九死一生的创新模式,成了大多数公司无法承受之重。
一位明星 AI 创业公司工程师向 36 氪描述了急于追逐 ChatGPT 的难堪一幕:为了成为投资人眼中的 OpenAI,该公司的底层算法直接照抄 GPT-3 流传的复刻版;拿不到数据语料,就去中小学生的 QQ 群投放语音聊天包,结果收回来一堆带有颜文字的聊天纪录。
“模型越训练,效果越匪夷所思,这个模型最后使用的成本,肯定比招一个人工客服贵。”这位工程师对 36 氪说。
大模型所需的语料,是对耐心的重大考验。
“所有的文本数据都在互联网上,但难度在于怎么清洗出好数据。”昆仑万维 CEO 方汉对 36 氪表示,昆仑万维从 2020 年开始做自有 AI 多国语言大模型,仅仅是用自己的专有算法清洗数据,就整整花费了近两年,从百亿级数据里筛出了 10% 的好数据。
不少 AI 老兵多少都经历过坐冷板凳的岁月。清洗数据的“脏活累活”,聆心科技 CEO 黄民烈和清华的课题组做了数年。在中文语境下训练出一个 ChatGPT,要面临更复杂的语言体系。黄民烈介绍,中文的语法较英文更松散灵活,也没有空格对词语加以区分。
深入 AI 大模型的训练细节,“耐心”是一项反复出现的关键要素。如何更有耐心地重视基础科研,也许才是一个真问题。
但尴尬的是,过去三年,在降本增效的大背景下,身披光环的 AI 科学家们成了科技巨头中的尴尬存在。2019 年末,腾讯 AI Lab 主任张瞳离职,去了港科大;2020 年,字节跳动 AI Lab 负责人马维英离职,去了清华;2022 年,阿里 M6 大模型带头人杨红霞离职。一位曾在大厂 AI 实验室工作过的员工告诉 36 氪,在大厂里做基础科研的一个尴尬细节是,“连 OKR 都没法定”。
至于在上一波 AI 投资热潮中出现的“AI 四小龙”,基本都在做视觉识别、挣安防领域的钱,似乎已经离 AI 通用大模型有一段距离。在风险投资“5 年 +2 年”的投资周期要求下,创业公司需要在这个周期内走到商业变现一步,而做基础研究很难养活自己。
此刻,缺乏耐心的故事正在再度上演。
为了迎合投资人的口味,有创业公司正试图将自己强行包装成“中国式 OpenAI”。一位国内明星 AI 创业项目的工程师告诉 36 氪,ChatGPT 爆火后,公司 CEO 要求模型效果达到与 ChatGPT 近似水平,工程师们只能通过粗暴改写程序等方式,强迫机器按照他们的想法运作。
“比如 AI 会把每句话里的标点符号重复三次,后来发现是因为训练数据里,很多用户会用‘。。。’表示无语,机器就误以为这是人类的正常表达,我们就只能写一段逻辑,强制机器不要重复标点,但这样模型不会提高任何能力。”这位工程师对 36 氪无奈表示。
上述案例还属于正经 AI 公司临时作弊。一位双币基金投资人曾在两年内 3 次遇到过同一个团队:第一次是在元宇宙概念爆火,第二次是 Stable Diffusion 带火图片生成,第三次则是在最近,他们又开始做 NLP(自然语言处理)。
“发展路径不清晰,实现希望很渺茫,商业价值不明确,一旦突破改变世界”,很可能是受到 OpenAI 的刺激,王慧文发帖说,如果自己新组的 AI 公司有剩余股份,想成立一支“非盈利性”基金,投资这样的科技探索。
而具备头 3 个特征的创业项目,往往都是拿不到融资的。要求一般投资人投这样的项目,也违反常理。
4、中国式打法
我们既希望出现中国的 OpenAI,也要认识到,OpenAI 狂堆参数的“暴力美学”,对绝大多数 AI 公司来说是个美丽的陷阱。
在国内,李笛见到过不少公司跟着 OpenAI 训练千亿、两千亿参数的模型,大多落得模型、钱财两空的下场。
“初创公司搭大模型的成功率是非常低的。”李笛对 36 氪说,“烧钱是一方面,你还得有工程上的综合能力,搜索、自然语言处理、模型优化……小公司突破起来太难了。”
他给出的警示是:OpenAI 的模式并不适合所有公司。一方面,大模型对不少业务场景没有必要;另一方面,还是成本的问题,“如果一个 35 亿参数的大模型的运行成本和以前的检索模型差不多,它才能落地,否则赔死了。”
一名双币基金的投资人用两个疑问,拒绝了一个立了“1 年做出大模型”军令状的项目:
“你们做大模型的必要性在哪?”
“有什么明确的商业模式吗?”
“ChatGPT 的出圈,会让我们在心态上对走在无人区的公司更包容。”一名投资人告诉 36 氪,“但评判项目价值的逻辑没有变,商业模式依然至关重要。”
“要死抠,在提高模型质量和降低成本两个方向同时抠。”李笛总结如何“落地”。
对于小公司而言,抠成本需要一些巧劲。比如做 AI 翻译业务时没钱买高质量的标注数据,袁行远想到了求助拥有丰富双语语料的字幕组和翻译社。
买不起 GPU 怎么办?那就租。袁行远算了笔账,按照 2000 万人民币的利润来算,在研发上投入 1000 万,在机器上投入 500 万,是公司能力的上限。这也意味着,按照显卡每张3-5 万元的价格,fine-tune 过程需要的 100 张 GPU,公司有能力掏钱买。但从零训练所需的 1000 张卡,彩云科技租借了云服务,把成本压到了几百万。
刚创业时,袁行远手中只有一台服务器、一张 GPU 和北京 6 月的降雨数据。没有办法做到“千卡/月”,算法工程师就要特别小心,“就怕模型跑到一半挂了没保存,一切前功尽弃,浪费了算力资源”。
大模型的效果是惊艳的,但李笛认为,通过将其拆解为更小、更轻量的步骤训练,依然能达到殊途同归的效果。
创业公司在探索天花板的同时,还要活下去。
即便是最初定位为“非营利性组织”的 OpenAI,在高昂的入场费面前,也得与商业结合。2019 年,微软宣布注资 10 亿美元,并取得了将 OpenAI 部分技术商业化的权利——两年后,10 亿美元铺就的成果有目共睹,ChatGPT 横空出世。
去年开始,聆心智能开始面对普通人,做了类似于 ChatGPT 的 AI 对话。但黄民烈意识到,在现阶段的算法能力下,面向用户收费还为时尚早。其一款 AI 对话产品最后因为效果不达预期,推迟了一个月发布。
“做大模型研究是需要持续资金支持的长跑。”在黄民烈看来,资金储备是留住人才和维持研发的基础。2 月,聆心智能刚完成了 Pre-A 轮融资的交割。而在风口中,黄民烈决定再多和投资机构聊聊。
并不是所有 AI 公司都要当 OpenAI,要搞 ChatGPT。正如移动互联网并非只是苹果手机和安卓系统的机会,还会长出诸如字节、美团、滴滴等一些极有价值的公司,只是需要一些时间。
明势资本合伙人夏令认为,未来在相关竞争中形成争夺关键点的,是“谁能拿到更多场景里,user in the loop(用户在环)的、高质量反馈的私有数据,并以更高效率迭代”。
好消息是,热潮来临之时,创业公司的资金压力也许会得到纾解。
“我们的黎明终于要来了。”2022 年底第一时间试用 ChatGPT 后,这是虎博科技 CEO 陈烨的第一反应。
在那之前,虎博科技已经在 NLP(自然语言处理)领域苦熬数年,也推出过类 ChatGPT 的C端金融搜索业务,但当时技术还未成熟,商业化前景有限,不得不将其收缩。最难的时候,团队连水电煤支出都要一分分地计算。
而最近一段时间,陈烨拉着技术同事一起熬夜写代码,研究 ChatGPT 的模型、路径,并准备购入百万级别的机器用于研发。
AI 上一次引发热潮要回溯到 2016 年——谷歌旗下的 AI 机器人 AlphaGo 在“人机大战”中,第一次击败人类职业围棋冠军李世石。那之后,AI 行业经历了从极速繁荣到资本退潮,行业走入数年的低谷期。走进新时代,成了所有人的热望。
“技术圈的创业,就好像推导数学公式,你在还没有推导出来之前,谈别的是浪费时间,”一位 AI 技术专家对 36 氪表示,“如果 ChatGPT 真的起来了,中国这帮做业务型创新(如外卖、电商)的成功者们,如果没有跟上这波创新浪潮,都会被浪潮推走,成为上一代的人。”
也有人试图保持冷静。华创资本投资人张金告诉 36 氪,纵观中国三类 AI 创业公司——基础层(即大模型侧)、中间工具层、下游应用层——融资进度跟美国是几十倍甚至百倍的差距。比如应用侧一些公司,在美国都已经 10 亿美金了,商业化能力也很强,但国内公司普遍只有数亿人民币的估值。
无论如何,没有人想留在过去。在 36 氪多次约访后,一位经历过上一次 AI 周期的投资人最终选择拒绝:“最近忙着观察、讨论,确实没空回顾从前。”而在 36 氪所在的一个讨论群中,有人一进来就迅速将自己的昵称改成:“确保 AI 创新发生在本群”。
(36 氪作者窦轩、李安琪对本文亦有贡献)






