
随着以 ChatGPT 为代表的生成式 AI 兴起,其背后以大模型为基础的人工智能成为业界投入的方向。
所谓“大模型”,通常是在无标注的大数据集上,采用自监督学习的方法进行训练。之后在其他场景的应用中,开发者只需要对模型进行微调,或采用少量数据进行二次训练,就可以满足新应用场景的需要。
据腾讯研究院,当前的人工智能大多是针对特定的场景应用进行训练,生成的模型难以迁移到其他应用,属于“小模型”的范畴。整个过程不仅需要大量的手工调参,还需要给机器喂养海量的标注数据,这拉低了人工智能的研发效率,且成本较高。
相比之下,大模型的改进可以使所有的下游小模型受益,大幅提升人工智能的使用场景和研发效率。
同时,在大模型的框架下,ChatGPT 所使用的 GPT 模型,每一代参数量均高速扩张,预训练的数据量需求和成本亦快速提升。
国盛证券计算机分析师刘高畅、杨然在发表于 2 月 12 日的报告《Chatgpt 需要多少算力》中估算,GPT-3 训练一次的成本约为 140 万美元,对于一些更大的 LLM 模型,训练成本介于 200 万美元至 1200 万美元之间。这一成本于全球科技大企业而言并不便宜,但尚在可接受范围内。
初始投入近十亿美元,单日电费数万美元
国盛证券估算,今年 1 月平均每天约有 1300 万独立访客使用 ChatGPT,对应芯片需求为 3 万多片英伟达 A100GPU,初始投入成本约为 8 亿美元,每日电费在 5 万美元左右:
1) 计算假设:
英伟达 A100:根据 OneFlow 报道,目前,NVIDIAA100 是 AWS 最具成本效益的 GPU 选择。
英伟达 DGXA100 服务器:单机搭载 8 片 A100GPU,AI 算力性能约为 5PetaFLOP/s,单机最大功率约为 6.5kw,售价约为 19.9 万美元/台。
标准机柜:19 英寸、42U。单个 DGXA100 服务器尺寸约为 6U,则标准机柜可放下约 7 个 DGXA100 服务器。则,单个标准机柜的成本为 140 万美元、56 个 A100GPU、算力性能为 35PetaFLOP/s、最大功率 45.5kw。

2)芯片需求量:
每日咨询量:根据 Similarweb 数据,截至 2023 年 1 月底,chat.openai.com 网站(即 ChatGPT 官网)在 2023/1/27-2023/2/3 这一周吸引的每日访客数量高达 2500 万。假设以目前的稳定状态,每日每用户提问约 10 个问题,则每日约有 2.5 亿次咨询量。
A100 运行小时:假设每个问题平均 30 字,单个字在 A100GPU 上约消耗 350ms,则一天共需消耗 729,167 个 A100GPU 运行小时。
A100 需求量:对应每天需要 729,167/24=30,382 片英伟达 A100GPU 同时计算,才可满足当前 ChatGPT 的访问量。
3)运行成本:
初始算力投入:以前述英伟达 DGXA100 为基础,需要 30,382/8=3,798 台服务器,对应3,798/7=542 个机柜。则,为满足 ChatGPT 当前千万级用户的咨询量,初始算力投入成本约为 542*140=7.59 亿美元。
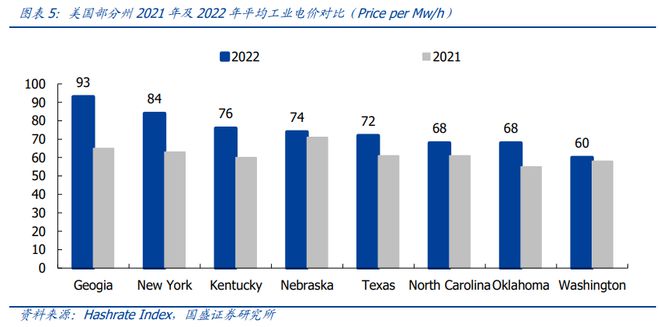
每月电费:用电量而言,542*45.5kw*24h=591,864kwh/日。参考 HashrateIndex 统计,我们假设美国平均工业电价约为 0.08 美元/kwh。则,每日电费约为2,369,640*0.08=4.7 万美元/日。
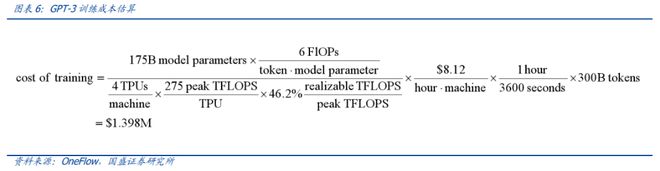
训练成本:公有云下,单次百万至千万美元
国盛证券基于参数数量和 token 数量估算,GPT-3 训练一次的成本约为 140 万美元;对于一些更大的 LLM 模型采用同样的计算公式,训练成本介于 200 万美元至 1200 万美元之间:
1)基于参数数量和 token 数量,根据 OneFlow 估算,GPT-3 训练一次的成本约为 139.8 万美元:每个 token 的训练成本通常约为 6N(而推理成本约为 2N),其中N是 LLM 的参数数量;假设在训练过程中,模型的 FLOPS 利用率为 46.2%,与在 TPUv4 芯片上进行训练的 PaLM 模型(拥有 5400 亿参数)一致。
2)对于一些更大的 LLM 模型(如拥有 2800 亿参数的 Gopher 和拥有 5400 亿参数的 PaLM),采用同样的计算公式,可得出,训练成本介于 200 万美元至 1200 万美元之间。
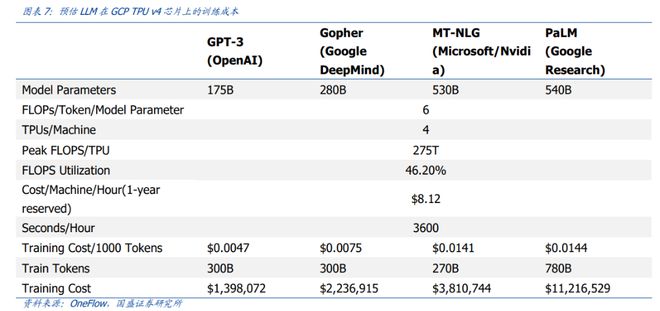
国盛证券认为,在公有云上,对于以谷歌等全球科技大企业而言,百万至千万美元级别的训练成本并不便宜,但尚在可接受范围内、并非昂贵。






