
文|甲子光年,作者赵健
ChatGPT 的热度正在一路狂飙。
“去年 12 月在机器学习圈曾持续热议过,但是没有现在每一个群都在交流和使用的状况。这是除了疫情,从未有过的现象。”有人如此感慨。
一位 AI 产品经理向「甲子光年」表示,或许若干年后回看 AI 行业的发展,会有两个标志:阿尔法狗代表 AI 在专业领域“干翻”人类的起点,ChatGPT 代表 AI 在通用智能领域“干翻”人类的起点......
《财富》杂志则是这样描述的:
在一代人的时间中总有一种产品的出现,它将从工程系昏暗的地下室、书呆子们臭气熏天的青少年卧室和爱好者们孤独的洞穴中弹射出来,变成了你的祖母 Edna 都知道如何使用的东西。早在 1990 年就有网络浏览器,但直到 1994 年 Netscape Navigator 的出现,大多数人才发现了互联网。2001 年 iPod 问世之前就已经有了 MP3 播放器,但它们并没有引发数字音乐革命。在 2007 年苹果推出 iPhone 之前,也有智能手机,但在 iPhone 之前,没有智能手机的应用程序。
2022 年 11 月 30 日,人工智能迎来了 Netscape Navigator 时刻。
对于人工智能或者聊天机器人,我们并不陌生。从苹果 Siri、微软小冰、智能音箱,这些人工智能产品已经融入到人们的生活中,但是基本都有一个特点——还比较笨,跟我们在《流浪地球2》中看到的 MOSS 相差十万八千里。
但这次的 ChatGPT 有点不一样。它不但可以实现多轮文本对话,也可以写代码、写营销文案、写诗歌、写商业计划书、写电影剧本。虽然并不完美、也会出错,但看起来无所不能。
连埃隆·马斯克都评价道:“ChatGPT 好得吓人,我们离危险的强人工智能不远了。”
而且,ChatGPT 也不仅仅是一个打发时间的聊天机器人,微软与谷歌此时此刻正在因为 ChatGPT 的出现筹备一场关乎未来的 AI 大战。而国内的科技公司,也在努力思考着如何搭上驶向未来的船票,无论是以蹭概念,还是真产品的方式。
这一切,ChatGPT 是如何做到的?本文,「甲子光年」将首先回答几个最基础的问题:
- ChatGPT 和过去的 AI 有什么不同?
- OpenAI 是如何战胜谷歌的?
- OpenAI 的成功花了多少钱?
- ChatGPT 爆火之后,谁是最后赢家?
1. ChatGPT,生成式 AI 的王炸
刚刚过去的 2022 年,从硅谷到国内的科技公司,上上下下都蔓延着一股“寒气”。但是,AI 行业却完全是另一番热闹的景象。
这一年,通过输入文本描述就能自动生成图片的 AI 绘画神器突然雨后春笋般冒了出来,其中最具代表性的几家为第二代 DALL·E(由 OpenAI 于 2022 年 4 月发布)、Imagen(谷歌 2022 年 5 月发布)、Midjourney(2022 年 7 月发布)、Stable Diffusion(2022 年 7 月发布)等,让人眼花缭乱。
2022 年 9 月,由 Midjourney 创作生成的画作《太空歌剧院》在科罗拉多州博览会数字艺术创作类比赛中获得一等奖并引发争议,AI 绘画进一步破圈,受到大众关注。
AI 绘画是 AI 发展的里程碑级应用,但没过多久人们便发现,AI 绘画只是“四个二”,真正的“王炸”在 11 月 30 日上线——ChatGPT。
去年 12 月,我们曾与 ChatGPT 做过一次对话。
从 AI 绘画到 ChatGPT,它们都属于 AI 的一个分支——生成式 AI(Generative AI),在国内也被称为 AIGC(AI Generated Content)。
2022 年 9 月,红杉资本发布了一篇重磅文章——《生成式 AI:一个创造性的新世界》(Generative AI: A Creative New World),首次提出生成式 AI 这一概念。
红杉资本将生成式 AI 分为文本、代码、图片、语言、视频、3D 等数个应用场景。红杉资本认为,生成式 AI 至少可以提高 10% 的效率或创造力,有潜力产生数万亿美元的经济价值。

图片来自红杉资本
凭借生成式 AI 的风口,一些 AI 绘画公司开始拿到巨额融资。2022 年 10 月,Stable Diffusion 模型背后的公司 Stability AI 宣布获得 1.01 亿美元种子轮,投后估值达 10 亿美元;另一家 AI 内容平台 Jasper 亦宣布获 1.25 亿美元新融资,估值达 17 亿美元。
据 Leonis Capital 统计,自 2020 年以来,VC 对生成人工智能的投资增长了 400% 以上,2022 年则达到惊人的 21 亿美元。
在文章中,红杉资本将 AI 分为“分析式 AI”与“生成式 AI”两大类,分析式 AI 主要用在垃圾邮件检测、预测发货时间或者抖音视频推荐中,也是过去几年最常见、发展最快的 AI 类型。国内的 AI 四小龙——商汤、旷视、云从、依图皆属于此类。
生成式 AI 则聚焦于知识工作与创造性工作,从社交媒体到游戏,从广告到建筑,从编码到平面设计,从产品设计到法律,从营销到销售。
在 2015 年之前,人工智能基本是小模型的天下。
过去的微软小冰、苹果 Siri、智能音箱,以及各个平台的客服机器人背后都是小模型,在其系统中包含若干 Agent(知行主体,可以理解为执行具体任务的程序),一个专门负责聊天对话、一个专门负责诗词生成、一个专门负责代码生成、一个专门负责营销文案等等。
如果需要增加新功能,只需要训练一个新的 Agent。如果用户的问题超出了既有 Agent 的范围,那么就会从人工智能变为人工智障。
但是 ChatGPT 不再是这种模式,而是采用了“大模型 +Prompting(提示词)”。大模型可以理解为背后只有一个 Agent 来解决用户所有的问题,因此更加接近 AGI(通用人工智能)。
ChatGPT 的出现不亚于在人工智能行业投下了一枚“核弹”。前微软 CEO 比尔·盖茨对 ChatGPT 评价为“不亚于互联网诞生”,现微软 CEO 萨提亚·纳德拉将其盛赞为“堪比工业革命”。如今,有越来越多的公司开始将 ChatGPT 融入其产品中,或者推出类 ChatGPT 的产品。
对此,ChatGPT 是如何做到的?
2. OpenAI 缠斗谷歌
ChatGPT 背后的公司为 OpenAI,成立于 2015 年,由特斯拉 CEO 埃隆·马斯克、PayPal 联合创始人彼得·蒂尔、Linkedin 创始人里德·霍夫曼、创业孵化器 Y Combinator 总裁阿尔特曼(Sam Altman)等人出资 10 亿美元创立。
OpenAI 的诞生旨在开发通用人工智能(AGI)并造福人类。
当时,谷歌才是人工智能领域的最强公司。2016 年打败人类围棋冠军的阿尔法狗背后的 AI 创企 DeepMind,就是由谷歌收购。
这一年 5 月,谷歌 CEO 桑德·皮查伊(Sundar Pichai)宣布将公司策略从“移动为先”转变成“人工智能为先”(AI First),并计划在公司的每一个产品上都应用机器学习算法。
OpenAI 诞生的初衷,部分原因就是为了避免谷歌在人工智能领域形成垄断。OpenAI 起初是一个非营利组织,但在 2019 年成立 OpenAI LP 子公司,目标是盈利和商业化,并引入了微软的 10 亿美元投资。前 YC 孵化器总裁阿尔特曼就是此时加入 OpenAI 担任 CEO。
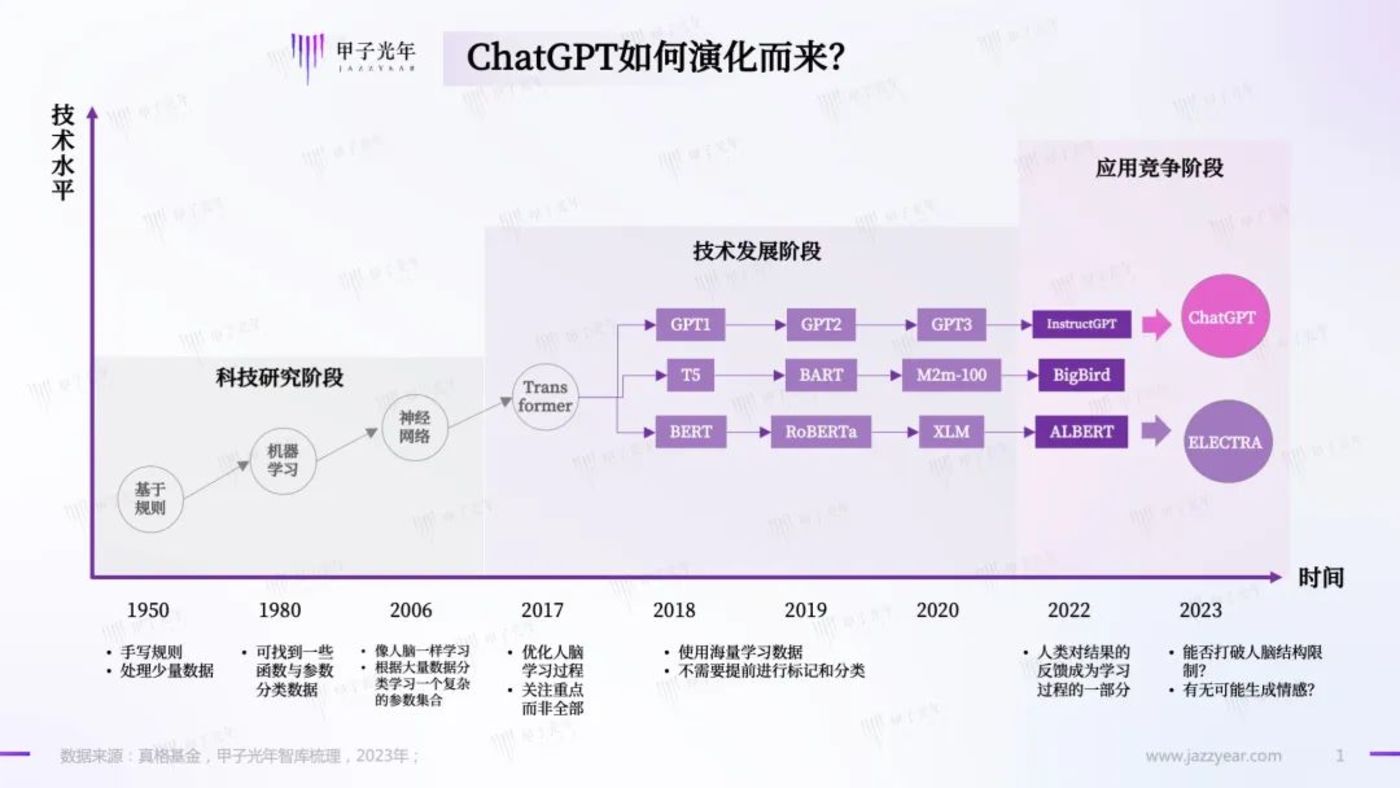
ChatGPT 名字中的 GPT(Generative Pre-trained Transformer ,生成式预训练变换器),是 OpenAI 推出的深度学习模型。ChatGPT 就是基于 GPT-3.5 版本的聊天机器人。
GPT 的名字中包含了大名鼎鼎的 Transformer,这是由谷歌大脑团队在 2017 年的论文《Attention is all you need》中首次提出的模型。现在来看,这是人工智能发展的里程碑事件,它完全取代了以往的 RNN(循环神经网络)和 CNN(卷积神经网络)结构,先后在 NLP(自然语言处理)、CV(计算机视觉)领域取得了惊人的效果。
最初的 Transformer 模型有 6500 个可调参数,是当时最先进的大语言模型(Large Language Model, LLM)。谷歌公开了模型架构,任何人都可以用其搭建类似架构的模型,并结合自己手上的数据进行训练。
特斯拉自动驾驶,预测蛋白质结构的 AlphaFold2 模型,以及本文的主角 OpenAI 的 GPT,都是在 Transformer 的基础上构建的。正如它的中文名字一样——变形金刚。
Transformer 出现之后,很多公司基于 Transformer 做 NLP 模型研究,其中 OpenAI 与谷歌就是最重要的两家。
2018 年,OpenAI 推出了 1.17 亿参数的 GPT-1,谷歌推出了 3 亿参数的 BERT,双方展开了一场 NLP 的较量。
GPT 与 BERT 采用了不同的技术路线。简单理解,BERT 是一个双向模型,可以联系上下文进行分析,更擅长“完形填空”;而 GPT 是一个单项模型,只能从左到右进行阅读,更擅长“写作文”。
两者的表现如何呢?发布更早的 GPT-1 赢了初代 Transformer,但输给了晚 4 个月发布的 BERT,而且是完败。在当时的竞赛排行榜上,阅读理解领域已经被 BERT 屠榜了。此后,BERT 也成为了 NLP 领域最常用的模型。
但是这场 AI 竞争才刚刚开始。OpenAI 既没有认输,也非常“头铁”。虽然 GPT-1 效果不如 BERT,但 OpenAI 没有改变策略,而是坚持走“大模型路线”。
在 OpenAI 眼中,未来的通用人工智能应该长这个样子:“有一个任务无关的超大型 LLM,用来从海量数据中学习各种知识,这个 LLM 以生成一切的方式,来解决各种各样的实际问题,而且它应该能听懂人类的命令,以便于人类使用。”
换句话说,就是大力出奇迹!
接下来的两年(2019、2020 年),在几乎没有改变模型架构的基础上,OpenAI 陆续推出参数更大的迭代版本 GPT-2、GPT-3,前者有 15 亿参数,后者有 1750 亿参数。
GPT-2 在性能上已经超过 BERT,到 GPT-3 又更进一步,几乎可以完成自然语言处理的绝大部分任务 ,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答,甚至还可以依据任务描述自动生成代码。
GPT-3 大获成功。OpenAI 在早期测试结束后开始尝试对 GPT-3 进行商业化,付费用户可以通过 API 使用该模型完成所需语言任务,比如前文提到的 AI 绘画独角兽 Jasper 就是 GPT-3 的客户。
值得一提的是,这个过程中谷歌也在不断推出新的模型。但不同于 OpenAI“从一而终”地坚持 GPT 路线,谷歌在 BERT 之后也推出了 T5、Switch Transformer 等模型,类似于赛马机制。
此时距离 ChatGPT 的诞生还差一步。
3. 意料之外的走红
在 GPT-3 发布之后,OpenAI 研究人员在思考如何对模型进行改进。
他们发现,要想让 GPT-3 产出用户想要的东西,必须引入“人类反馈强化学习机制”(RLHF),通过人工标注对模型输出结果打分建立奖励模型,然后通过奖励模型继续循环迭代。
而聊天机器人就是引入强化学习的最佳方式,因为在聊天过程中,人类的对话就即时、持续地向模型反馈数据,从而让模型根据反馈结果进行改进。因为加入了人工标注环节,OpenAI 为此雇佣了大约 40 位外包人员来与机器人对话。
通过这样的训练,OpenAI 获得了更真实、更无害,并且更好地遵循用户意图的语言模型 InstructGPT,在 2022 年 3 月发布,并同期开始构建 InstuctGPT 的姊妹模型——ChatGPT。
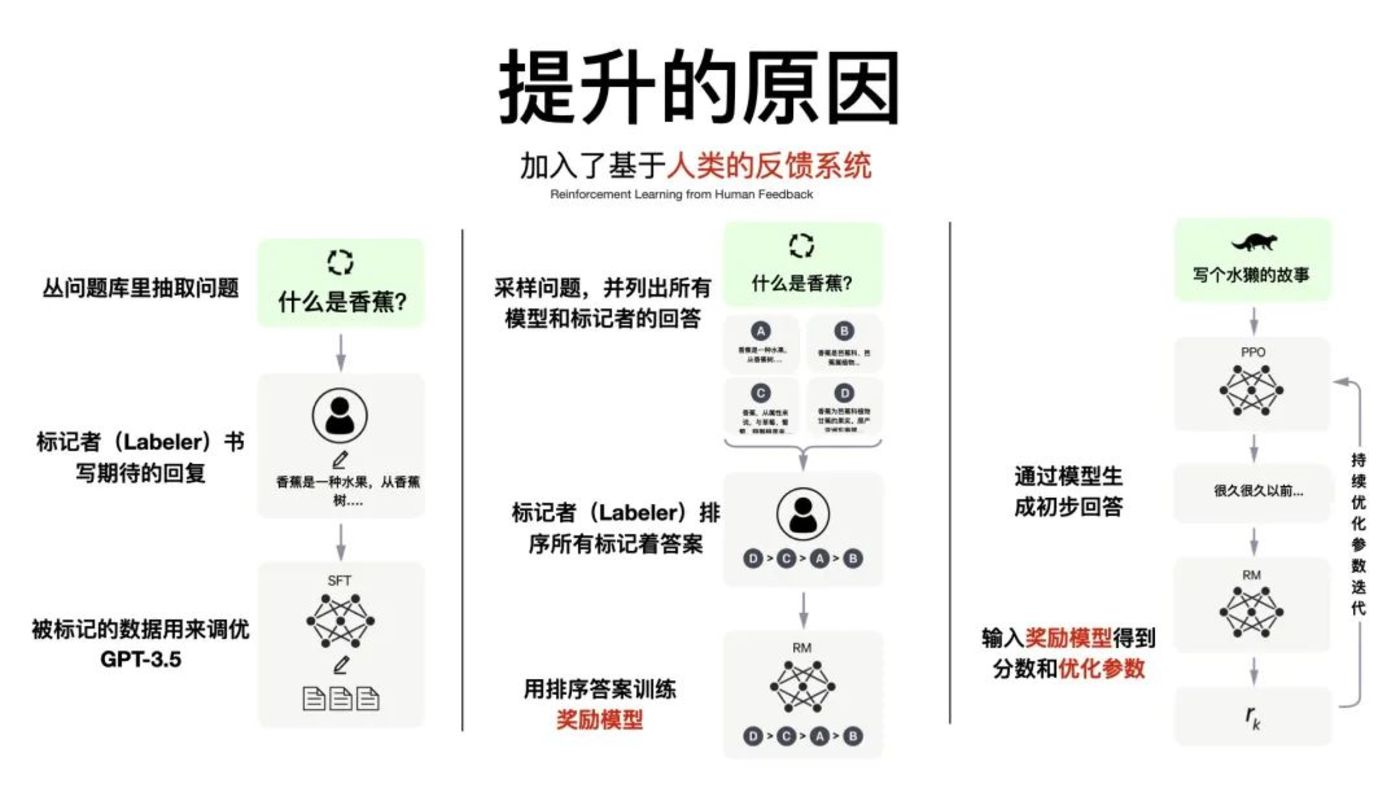
图片来源真格基金
根据《财富》杂志报道,当 ChatGPT 准备就绪后,OpenAI 一开始并没有想把它向公众开放,而是先让测试人员使用。
但根据 OpenAI 联合创始人兼现任总裁 Greg Brockman 的说法,这些测试人员不清楚应该与这个聊天机器人谈论什么。后来,OpenAI 试图将 ChatGPT 转向特定领域的专业人士,但缺乏专业领域的训练数据。
OpenAI 最终不得不决定将 ChatGPT 向公众开放。“我承认,我不知道这是否会奏效。” Brockman 说。
在《纽约时报》的报道中,OpenAI 发布 ChatGPT 还有另外一个理由:担心对手公司可能会在 GPT-4 前发布他们的人工智能聊天机器人,因此要抢先发布。
总之,在 2022 年 11 月 30 日这天,ChatGPT 诞生了。
ChatGPT 成为了史上蹿红最快的应用。发布第五天,ChatGPT 就积累了 100 万用户,这是 Facebook 花了 10 个月才达到的成绩;发布两个月,ChatGPT 突破了 1 亿用户,对此 TikTok 用了大约九个月,Instagram 用了两年多。
ChatGPT 的迅速传播连 OpenAI 也猝不及防,OpenAI 首席技术官 Mira Murati 说:“这绝对令人惊讶。”在旧金山 VC 活动上 OpenAI CEO 阿尔特曼说,他“本以为一切都会少一个数量级,少一个数量级的炒作”。
值得一提的是,OpenAI 并非唯一的大模型聊天机器人。2021 年 5 月,谷歌也发布了专注于生成对话的语言模型 LaMDA,但直到现在谷歌仍未对外“交卷”。本周谷歌匆忙发布的用于对抗 ChatGPT 的聊天机器人 Bard 就由 LaMDA 支撑,但 Bard 的上线日期也未公布。
在这场 OpenAI 与谷歌持续数年的大模型竞争中,谷歌最终落了下风。
4. 代价是什么?
但 ChatGPT 的成功,也让 OpenAI 付出了代价,“烧钱”的代价。
过去几年,大模型俨然成为了一场 AI 的军备竞赛。在 2015 年至 2020 年期间,用于训练大模型的计算量增加了 6 个数量级,在手写、语音和图像识别、阅读理解和语言理解方面超过了人类性能基准。
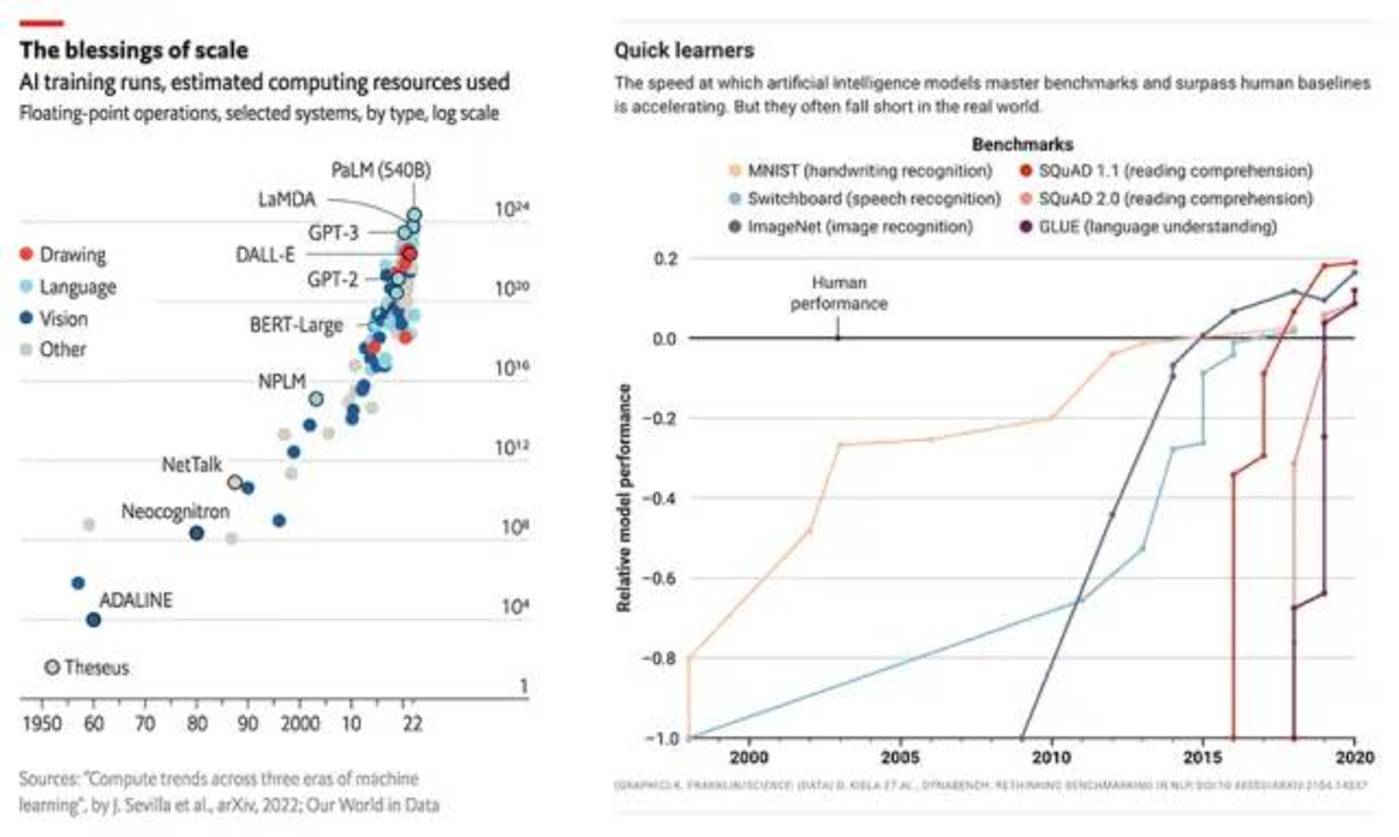
图片来自红杉资本
OpenAI 的成功让人们见识到了大模型的威力,但是大模型的成功可能难以复制,因为太烧钱了。
OpenAI 很早就意识到,科学研究要想取得突破,所需要消耗的计算资源每3~4 个月就要翻一倍,资金也需要通过指数级增长获得匹配。而且,AI 人才的薪水也不便宜,OpenAI 首席科学家 Ilya Sutskever 在实验室的头几年,年薪为 190 万美元。
OpenAI CEO 阿尔特曼在 2019 年对《连线》杂志表示:“我们要成功完成任务所需的资金比我最初想象的要多得多。”
这也是 OpenAI 从非营利性组织成立商业化公司的原因。2019 年 7 月,重组后的 OpenAI 获得了微软的 10 亿美元投资,可借助微软的 Azure 云服务平台解决商业化问题,缓解高昂的成本压力。
解决了粮草问题的 OpenAI,开始全力训练大模型。
大模型背后离不开大数据、大算力。GPT-2 用于训练的数据取自于 Reddit 上高赞的文章,数据集共有约 800 万篇文章,累计体积约 40G;GPT-3 模型的神经网络是在超过 45TB 的文本上进行训练的,数据相当于整个维基百科英文版的 160 倍。
在算力方面,GPT-3.5 在微软 Azure AI 超算基础设施(由 V100GPU 组成的高带宽集群)上进行训练,总算力消耗约 3640PF-days(即每秒一千万亿次计算,运行 3640 天)。
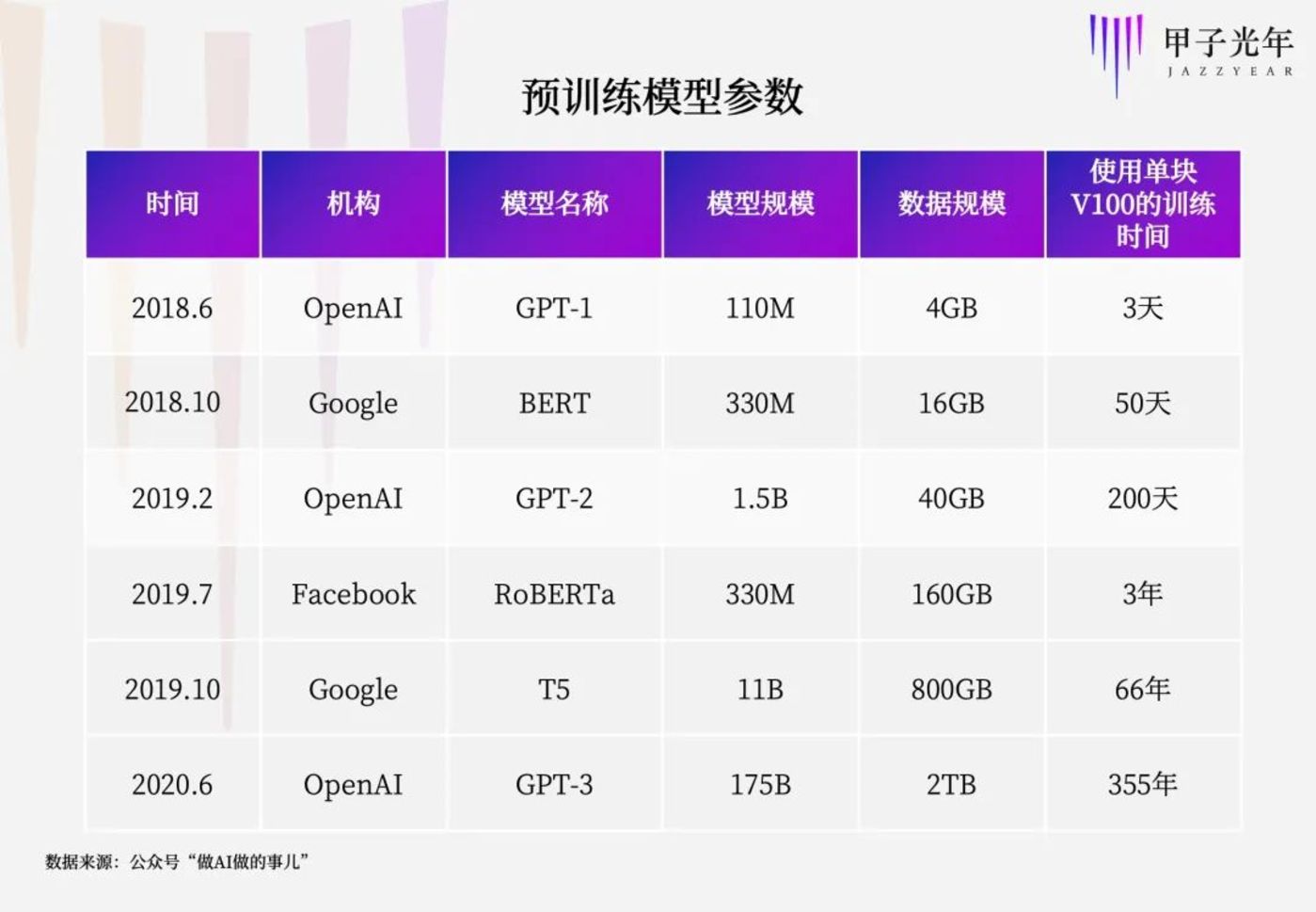
可以说,大模型的训练就是靠烧钱烧出来的。据估算,OpenAI 的模型训练成本高达 1200 万美元,GPT-3 的单次训练成本高达 460 万美元。
根据《财富》杂志报道的数据,2022 年 OpenAI 的收入为 3000 万美元的收入,但净亏损总额预计为 5.445 亿美元。阿尔特曼在推特上回答马斯克的问题时表示,在用户与 ChatGPT 的每次交互中 OpenAI 花费的计算成本为“个位数美分”,随着 ChatGPT 变得流行,每月的计算成本可能达到数百万美元。
大模型高昂的训练成本让普通创业公司难以为继,因此参与者基本都是的科技巨头。
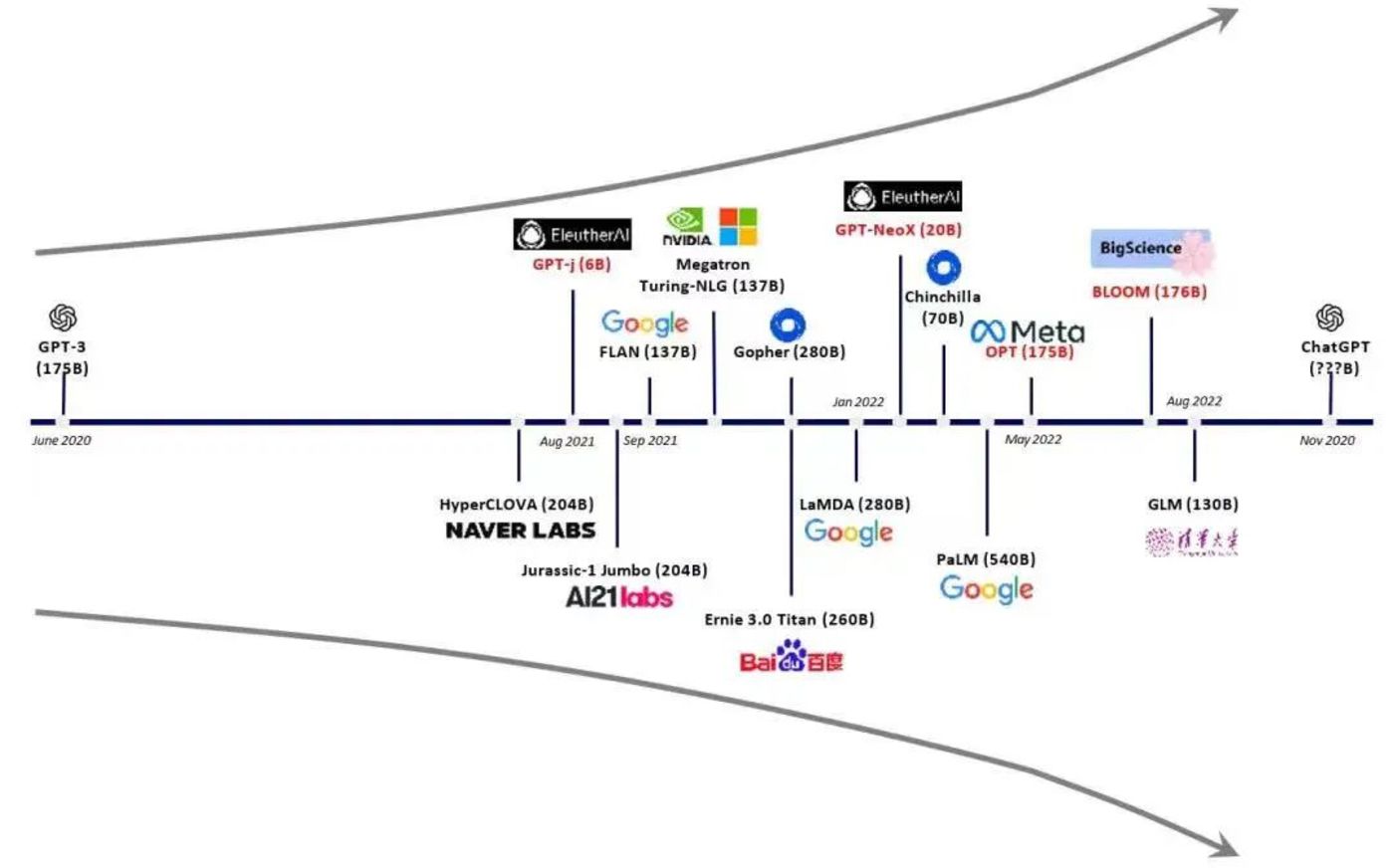
图片来自陈巍博士
在国内科技公司中,阿里巴巴达摩院在 2020 年推出了 M6 大模型,百度在 2021 年推出了文心大模型,腾讯在 2022 年推出了混元 AI 大模型。
一个需要明确的事实是,虽然 OpenAI 的大模型取得了成功,但模型并非绝对意义上的越大越好,参数量也只是影响最终模型性能的因素之一。
GPT-3 也不是参数最大的模型,比如,由英伟达和微软开发的 Megatron-Turing NLG 模型,拥有超过 5000 亿个参数,但在性能方面并不是最好的,因为模型未经充分的训练。
实际上,在特定场景下,较小的模型可以达到更高的性能水平,而且成本更低。
一位 AI 从业者告诉「甲子光年」:“现实就是,NLP 公司做 to B 只能做小模型。得私有化,工程性能好,计算消耗少。甲方还希望你能部署在 CPU 上呢。”
关于大模型与小模型的关系,我们会在后面的文章中继续讨论。
5. 钱都流向了哪里?
以 ChatGPT 为代表的生成式 AI 正在引发新一轮 AI 军备竞赛,这个特别烧钱的新兴市场,也让背后的基础设施厂商赚得盆满钵满。
著名风投机构 A16Z 将生成式 AI 市场分成了三层:
◆ 应用层:将第三方 API 或自有模型集成到面向用户的产品中,比如 AI 绘画应用 Jasper、Midjourney;
◆ 模型层:为应用层提供能力,比如闭源的 GPT-3,或者开源的 Stable diffusion;
◆ 基础设施层:为生成人工智能模型运行培训和推断工作负载的云平台和硬件制造商。
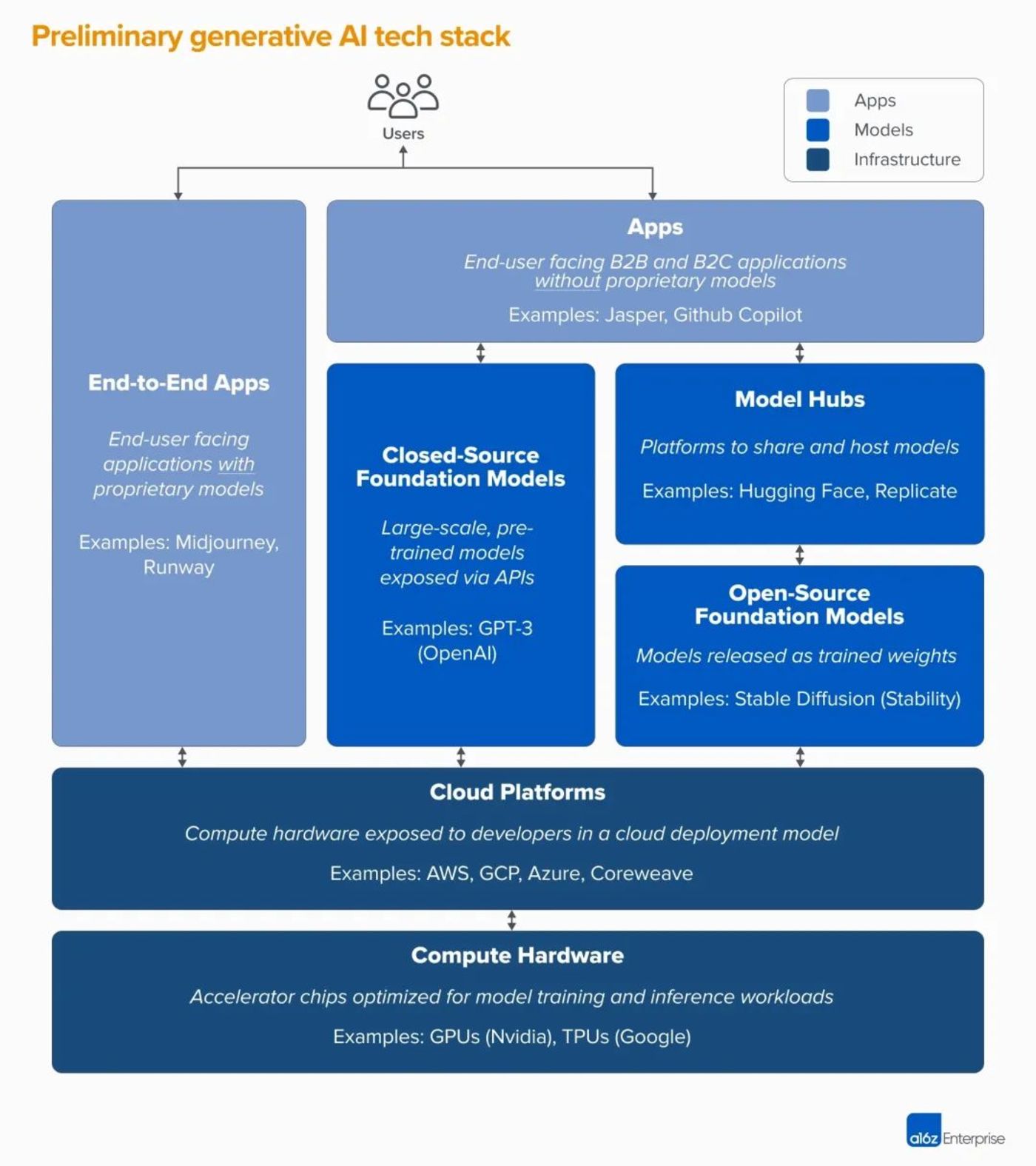
图片来自 A16Z
生成式 AI 的大量资金最终都稳定地流向了基础设施层——以亚马逊 AWS、微软 Azure、谷歌 GCP 为主的云厂商,以及以英伟达为代表的 GPU 厂商。
据 A16Z 估计,应用层厂商将大约 20%~40% 的收入用于推理和模型微调,这部分收入通常直接支付给云厂商或第三方模型提供商,第三方模型提供商也会将大约一半的收入用于云基础设施。因此,总的来看生成式 AI 总收入的 10%~20% 都流向了云提供商。
微软投资 OpenAI 就是一个很好的案例。
2019 年微软投资 OpenAI 10 亿美元,其中大约一半以 Azure 云计算的代金券形式,成为 OpenAI 技术商业化的“首选合作伙伴”,未来可获得 OpenAI 的技术成果的独家授权。今年 1 月 23 日,微软再次加码,宣布向 OpenAI 追求数十亿美元,来加速人工智能的突破。
根据《财富》杂志报道,在 OpenAI 的第一批投资者收回初始资本后,微软将有权获得 OpenAI 75% 的利润直到收回投资成本;当 OpenAI 赚取 920 亿美元的利润后,微软的份额将降至 49%。与此同时,其他风险投资者和 OpenAI 的员工也将有权获得 OpenAI 49% 的利润,直到他们赚取约 1500 亿美元。如果达到这些上限,微软和投资者的股份将归还给 OpenAI 的非营利基金会。
本质上,OpenAI 是在把公司借给微软,借多久取决于 OpenAI 赚钱的速度。微软对 OpenAI 的投资更大的野心在于,希望在下一个人工智能的十年向谷歌以及其他科技巨头发起挑战。
在今年 1 月份的瑞士达沃斯论坛期间,微软 CEO 纳德拉表示,微软将全线接入 ChatGPT,计划将 ChatGPT、DALL-E 等人工智能工具整合进微软旗下的所有产品中,包括且不限于 Bing 搜索引擎、Office 全家桶、Azure 云服务、Teams 聊天程序等等。
本周,新版 Bing 正式发布。纳德拉霸气表示:“比赛今天开始了,我们将继续前进并快速行动,希望在搜索领域再次获得更多创新的乐趣。”
除了微软之外,英伟达则是生成式 AI 幕后最大的赢家。
云厂商每年总共花费超过 1000 亿美元的资本支出,来确保他们能够拥有最全面、最可靠和最具成本竞争力的平台,比如获得英伟达最先进、也是最稀缺的 GPU——A100 与 H100。GPU 成为了生成式 AI 发展上限“卡脖子”的一环。
英伟达过去一个月的股价涨幅甚至超过了微软。
ChatGPT 在科技圈引发的震动仍在持续。一个不可否认的事实是,国内的 AI 公司多少处于一种置身之外的感受。人们惊叹于技术的进步,也感慨于实力的差距。
对此,云知声创始人黄伟如此评价:
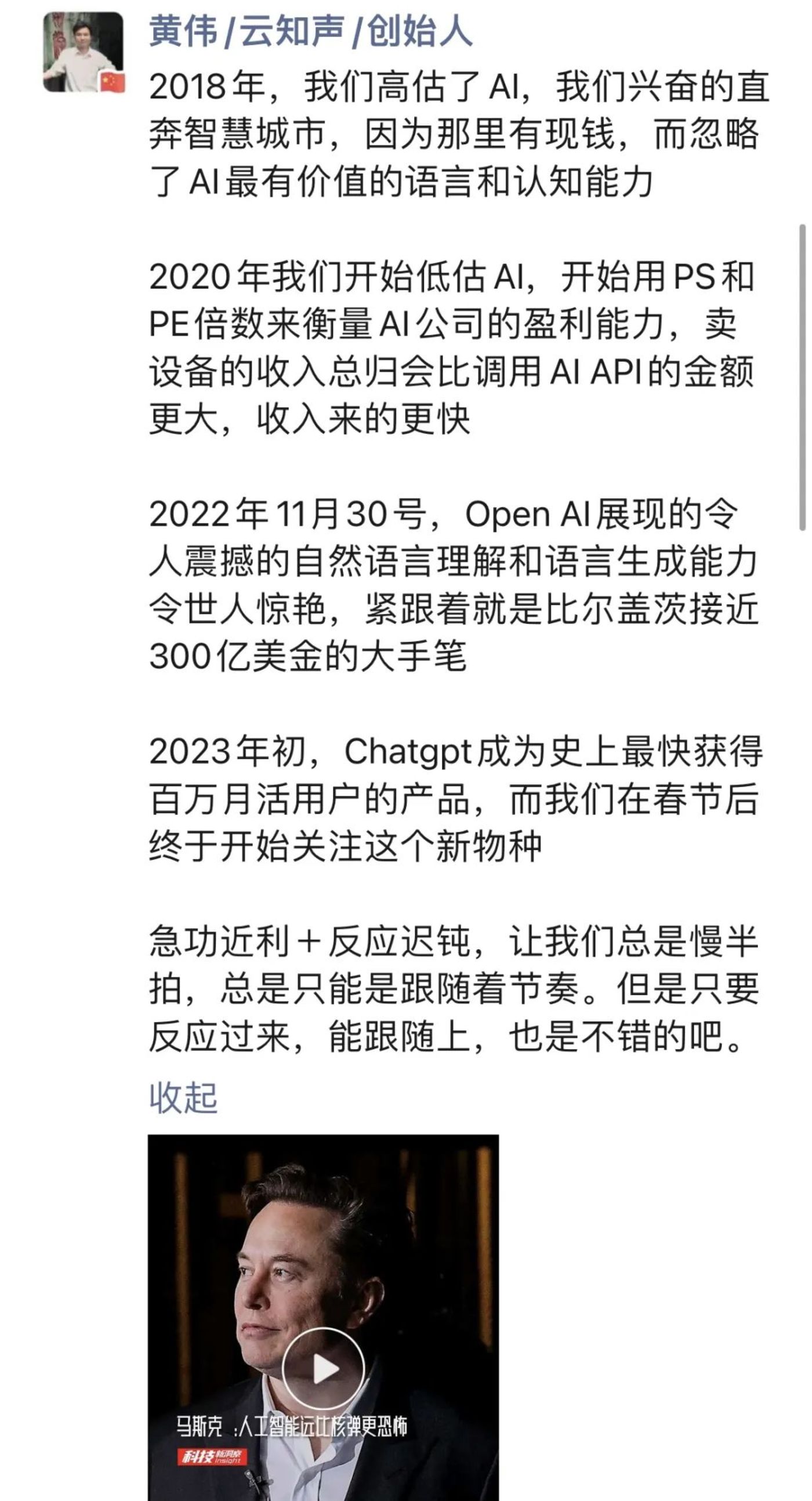
接下来,国内科技公司会如何接招呢?
参考资料:
[1]Generative AI: A Creative New World,红杉资本
[2]Who Owns the Generative AI Platform?,A16Z
[3]万字长文:AI 产品经理视角的 ChatGPT 全解析,马丁的面包屑
[4]OpenAI 是如何胜过谷歌的?ChatGPT 发展简史,做 AI 做的事儿
[5]ChatGPT 的内幕:OpenAI 创始人 Sam Altman 如何用微软的数十亿美元打造了全球最热门技术,MoPaaS






