
羿阁整理自 MEET2023
量子位公众号 QbitAI
随着 Stable Diffusion、ChatGPT 的爆火,AI 在今年迎来了大爆发。
这不禁让人想问,这些创新背后的推动机制究竟是什么?
在 MEET2023 智能未来大会上,阿里巴巴集团副总裁、阿里云计算平台事业部负责人贾扬清给出了他的答案:AI 工程化和开源。
工程化,让开发、迭代到应用的路径变得更加高效;开源可以让工作开展更加迅速,实现市场共赢。
在这个基础之上,贾扬清还进一步指出了 AI 产业落地的四大明显趋势:AI 工程化平台、异构计算、智能产品和算法开源。

为了完整体现贾扬清的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。
关于 MEET 智能未来大会:MEET 大会是由量子位主办的智能科技领域顶级商业峰会,致力于探讨前沿科技技术的落地与行业应用。今年共有数十家主流媒体及直播平台报道直播了 MEET2023 大会,吸引了超过 300 万行业用户线上参会,全网总曝光量累积超过 2000 万。
演讲要点
- 工程化和开源是 AI 普惠最重要的支撑。
- 目前 AI 产业应用有四个趋势:云原生的 AI 工程化平台、端到端优化的异构计算体系、通过系统组合打造贴近用户的智能产品,以及算法的开源助力 AI 在垂直产业的广泛应用。
- 随着模型变得越来越大、训练门槛越来越高,我们可以清晰地看见,业界的需求从代码开源往前一步,到了模型的开源。
(以下为贾扬清演讲全文)
AIGC 大爆发
今天我们讲 AI,绕不过去的一个话题就是 AIGC 的大爆发,像 Stable Diffusion、ChatGPT 等等。
如果我们溯源可以发现,用统计和 AI 方法实现内容的创作和生成,已经经历了很长的演进过程。
往回数到 1999 年,也就是二十多年前的时候,Alexei A. Efros 教授提出的基本逻辑是用一个简单的计算机视觉统计方式,就可以通过一个非常小的图片来学习纹理,并生成更大的内容,这可以说是 AIGC 的雏形。
2015 年前后,神经风格迁移开始风靡,它能够从画作当中学习绘画风格,把原始图片合成为特定风格的作品,比如这幅梵高的《星空》。

从 1999 年的纹理生成,到 2015 年的神经风格迁移,再到今天更强语意的 AI 创作,都在不断地催生我们探索更有意思的领域。
同时,我们也在思考,这些创新推动的机制是怎么样的?背后有哪些的支撑?
AI 惠普的土壤:工程化+开源
我们得出的结论是,AI 普惠的两个重要支撑,一个是 AI 的工程化,另外一个是开源。
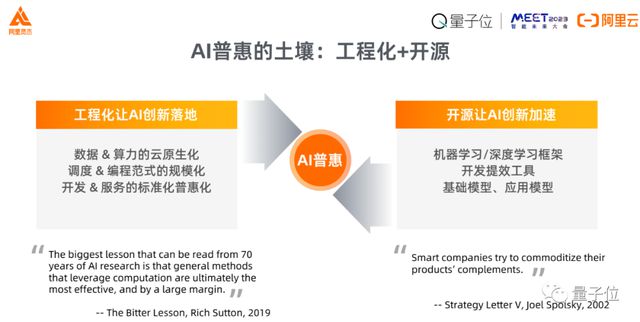
从工程化角度,2019 年著名教授 Richard Sutton 曾经说过,前面 70 年的 AI 研究,我们所得到的最大的经验和教训是通过标准化的方式来使用大规模的计算。
那么怎么样才能实现大规模计算呢?
无论是通过云原生方式,还是通过更加高效的分布式计算等,都让今天从开发到迭代的路径变得更加简单,这都是我们前面几年所看到的 AI 大规模发展(如大模型、AIGC)背后的工作。
另外一个方面,开源让工作变得更加迅速。
从最早的时候我们耳熟能详的深度学习框架,到今天我们所见到的各种模型,无论是基础模型还是应用模型,开源和开放都让各行各业的应用开发者更加容易触达 AI 算法,并寻找一些需求的匹配。
同时,对于算法的工作要求。Stack Overflow 的创始人 Joel Spolsky 曾经写过一个关于开源软件经济学的技术 blog。
他提到,技术公司都希望让产品的互补品变得更加容易获得,开源让整个市场变得更大,也能够让大家实现共赢的结果。
在此基础上,AI 产业落地有四个非常明显的趋势。
第一是云原生的 AI 工程化平台;第二是大规模端到端的异构计算体系;第三是把前面这些工程产生的算法系统组合后,实现的更加智能、贴近用户需求的产品;以及通过算法的开源,助力 AI 在产业垂直化落地。
这四个趋势可能是将来我们无论是从供给角度还是需求角度,推动 AI 进一步往前走的方向。

所以我想从这四个角度给大家简单介绍一下我们现在所看到一些细节和所做的事情。
AI 工程化平台
今天我们看到 AI 开发有一个非常清晰的范式,可以分两个部分,前半段是开发、数据到模型,后半段从模型、迭代到最后的应用。
具体地说,首先,算法工程师会通过数据平台做数据采集、清理、标注。在开发的时候,一个开源的、耳熟能详的环境已经成为业界标准,能够让算法工程师进行开发、迭代。
今天大多数的模型都需要用到分布式计算,这些技术已经成为标准底座,让我们更加高效地做分布式训练、调度和部署。
产出最开始这些模型之后,我们就需要让业务工程师和深度学习的算法工程师一块在实际当中做模型选型、验证等等,再通过前面提到的开发、迭代、训练这些平台,来获得一个适合线上服务的模型。
有一个很有意思的点,大家在实际做一个业务应用的时候,有很多事情都要考虑。
AI 以前想得比较少,但今天一旦开始把 AI 算法部署到应用当中去,很多需求就都已经出来了,像蓝绿部署等等,因此服务本身也在开始变得更加标准化、原生化。
今天在阿里云,我们就把这些开发范式标准化以后,建设这样一个平台,支撑我们从零开始做模型的全新服务。

大家经常问工程化可以实现怎么样的效果?
每个科研院所、公司大家多多少少都在经历这样一个过程:怎样把 AI 从科研到普惠的鸿沟填上,用高性能、高可用、低成本的方式把这个沟跨过去。
跟大家分享一个小故事,今年达摩院和阿里云一起做了一件事情,就是重新审视我们在 AI 算法协同当中怎么样把达摩院超过 90% 的应用,不论是训练还是推理服务的应用,都用云原生方式来实现。
通过这样的方式,我们所见到的是:
从需求的角度,资源更加可用、更容易获得,无论是拉起一个训练还是推理,都比以前更加容易,更快;
从工程细节上,算法工程师不再需要进行像存储、管理机器、调优带宽等等这些具体的事情;
从供给角度、AI 系统管理角度来说,无论是利用率、训练效率,还是服务成本都变得更好了。
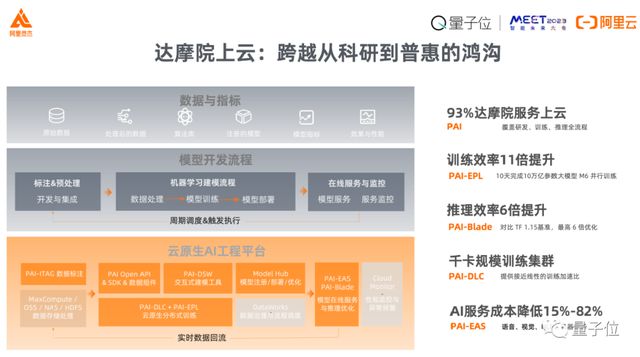
这是我们在第一个趋势——AI 工程化这块所看见的正向效果,就是专业人做专业的事,以达到一个更好的效果。
异构计算
AI 工程化平台之后,第二个趋势是端到端的异构计算与优化。
今天讲框架讲得比较少,传统的 AI 框架这一层,无论是最早的还是今天的框架,方向已经变得很成熟了。
同时,在框架上游和框架的下游,我们都开始逐渐地需要来建设更加丰富的软件栈。
包括上层怎么样让算法科学家做分布式建模,调动异构资源进行训练;在框架下层怎么样通过 AI 技术做软硬件协同设计和优化,最后我们怎么样建立这样一个存储、网络完整的优化解决方案。
和大家分享几个我们所做的工作。
第一在分布式建模这一块,我们开源了一个框架 EPL,使得算法工程师建模时能够更加容易地自动化生成分布式训练模型,而不需要自己手工地处理 GPU 之间怎么样通讯。
在优化领域,我们的框架 PAI-Blade,能够帮助算法工程师在面对底层硬件时不需要去担心,比如 CPU、GPU、非常多的创新建设出来的国产芯片等等,我们可以用这种方式更有效地提升算法效率。
这个领域最有意思的一点是,我们发现 AI 计算和传统科学计算的需求有很强的共性,无论是蛋白质分子折叠的研究,还是其他物理、化学等领域,AI for Science 这个趋势都很明显。
我们需要做的工作包括大规模基于矩阵的计算,以及需要处理海量的领域数据,而 AI 系统、数据系统所积累下来的异构计算的能力正好符合这个需求。
同时,一定程度上说,这些能力最早也是从 HPC 这些领域,比如气象模拟孵化出来的。
就像郑院士刚才提到的 AII-Reduce 并行的范式,这个范式最早也是在 HPC 领域有了非常好的理解,在我们看起来是一个 AI for Science 和 Science for AI 互相迭代的过程。
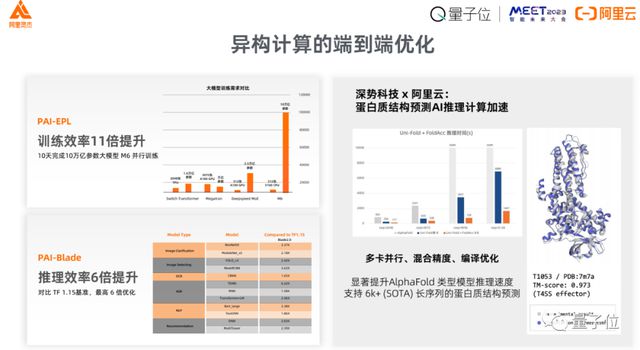
这些框架上和框架下的优化,最终还是需要把所有的组件协同起来,带来一个更加完整、更加成熟的,我们称作“智算”的一个完整解决方案,这些解决方案能够达到软硬件协同、算法应用协同等效果。
举个例子,在自动驾驶这方面,我们和小鹏汽车建设了一系列自动驾驶所需要的海量 AI 计算能力技术。
每个单点技术看起来都比较标准,但是端到端连起来的时候,我们也碰到一个挑战,就是怎么样把存储、计算、AI 组件更加完整组合在一起,这里面有很多细致入微的挑战。

就像刚才郑院士提到的检查点怎么样做读写,怎么样把存储带宽提上来,虽然乍一听是很细节的事,但是非常精准地提到了我们系统所需要解决的问题,就是确保一个木桶没有短板,unblock 整个开发训练的流程。
智能产品
我们所见到第三个趋势,往往会涉及到多种模型、多种算法的组合。
各种单点 AI 算法越来越成熟之后,我们可以更容易地组合一个贴近客户的智能产品,这也是很多用户实际需要的一个 AI 中台,因为我们并不需要一个单体模型,我们需要解决问题。
拿“听悟”智能会议助理举例,这是达摩院语音实验室把语音、自然语言处理和其他的算法组合起来后建设而成,因为会议的原因,我在会前录了一个非常简短的实际使用的 Demo,请大家来感受一下。
算法开源
最后我觉得还有一个非常强的趋势就是模型开源。
像听悟这样一个产品,背后有非常非常多的模型,我们今天说 AI 工程化、异构计算等等,最后就是基于模型来落地。
这里我重复一下李笛老师刚刚提到的 AI being 的概念,将来也许每一个人、每一个公司都多多少少需要有 AI being 的能力。
那么问题来了,模型变得越来越大,门槛越来越高后,是不是每个公司都要投入很多的资金和人力?是不是都要先通过训练再做其他的事情?
我们的回答是“no”,今天代码开源已经非常深入人心了,我们可以清晰地看见,业界的需求从代码的开源往前一步,到了模型的开源。
今年达摩院和业界很多伙伴一起推出了 ModelScope,我觉得它跟以前所见到的学术模型不一样,我们更进一步的地方是我们将实际业务当中所见到的、训练的、沉淀下来的实际场景化的模型都贡献了出来,今天大家可以在魔搭上面找到 300 多个成熟的模型。
举个例子,比如像语音可以找到不同方言的、中英混杂的,这种通用的学术模型可能不太关注,但是在应用当中很需要的模型。
最新的像 Stable Diffusion 这些模型,你也可以在上面实现浏览、尝试下载开发、二次开发等等。
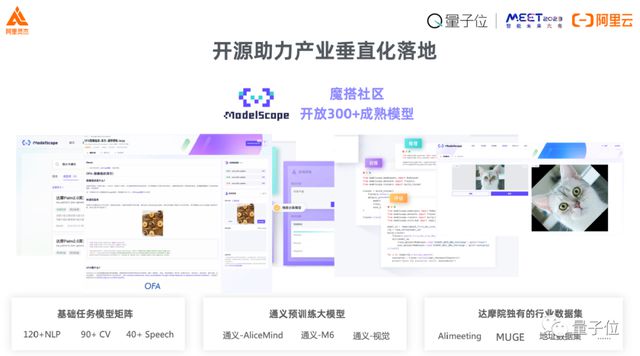
这样一个社区能够让我们在供应和需求两个方面都更进一步。
从供给角度来说,我们希望能够提供一个场子,这个场子让更多算法开发者能够更方便地把模型开源出来、共享出来,就像是把代码放在一个平台上一样,让大家更容易分享模型,更容易搭建一个模型的 Demo,把这个秩序轮转起来。
第二从需求角度,我们希望能够给对 AI 感兴趣的群体找到一个更容易的方式体验模型、思考需求,通过这样把很多的想法迭代起来,就是到底这个模型能做什么,如何把这些产品做得更加丰富。
我们希望这个平台成为一个连接两边需求,把两边更好结合起来,迸发创新的应用。
总结一下,在开源和工程化这样的大背景下,我们看见 AI 产业有四大很明显的趋势:云原生的 AI 工程化平台、大规模端到端的异构计算体系、智能产品,以及最后算法开源崛起。因为时间关系,每一点可能没法更详细展开。
今天,非常多的专家、企业、开发者们在建设着上层的 AI 算法;而在 AI 底层,如何让工具变得更加易用、更加普惠,这正是我们在做的事情。
从去年开始,我就在做阿里灵杰,无论从数据管理、数据治理、算法开发,到完整的 AI 智算解决方案,目的是能够提供一个用户友好、高性能、高弹性的产品和能力。
非常感谢大家今天能够花 15 分钟时间听我的分享,疫情现在放开了,希望有机会能够在线下见面,或者通过线上进行技术上或业务上的一些交流,再次谢谢大家!






