
新智元报道
编辑:LRS
谷歌带着更强大的图像生成模型来了,依然 Transformer!
最近谷歌又发布了全新的文本-图像生成 Muse 模型,没有采用当下大火的扩散(diffusion)模型,而是采用了经典的 Transformer 模型就实现了最先进的图像生成性能,相比扩散或自回归(autoregressive)模型,Muse 模型的效率也提升非常多。

论文链接:https://arxiv.org/pdf/2301.00704.pdf
项目链接:https://muse-model.github.io/
Muse 以 masked modeling 任务在离散 token 空间上进行训练:给定从预训练的大型语言模型(LLM)中提取的文本嵌入,Muse 的训练过程就是预测随机 masked 掉的图像 token。
与像素空间的扩散模型(如 Imagen 和 DALL-E 2)相比,由于 Muse 使用了离散的 token,只需要较少的采样迭代,所以效率得到了明显提高;
与自回归模型(如 Parti)相比,由于 Muse 使用了并行解码,所以效率更高。

使用预训练好的 LLM 可以实现细粒度的语言理解,从而转化为高保真的图像生成和对视觉概念的理解,如物体、空间关系、姿态、cardinality 等。
在实验结果中,只有 900M 参数的 Muse 模型在 CC3M 上实现了新的 SOTA 性能,FID 分数为 6.06。
Muse 3B 参数模型在 zero-shot COCO 评估中实现了 7.88 的 FID,同时还有 0.32 的 CLIP 得分。

Muse 还可以在不对模型进行微调或反转(invert)直接实现一些图像编辑应用:修复(inpainting)、扩展(outpainting)和无遮罩编辑(mask-free editing)。
Muse 模型
Muse 模型的框架包含多个组件,训练 pipeline 由 T5-XXL 预训练文本编码器,基础模型(base model)和超分辨率模型组成。
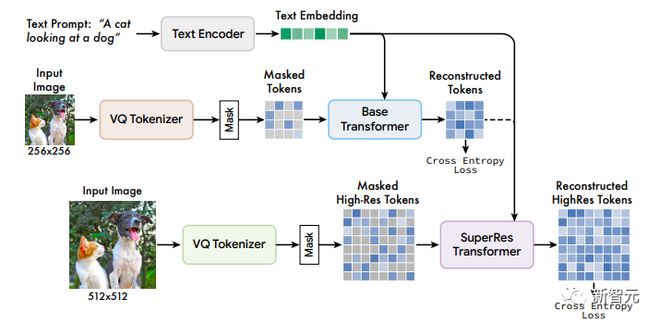
1. 预训练文本编码器
与之前研究中得出的结论类似,研究人员发现利用预训练的大型语言模型(LLM)有利于提升高质量图像的生成结果。
比如从语言模型 T5-XXL 中提取的嵌入(embedding)带有关于物体(名词)、行动(动词)、视觉属性(形容词)、空间关系(介词)以及其他属性(如卡片性和组成)的丰富信息。
所以研究人员提出假设(hypothesis):Muse 模型学会将 LLM 嵌入中的这些丰富的视觉和语义概念映射到生成的图像上。
最近也有一些工作已经证明了,由 LLM 学习到的概念表征与由视觉任务训练的模型学习的概念表征大致上是可以「线性映射」的。
给定一个输入的文本标题,将其传递给冻结参数的 T5-XXL 编码器,可以得到一个 4096 维的语言嵌入向量,然后将这些向量线性地投射到 Transformer 模型(base 和超分辨率)的 hidden size 维度上。
2. 使用 VQGAN 进行 Semantic Tokenization
VQGAN 模型由一个编码器和一个解码器组成,其中的量化层(quantization layer)将输入图像映射成来自一个学习过的 codebook 的 token 序列。
然后完全用卷积层建立编码器和解码器,以支持对不同分辨率的图像进行编码。
编码器中包括几个下采样块来减少输入的空间维度,而解码器中则是有相应数量的上采样块来将 latents 映射回原始图像大小。
研究人员训练了两个 VQGAN 模型:一个是下采样率f=16,模型在 256×256 像素的图像上获得基本模型的标记,从而得到空间尺寸为 16×16 的标记;另一个是下采样率f=8,在 512×512 的图像上获得超分辨率模型的 token,相应的的空间尺寸为 64×64。
编码后得到的离散 token 可以捕捉图像的高层次语义,同时也可以消除低层次的噪声,并且根据 token 的离散性可以在输出端使用交叉熵损失来预测下一阶段的 masked token
3. Base Model
Muse 的基础模型是一个 masked Transformer,其中输入是映射的 T5 嵌入和图像 token.
研究人员将所有的文本嵌入设置为 unmasked,随机 mask 掉一部分不同的图像 token 后,用一个特殊的[MASK]标记来代替原 token.
然后将图像 token 线性地映射到所需的 Transformer 输入或 hidden size 维度的图像输入 embedding 中,并同时学习 2D position embedding
和原始的 Transformer 架构一样,包括几个 transformer 层,使用自注意块、交叉注意力块和 MLP 块来提取特征。
在输出层,使用一个 MLP 将每个 masked 图像嵌入转换为一组 logits(对应于 VQGAN codebook 的大小),并以 ground truth 的 token 为目标使用交叉熵损失。
在训练阶段,基础模型的训练目标为预测每一步的所有 msked tokens;但在推理阶段,mask 预测是以迭代的方式进行的,这种方式可以极大提高质量。
4. 超分辨率模型
研究人员发现,直接预测 512×512 分辨率的图像会导致模型专注于低层次的细节而非高层次的语义。
使用级联模型(cascade of models)则可以改善这种情况:
首先使用一个生成 16×16 latent map(对应 256×256 的图像)的基础模型;然后是一个超分辨率模型,将基础 latent map 上采样为 64×64(对应 512×512 的图像)。其中超分辨率模型是在基础模型训练完成后再进行训练的。

如前所述,研究人员总共训练了两个 VQGAN 模型,一个是 16×16 潜分辨率和 256×256 空间分辨率,另一个是 64×64 潜伏分辨率和 512×512 空间分辨率。
由于基础模型输出对应于 16×16 latent map 的 token,所以超分辨率模块学会了将低分辨率的 latent map 「翻译」成高分辨率的 latent map,然后通过高分辨率的 VQGAN 解码,得到最终的高分辨率图像;该翻译模型也是以类似于基础模型的方式进行 text conditioning 和交叉注意力的训练。
5. 解码器微调
为了进一步提高模型生成细节的能力,研究人员选择通过增加 VQGAN 解码器的容量,添加更多的残差层(residual layer)和通道的同时保持编码器的容量不变。
然后对新的解码器进行微调,同时保持 VQGAN 编码器的权重、codebook 和 Transformers(即基础模型和超分辨率模型)不变。这种方式能够提高生成图像的视觉质量,而不需要重新训练任何其他的模型组件(因为视觉 token 保持固定)。

可以看到,经过微调的解码器以重建更多更清晰的细节。
6. 可变掩码率(Masking Rate)
研究人员使用基于 Csoine scheduling 的可变掩码率来训练模型:对于每个训练例子,从截断的 arccos 分布中抽出一个掩码率r∈[0,1],其密度函数如下.
掩码率的期望值为 0.64,也就是说更偏向于选择更高的掩码率,使得预测问题更加困难。
随机的掩码率不仅对并行采样方案至关重要,而且还能实现一些零散的、开箱即用的编辑功能。
7. Classifier Free Guidance(CFG)
研究人员采用无分类指导(CFG)来提高图像的生成质量和文本-图像对齐。
在训练时,在随机选择的 10% 的样本上去除文本条件,注意力机制降为图像 token 本身的自注意力。
在推理阶段,为每个被 mask 的 token 计算一个条件 logit lc 和一个无条件 logit lu,然后通过从无条件 logit 中移出一个量t作为指导尺度,形成最终的 logit lg:
直观来看,CFG 是以多样性换取保真度,但与以前方法不同的是,Muse 通过采样过程线性地增加指导尺度t来减少多样性的损失,使得 early token 可以在低引导或无引导的情况下更自由地被取样,不过也增加了对 later tokens 条件提示的影响。
研究人员还利用这一机制,通过将无条件的 logit lu 替换为以 negative prompt 为条件的 logit,促进了生成图像具有与 postive prompt 相关的特征。
8. 推理时迭代并行解码
在提升模型推理时间效率的一个关键部分是使用并行解码来预测单个前向通道中的多个输出 token,其中一个关键假设是马尔科夫属性,即许多 token 是有条件地独立于给定的其他 token 的。
其中解码是根据 cosine schedule 进行的,选择固定比例中最高置信度的掩码进行预测,其中 token 在剩余的步中被设定为 unmasked,并且适当减少 masked tokens。
根据上述过程,就可以在基本模型中只用 24 个解码步(step)实现对 256 个 token 的推理,在超分辨率模型中用 8 个解码步对 4096 个 token 进行推理,相比之下,自回归模型需要 256 或 4096 步,扩散模型需要数百步。
虽然最近的一些研究包括 progressive distillation、better ODE solver 大大减少了扩散模型的采样步骤,但这些方法还没有在大规模的文本到图像生成中得到广泛验证。
实验结果
研究人员以不同的参数量(从 600M 到 3B),基于 T5-XXL 训练了一系列基础 Transformer 模型。
生成图像的质量
实验中测试了 Muse 模型对于不同属性的文本提示的能力,包括对 cardinality 的基本理解,对于非单数的物体,Muse 并没有多次生成相同的物体像素,而是增加了上下文的变化,使整个图像更加真实。
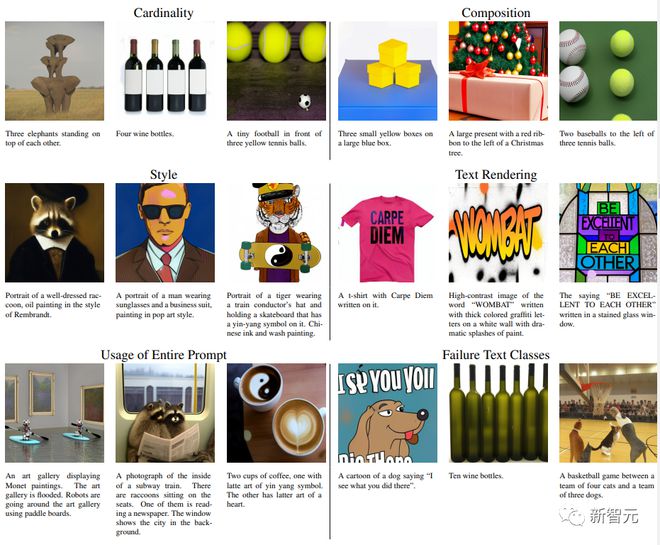
例如,大象的大小和方向、酒瓶包装纸的颜色以及网球的旋转等等。
定量比较
研究人员在 CC3M 和 COCO 数据集上与其他研究方法进行了实验对比,指标包括衡量样本质量和多样性的 Frechet Inception Distance(FID),以及衡量图像/文本对齐的 CLIP 得分。
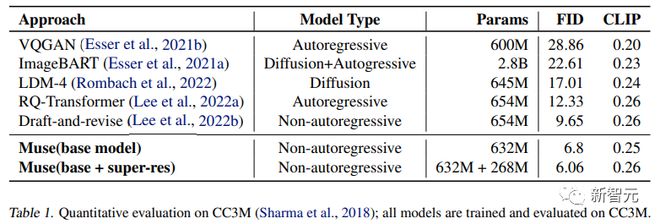
实验结果证明了 632M 的 Muse 模型在 CC3M 上取得了 SOTA 结果,在 FID 得分方面得到了改善,同时也取得了最先进的 CLIP 得分。
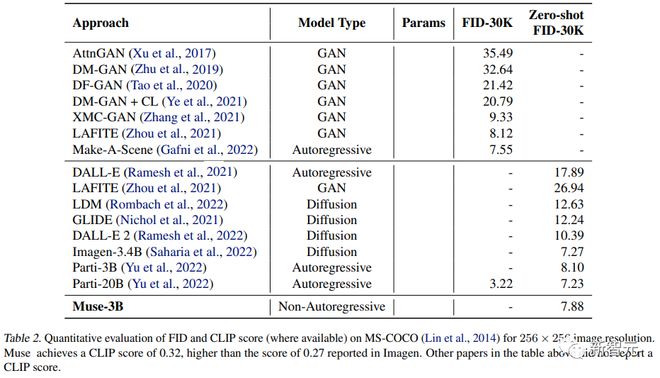
在 MS-COCO 数据集上,3B 模型取得了 7.88 分的 FID 得分,略好于相似参数量的 Parti-3B 模型取得的 8.1 分。
参考资料:






