
GameLook 报道/刚刚用 ChatGPT 在全球掀起 AI 狂热的 OpenAI,时隔三周就又拿出了最新的“科技与狠活”?本周,来自 OpenAI 的研究者正式发布了该公司最新的文字生成 3D 模型实验技术 Point-E,并在 GitHub 上公开了项目的源代码。这意味着这家 AI 巨头的业务版图在文字、音乐、图片等领域之外,又开辟了 3D 模型生成这片重要的疆土。

事实上,AI 生成 3D 模型技术在市面上已经出现过一波井喷。在元宇宙概念如日中天的如今,多家行业巨头都认为在全真互联网时代,人类对的 3D 内容的需求将大幅膨胀,进而寻求借助 AI 帮助人类实现超高效的 3D 内容生产。谷歌在今年 10 月发布的 DreamFusion 和英伟达在 11 月发布的 Magic3D 等技术都是文字 3D 模型生成赛道上的前辈。如今 OpenAI 的入局,又会为这一赛道带来怎样的新风呢?
专注高效的 Point-E:竹杖芒鞋轻胜马
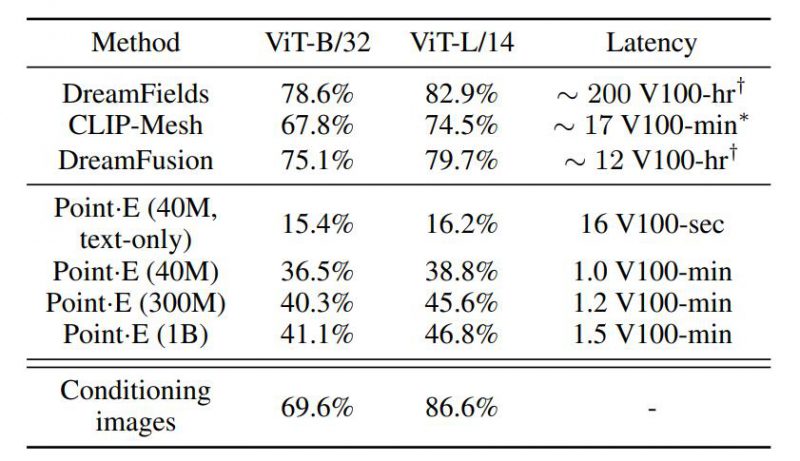
但正如 OpenAI 在此次的论文中所指出的,市面上的文字生成 3D 方法无一例外都有生成速度缓慢的缺点,生成单个 3D 模型的耗时常须以小时记。而 OpenAI 所打出的差异化口号便是一个字:快!OpenAI 声称,利用单张显卡,Point-E 仅需几秒到几分钟就能产出一个 3D 模型。英伟达的 AI 科学家 Jim Fan 在推特上表示,POINT-E 的生成速度约能达到 DreamFusion 的 600 倍。而 POINT-E 中的字母E所代表的正是效率(Efficiency)。
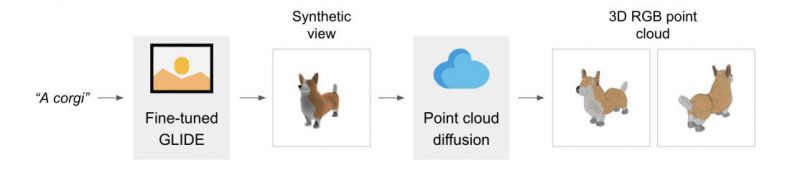
实现这一成果的方法是“剑走偏锋”。OpenAI 的科学家结合文字生成图片和图片生成 3D 两类模型,提出了一类全新的 3D 生成方法。Point-E 所产出的并非为可供直接渲染的 3D 网格,而是 3D 点云(Point Cloud)。
而在具体操作上,Point-E 会利用三十亿大模型 GLIDE 将文字指令转化为一张”预览图“(Synthetic View),相当于利用文字生成图片技术为 AI 提供一张 2D 的参考范例。随后在该预览图的指导下,利用扩散模型生成一个 1000 个像素点的 RGB 点云。最终,Point-E 以低分辨率的点云和预览图为条件,利用上采样(upsampling)技术将该点云进行进一步精细化,到达拥有 4000 个像素点的精度。
这一生成方式的缺点是十分明显。首先,OpenAI 就在论文中承认,利用该方法生成的模型精细度不高。GameLook 试玩了 OpenAI 放出的试用 demo。这个 demo 所运行的是 Point-E 的弱化版本——但即便将这一点纳入考量,最终的生成产物还是过分抽象了。
下图是 Point-E 绘制的救护车,我们可以从大体上看出轮廓。

输入文字指令”An Ambulance“生成的救护车点云模型
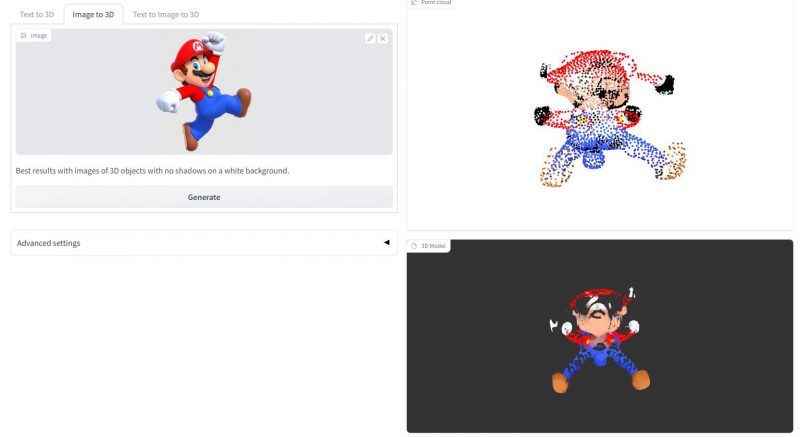
这张则是利用”图片转 3D“功能,在上传经典角色超级马力欧概念图后生成的点云和网格化模型——老任法务部看了直呼束手无策。
此外,OpenAI 还表示,系统在解析预览图时可能会误解物体的实际比例,导致生成的点云模型比例失调。使用该方法生成的点云还需进一步网格化才可投入使用,这也是潜在的缺陷之一。
但另一方面,Point-E 在完成它所专注的目标——快速——方面,可是一点都不打折扣。论文的统计数据显示,在使用单张 V100 显卡的情况下,DreamFusion 等主流算法需要高达 12-200 小时的计算时长才能产出一个 3D 模型,但 Point-E 仅需1-1.5 分钟就可利用文字生成 3D 模型。提升产出效率两个数量级。GameLook 在试玩中发现,每张图片的生成时间通常仅为2-3 分钟。
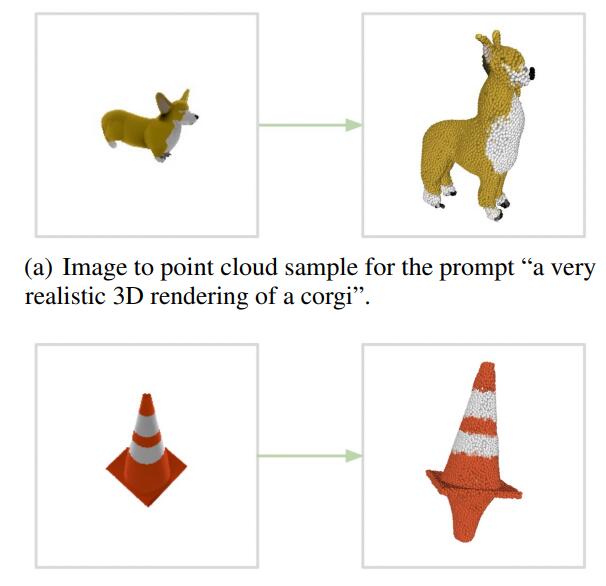
诚然,在这个阶段对 Point-E 的生成质量进行挑剔显然有些苛责,毕竟该技术和相关研究还明显处于早期,未经过多迭代——回望 DALLE 刚刚推出之时,也有不少人诟病其产出扭曲怪异。而在更标准的生产环境中,Point-E 的产出还是相当标致的。

此外,即便”元宇宙时代“人类对 3D 环境的观感十分注重,但高效的产出同样也是各大厂商决胜的关键。OpenAI 所采取的速度优化之道,同样也是启发未来的另一条重要思路。正如 OpenAI 在论文中所提的:”尽管生成效果相较最先进的算法并非最佳,但所使用的时间百不及一,这能够让应用场景变得更加可行……我们希望我们的论文能够抛砖引玉,启发文字合成 3D 模型领域的更多研究。“
业界热议:Point-E 到底有多大能量
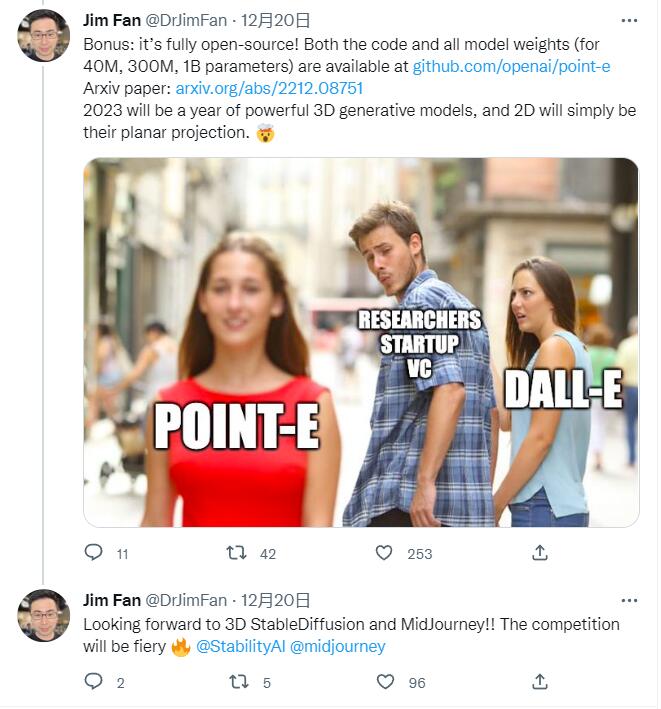
OpenAI 的这篇研究一经公布,立刻在各大 AI 观察者圈子中引发了热议。前文所提到的英伟达 AI 科学家 Jim Fan 博士在看到 Point-E 后激动地表示:”2023 年将会是强大的 AI 生成 3D 模型之年,而 2D 将会是他们的投影!“Jim Fan 表示,他十分期待看到 3D 版的 Stable Deffusion 和 Midjourney 上线,未来的市场竞争将会十分激烈。
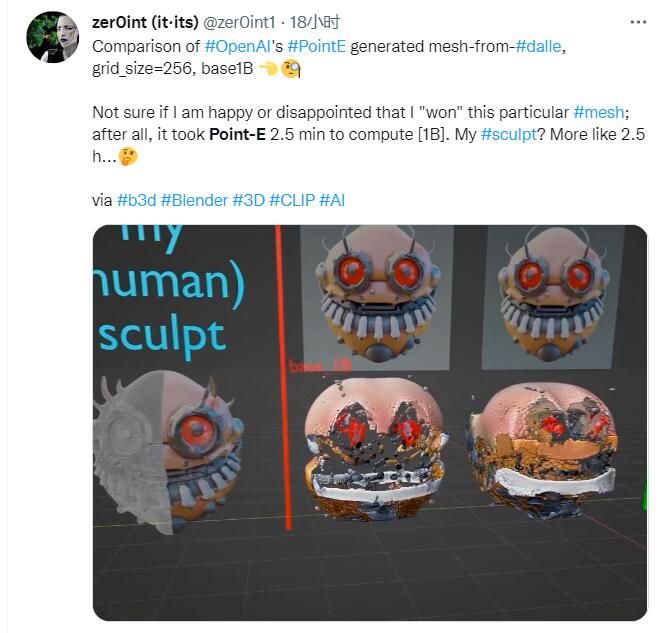
一名 3D 艺术家@zer0int1 在安装了”满血版“Point-E 后进行了一个小测试。他首先参考了一张原画并自己制作了一个 3D 模型,随后利用 Point-E 生成的模型网格化后进行了对比。他表示:”虽然我‘赢了’这场对决,但我不知道我应该感到高兴还是失望,毕竟我花了两个半小时才建好这个模型,但 AI 只花了两分半!“
在 GameLook 所浏览的各大论坛中,不少技术开发背景的程序员、艺术家等都对这项技术表现出了浓厚的兴趣,并前去体验了 Point-E 的 demo 版本。在 Reddit 的r/StableDeffusion 板块,更是有网友高呼神迹:”等到 2030 年 OpenAI 还会干出些啥?我 2022 年的原始人脑袋已经完全想象不出来了。“
不过,与此同时也有一部分声音对 Point-E 提出了质疑,其诟病的点主要在于较低的生成精度和较低的实用度。但正如前文所说,这并非 OpenAI 的实验所要达成的目的。
我们离 AI 真正加入人类创作还有多久?看似近在眼前,但也似乎遥不可及。一方面,以 GPT-3 为代表的 AI 文字生成技术和 Midjourney 等代表的 AI 图片生成技术,似乎已经能够产出让人满意的结果了,且迭代速度之快超出了我们想象。但另一方面,AI 作品在连贯性、可读性上依然无法与人类相提并论,Point-E 的产出也显然还达不到商用效果,更不用提 AI 训练中所包含的版权保护等新时代法律问题了。
而随着相关产品的日渐增多,AIGC 领域的竞争日益升高是我们所乐见的结果。只有通过不断地迭代,我们才可能在技术的碰撞之中不断突破技术的边界。GameLook 有信心,AIGC 一定会在不久的将来以更圆滑的形态与我们的内容生产融为一体。






