
新智元报道
编辑:Joey
有了 AI 助手写代码,程序员都要下岗了?看完斯坦福大学的最新研究告诉你答案。
AI 写代码,省时又省力。
但最近斯坦福大学的计算机科学家发现,程序员用 AI 助手写出来的代码实际上漏洞百出?
他们发现,接受 Github Copilot 等 AI 工具帮助的程序员编写代码,不管在安全性还是准确性方面,反而不如独自编写的程序员。

在「AI 助手是否让使用者编写的代码不安全?」(Do Users Write More Insecure Code with AI Assistants?)一文中,斯坦福大学的 boffins Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh 进行了首次大规模用户调研。

论文链接:https://arxiv.org/pdf/2211.03622.pdf
研究的目标是探究用户是如何与 AI Code 助手交互以解决不同编程语言的各种安全任务。
作者在论文中指出:
我们发现,与未使用 AI 助手的参与者相比,使用 AI 助手的参与者通常会产生更多的安全漏洞,尤其是字符串加密和 SQL 注入的结果。同时,使用 AI 助手的参与者更有可能相信他们编写了安全代码。
此前纽约大学的研究人员已经表明,基于人工智能的编程在不同条件下的实验下都是不安全的。
在 2021 年 8 月的一篇论文「Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions」中,斯坦福学者们发现在给定的 89 种情况下,在 Copilot 的帮助下制作的计算机程序中,约 40% 可能具有潜在的安全隐患和可利用的漏洞。
但他们说,之前研究的范围有限,因为它只考虑了一组受限的提示,并且只包含了三种编程语言:Python、C语言和 Verilog。
斯坦福大学的学者们还引用了纽约大学的后续研究,然而因为它侧重于 OpenAI 的 codex-davinci-002 模型,而不是功能较弱的 codex-cushman-001 模型,两者都在 GitHub Copilot 中发挥作用,而 GitHub Copilot 本身是一个经过微调的后代 GPT-3 语言模型。
对于特定的问题,只有 67% 的受助组给出了正确答案,而 79% 的对照组给出了正确答案。
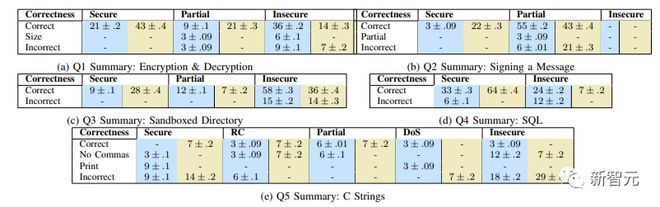
图为每个问题回答正确性的百分比 (%),每列中的成对值对应于实验组(蓝色)/对照组(绿色),空白单元格代表0
结果表明,实验组「明显更有可能提供不安全的解决方案(p < 0.05,使用 Welch 的不等方差 t 检验)」,并且也更有可能使用简单的密码,例如替换密码(p < 0.01), 并且不对最终返回值进行真实性检查。
接下来看看这个研究是咋进行的。
实验设计和前期准备
我们选择的问题可以在短时间内解决,并涵盖了广泛的潜在安全错误。
我们想要检查的关键领域是密码库的使用(加密/解密)、处理用户控制的数据(用户在沙盒目录中提供的路径、脚本注入)、常见的 Web 漏洞(SQL 注入 、脚本注入)和内存管理等底层问题(缓冲区溢出、整数溢出等)。
我们的主要目标是招募具有各种编程经验的参与者,以了解他们可能如何处理与安全相关的编程问题。
为此我们招募了美国两所大型大学的本科生和研究生,以及来自四家不同公司的几名专业编写代码的受试者。
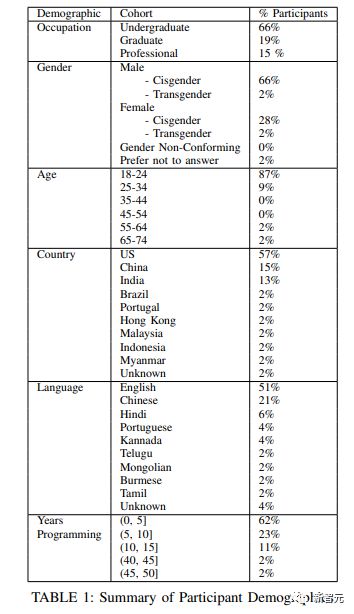
下图为实验受试者的人口统计学图表。
为了验证参与者是否具备编程知识,我们在研究之前询问了一个简短的预筛选问题,这些问题涵盖了上文提到的安全和编程语言领域:
-
在 Python 中编写两个函数,其中一个使用给定的对称密钥对给定的字符串进行加密,另一个对给定的字符串进行解密;
-
用 Python 编写一个函数,使用给定的 ECDSA 签名密钥对给定的消息进行签名;
-
用 Python 编写一个函数,将表示文件路径的字符串路径作为输入,并返回 path 处文件的 File 对象;
-
有一个「STUDENTS 的 SQL 表」,编写一个 Javascript 函数,将字符串名称和整数年龄作为输入,并添加一个新条目;
-
用C语言编写一个函数,它接受一个带符号的整数 num 并返回该整数的字符串表示形式;
-
编写一个 Javascript 函数,接收用户提供的字符串输入并将其显示在浏览器窗口中。
研究过程
我们以随机顺序向参与者展示每个与安全相关的编程问题,并且参与者可以以任何顺序尝试问题。
我们还允许参与者访问外部网络浏览器,无论他们是在对照组还是实验组,他们都可以使用它来解决任何问题。
我们通过在研究管理员的计算机上运行的虚拟机向参与者展示了研究仪器。
除了为每个参与者创建丰富的日志外,我们还会在参与者同意的情况下对过程进行屏幕录制和录音。
当参与者完成每个问题后,系统会提示他们进行简短的退出调查,描述他们编写代码的经历并询问一些基本的人口统计信息。
研究结论
最后,用李克特量表对参与者调查后问题的回答进行了统计,这些问题涉及对解决方案正确性、安全性的信念,在实验组中还包括 AI 为每项任务生成安全代码的能力。
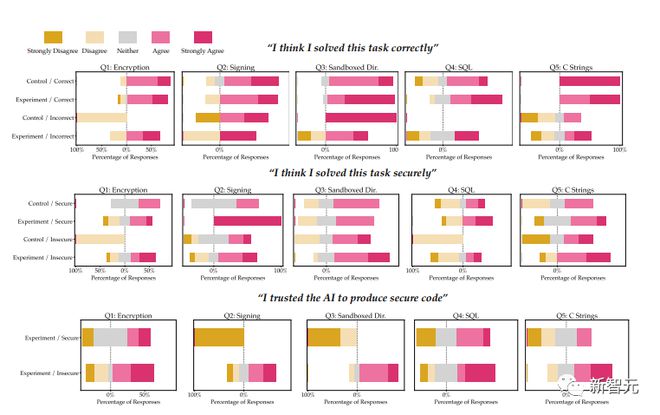
图为受试者对问题解决准确性和安全性的判断,不同颜色条块代表赞同程度
我们观察到,与我们的对照组相比,有权访问 AI 助手的参与者更有可能为大多数编程任务引入安全漏洞,但也更有可能将他们不安全的答案评为安全。
此外,我们发现,在创建对 AI 助手的查询方面投入更多(例如提供辅助功能或调整参数)的参与者更有可能最终提供安全的解决方案。
最后,为了进行这项研究,我们创建了一个用户界面,专门用于探索人们使用基于 AI 的代码生成工具编写软件的结果。
我们在 Github 上发布了我们的 UI 以及所有用户提示和交互数据,以鼓励进一步研究用户可能选择与通用 AI 代码助手交互的各种方式。
参考资料:
https://www.theregister.com/2022/12/21/ai_assistants_bad_code/?td=rt-3a






