
新智元报道
编辑:艾伦
【新智元导读】DeepMind 的 AlphaProof 在 IMO 拿到接近金牌的银牌成绩。它结合大模型直觉、强化学习和 Lean 形式化证明,攻克多道高难题。它虽在速度、泛化和读题上仍有限,但已开启人类数学家与 AI 协作的新阶段。
每年夏天,来自全球的青年数学天才汇聚一堂,参加被誉为「数学世界杯」的国际数学奥林匹克竞赛(IMO)。
比赛 6 道题分两天完成,每题满分 7 分,总分 42 分,难度极高,往往只有不到1% 的参赛者能全对所有题目。
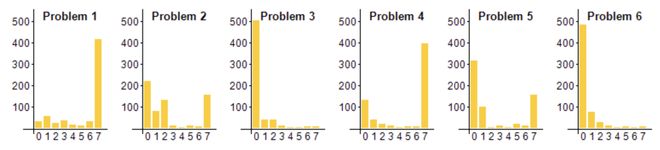
横轴为分数(7 分满),纵轴为人数
近年来,IMO 也被视为 AI 领域的终极挑战之一,是测试 AI 高级数学推理能力的理想舞台。
2024 年,谷歌 DeepMind 团队让一位特殊的「选手」参与了 IMO 角逐——一个名为 AlphaProof 的 AI 系统。
它取得了 28 分的高分,仅以 1 分之差无缘金牌,达到了银牌水平。
这是有史以来 AI 系统首次在 IMO 这样的顶级赛事中获得相当于奖牌的成绩,标志着机器在数学难题上的攻关能力迈上新台阶。
AlphaProof:数学解题 AI 高手登场
AlphaProof 是 DeepMind 最新研发的「数学解题 AI」系统,专门为证明复杂数学命题而设计。
简单来说,如果把数学题视作需要攻克的「迷宫」,AlphaProof 就是一个自学成才的 AI 解题高手。
不同于我们常见的 ChatGPT 这类纯粹用自然语言「思考」的模型,AlphaProof 走了一条独特的道路:它在计算机可验证的形式化语言中进行推理,从而确保每一步推导都严格正确,不会出现凭空捏造的「灵光一闪」却实则谬误的步骤。
AlphaProof 使用了数学领域流行的形式化证明语言 Lean 来书写证明。

Lean 语言示例
Lean 的语法接近数学和编程语言的结合体,允许 AI 输出的每一步推理都被自动检查验证,避免了常规语言模型可能出现的谬误。
AlphaProof 给出的答案不是靠人类评审的文字解释,而是一份计算机逐行检验通过的严谨证明。
这种将 AI 思维「硬化」成机械可核查形式的方式,让 AlphaProof 在解答再难的题目时也没有半点侥幸成分。
技术秘诀:大模型牵手强化学习
AlphaProof 成功的核心秘诀在于将预训练大语言模型的「聪明直觉」和 AlphaZero 强化学习算法的「勤学苦练」巧妙结合。
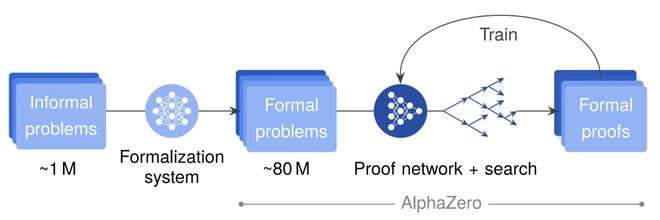
语言模型擅长从海量数据中学习人类解题的经验和模式;
而强化学习则让 AI 通过不断尝试错误,不断改进策略,正如小孩反复练习最终学会骑自行车。
DeepMind 团队先利用大模型为 AlphaProof 打下「学识」基础,然后让它在模拟的数学环境中反复练习,自己发现解题策略。
研究者首先收集了近一百万道数学题(涵盖不同领域和难度),利用谷歌最新的 Gemini 将这些自然语言描述的题目自动翻译成形式化的 Lean 代码表述。
这一过程相当于为 AlphaProof 打造了一个规模空前的题库——团队共获得了约 8000 万条形式化的数学命题,可以让 AI 来练习证明。
有了这个「题海」后,AlphaProof 先经过监督学习微调,掌握基本的 Lean 语言证明技巧。
接着,它进入强化学习阶段:像 AlphaGo 下棋自我对弈一样,AlphaProof 在 Lean 证明环境中与自己切磋。
每当 AlphaProof 找到一道题的正确证明并通过验证,就用这一成功案例来立即强化自身的模型参数,使它下次能更有效地解决更有难度的新问题。
这种边练边学的训练循环持续进行,AlphaProof 在数以百万计的问题证明中不断进步,逐渐掌握高难度问题所需的关键技能。
AlphaProof 在搜索证明的时候并非毫无头绪地「暴力穷举」。
它采用了类似于棋类 AI 中蒙特卡罗树搜索的策略,会智能地将复杂问题拆解成若干子目标各个击破,并灵活调整搜索方向。
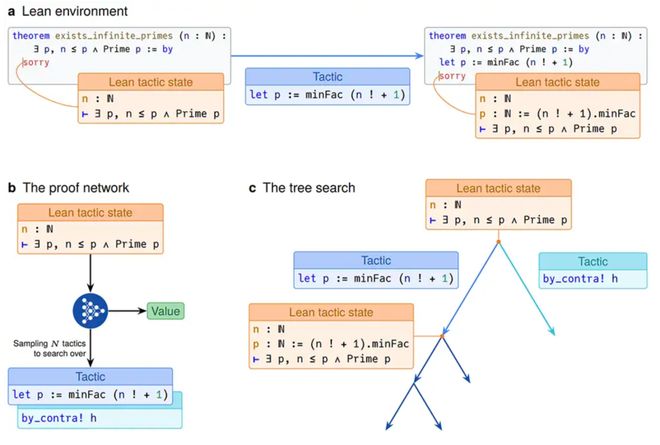
在某些情况下,AlphaProof 能在看似无限的可能推导中迈出恰到好处的一步,展现出仿佛人类数学家般的「灵光一闪」。
这既归功于大模型提供的直觉指导,也离不开强化学习反复探索带来的全面搜索能力——两者结合,使得 AlphaProof 比以往的任何 AI 系统都更善于在复杂的数学迷宫中找到出路。
奥赛夺银:AI 解题里程碑
DeepMind 的 AlphaProof 与 AlphaGeometry 2 联手在 2024 年 IMO 的 6 道竞赛题中解出了 4 道,获得了 28 分(满分 42 分),达到了银牌选手的成绩。
这一得分距离当年金牌线仅差一分(29 分),几乎触及金牌门槛。
在解出的题目中,AlphaProof 单独解决了其中 3 题(包括 2 道代数题和 1 道数论题),其中就包括了整场比赛最难的第 6 题——该题在 600 多名顶尖学生中也只有 5 人满分解决。
剩余的一道几何题则由专攻几何的 AlphaGeometry 2 模型完成,而两道组合数学题由于难以形式化和搜索爆炸等原因未能攻克。
最终,这套 AI 系统拿下 4 题满分(其余 2 题为 0 分),分数正好处于银牌段的顶端。
要知道,在人类选手中也只有不到 10% 的人能拿到金牌,今年共有 58 名选手得分不低于 29 分。
AlphaProof 取得的银牌水平成绩,足以比肩一位受过多年训练的国际顶尖高中生天才选手。
这一成果令许多专家感到震撼:著名数学家、菲尔兹奖得主高尔斯评价说,AlphaProof 给出的某些巧妙构造「远超出我以为 AI 目前能够做到的水平」。

AlphaProof 在 IMO 上的表现具有里程碑意义。
这是 AI 首次在如此高难度的数学竞赛中达到人类奖牌选手的水准,表明 AI 的数学推理能力实现了重大飞跃。
过去,大模型即便掌握了海量教材和定理,也常常难以完整解决奥赛级别的挑战,更不用说给出严格证明。
而 AlphaProof 通过形式化证明和强化学习,真正让 AI 具备了解决开放性数学难题的实力。
它成功证明了 IMO 中最困难题目的事实也让人看到了希望:或许将来 AI 有潜力辅助人类攻克悬而未决的数学猜想。
局限与未来
AI 数学家的进阶之路
尽管 AlphaProof 令人眼前一亮,但目前它仍有不少局限。
其一,解题效率是个问题。
人类选手必须在 4.5 小时内完成 3 题,而 AlphaProof 虽然最后找出了 3 题的解法,却耗费了将近 3 天时间。
这表明当前 AI 证明方法在搜索速度和计算资源上还有很大提升空间。
其二,AlphaProof 并非万能,它未能解决的两道组合数学题恰恰反映了某些类型的问题对 AI 而言依然棘手。
这类题目往往涉及高度非结构化的创新思维,超出了 AlphaProof 主要从训练中「见过」的范畴。
因此,如何让 AI 拥有更强的通用性和适应性,去应对未曾遇见的新颖难题,是下一步的重要挑战。
其三,目前 AlphaProof 需要人工先将题目翻译成 Lean 的形式化表达,它自己并不理解自然语言问题。
这意味着它无法自主读题,也无法像人类数学家那样提出新的问题或判断哪些问题值得研究。
正如伦敦数学科学研究所的何杨辉所指出的,AlphaProof 可以作为协助数学家证明的有力工具,但它还不能替代人类去发现和选择研究课题。

何杨辉
面对这些局限,DeepMind 团队表示他们将继续探索多种途径来提升 AI 的数学推理能力。
未来的研发方向之一是让 AI 摆脱对人工翻译的依赖,直接阅读理解自然语言表述的数学题,并给出形式化证明。
同时,针对不同类别的数学问题(如组合数学或几何),可能需要引入更专业的策略,比如融合符号计算、知识库或分领域训练的模型,从而全面提高 AI 的解题覆盖面。
还有研究者设想,将来数学家可以与这样的 AI 证明助手协同工作:
AI 快速验证人类猜想和小引理,甚至尝试大胆的思路攻克长期悬而未决的难题;
人类则专注于提出有意义的问题和整体证明构想。
可以预见,随着 AlphaProof 这类系统的不断完善,我们正迎来人机携手探寻数学前沿的新纪元。
AlphaProof 展现出的形式化推理能力对 AI 安全和可靠性也有启发意义。
它输出的每一步推理都可追溯、验证,这种「严谨求证」的风格或许可用于改进未来的大模型,让它们在回答开放性问题时减少荒诞的臆测。
当 AI 变得越来越强大,我们更希望它是一个踏实严谨的「数学家」。
经过此次奥赛洗礼,AlphaProof 让我们看到了 AI 在纯粹理性领域逼近人类顶尖水平的曙光。
当然,人类顶尖数学家的创造力和洞察力依然不可替代——至少在提出问题和宏观思路上,AI 还有很长的路要走。
但毫无疑问,AI 正在成为人类探索数学未知的一双有力之手。
无论人类或 AI,攀登真理高峰的道路上,永远需要勇气、耐心与对未知的敬畏。
参考资料:
https://www.nature.com/articles/s41586-025-09833-y
https://www.julian.ac/blog/2025/11/13/alphaproof-paper/






